Wetenschap
De algoritmen van Facebook zorgden voor massale buitenlandse propagandacampagnes tijdens de verkiezingen van 2020
Krediet:het gesprek
Uit een intern Facebook-rapport bleek dat de algoritmen van het socialemediaplatform - de regels die de computers volgen bij het bepalen van de inhoud die je ziet - desinformatiecampagnes in Oost-Europa mogelijk maakten om bijna de helft van alle Amerikanen te bereiken in de aanloop naar de presidentsverkiezingen van 2020, volgens een rapport in Technology Review.
De campagnes produceerden de meest populaire pagina's voor christelijke en zwart-Amerikaanse inhoud, en bereikte in totaal 140 miljoen Amerikaanse gebruikers per maand. Vijfenzeventig procent van de mensen die aan de inhoud werden blootgesteld, had geen van de pagina's gevolgd. Mensen zagen de inhoud omdat het inhoudsaanbevelingssysteem van Facebook het in hun nieuwsfeeds plaatste.
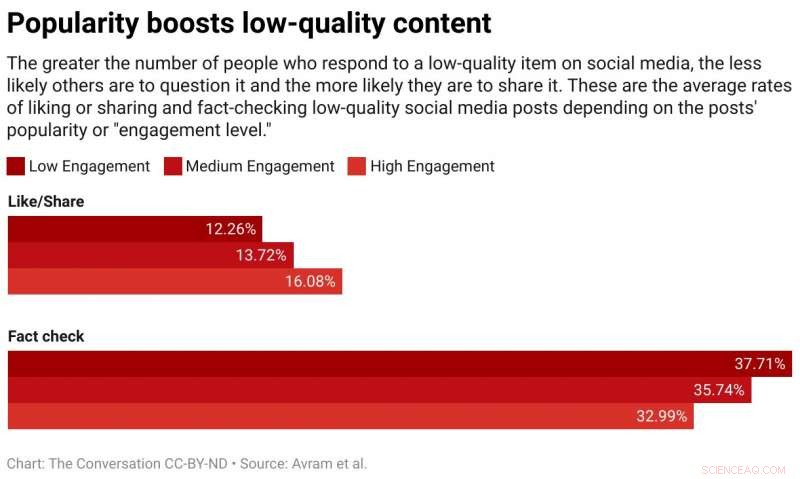
Social-mediaplatforms zijn sterk afhankelijk van het gedrag van mensen om te beslissen over de inhoud die u ziet. Vooral, ze kijken naar inhoud waarop mensen reageren of 'aangaan' door ze leuk te vinden, commentaar geven en delen. Trollenboerderijen, organisaties die provocerende inhoud verspreiden, misbruik dit door inhoud met een hoge betrokkenheid te kopiëren en deze als hun eigen inhoud te posten.
Als computerwetenschapper die de manieren bestudeert waarop grote aantallen mensen met technologie omgaan, Ik begrijp de logica van het gebruik van de wijsheid van de menigte in deze algoritmen. Ik zie ook flinke valkuilen in hoe de social media bedrijven dat in de praktijk doen.
Aan de vooravond van de verkiezingen van 2020, trollenboerderijen hadden grote paginanetwerken op FB gericht op Christian, zwart, &Indianen. Een intern rapport waarin de situatie werd beschreven, beschreef het als "echt gruwelijk". Sommige pagina's blijven twee jaar later. https://t.co/Wa43f8rG0N
— Karen Hao (@_KarenHao) 17 september 2021
Van leeuwen op de savanne tot likes op Facebook
Het concept van de wijsheid van menigten gaat ervan uit dat het gebruik van signalen van andermans acties, meningen en voorkeuren als leidraad zullen leiden tot goede beslissingen. Bijvoorbeeld, collectieve voorspellingen zijn normaal gesproken nauwkeuriger dan individuele. Collectieve intelligentie wordt gebruikt om financiële markten te voorspellen, sport, verkiezingen en zelfs uitbraken van ziekten.
Gedurende miljoenen jaren van evolutie, deze principes zijn in het menselijk brein gecodeerd in de vorm van cognitieve vooroordelen die gepaard gaan met namen als vertrouwdheid, louter blootstelling en bandwagon-effect. Als iedereen begint te rennen, je zou ook moeten beginnen met rennen; misschien heeft iemand een leeuw zien komen en rennen die je leven kan redden. Je weet misschien niet waarom, maar het is verstandiger om later vragen te stellen.
Je brein pikt aanwijzingen op uit de omgeving, inclusief die van je leeftijdsgenoten, en gebruikt eenvoudige regels om die signalen snel om te zetten in beslissingen:Ga met de winnaar, volg de meerderheid, kopieer je buurman. Deze regels werken opmerkelijk goed in typische situaties omdat ze gebaseerd zijn op goede aannames. Bijvoorbeeld, ze gaan ervan uit dat mensen vaak rationeel handelen, het is onwaarschijnlijk dat velen het bij het verkeerde eind hebben, het verleden voorspelt de toekomst, enzovoort.
Technologie geeft mensen toegang tot signalen van veel grotere aantallen andere mensen, waarvan de meesten ze niet kennen. Toepassingen op het gebied van kunstmatige intelligentie maken veelvuldig gebruik van deze populariteits- of "betrokkenheids"-signalen, van het selecteren van zoekresultaten tot het aanbevelen van muziek en video's, en van het voorstellen van vrienden tot het rangschikken van berichten op nieuwsfeeds.
Niet alles wat viraal is verdient het om te zijn
Uit ons onderzoek blijkt dat vrijwel alle webtechnologieplatforms, zoals sociale media en nieuwsaanbevelingssystemen, een sterke populariteitsbias hebben. Wanneer applicaties worden aangedreven door signalen zoals betrokkenheid in plaats van expliciete zoekopdrachten van zoekmachines, populariteitsbias kan leiden tot schadelijke onbedoelde gevolgen.
Sociale media zoals Facebook, Instagram, Twitter, YouTube en TikTok zijn sterk afhankelijk van AI-algoritmen om inhoud te rangschikken en aan te bevelen. Deze algoritmen nemen als invoer wat je wilt, commentaar geven op en delen - met andere woorden, inhoud waarmee u zich bezighoudt. Het doel van de algoritmen is om de betrokkenheid te maximaliseren door erachter te komen wat mensen leuk vinden en dit bovenaan hun feeds te plaatsen.
Op het eerste gezicht lijkt dit redelijk. Als mensen van geloofwaardig nieuws houden, meningen van experts en leuke video's, deze algoritmen zouden dergelijke inhoud van hoge kwaliteit moeten identificeren. Maar de wijsheid van de menigte maakt hier een belangrijke veronderstelling:dat het aanbevelen van wat populair is, zal helpen bij het 'opborrelen' van inhoud van hoge kwaliteit.
We hebben deze veronderstelling getest door een algoritme te bestuderen dat items rangschikt met een mix van kwaliteit en populariteit. We vonden dat in het algemeen populariteitsbias heeft meer kans om de algehele kwaliteit van inhoud te verlagen. De reden is dat betrokkenheid geen betrouwbare indicator voor kwaliteit is als er maar weinig mensen zijn blootgesteld aan een item. In deze gevallen, betrokkenheid genereert een signaal met ruis, en het algoritme zal deze initiële ruis waarschijnlijk versterken. Zodra de populariteit van een item van lage kwaliteit groot genoeg is, het zal steeds versterkt worden.
Algoritmen zijn niet het enige dat wordt beïnvloed door betrokkenheidsbias, het kan ook van invloed zijn op mensen. Er zijn aanwijzingen dat informatie wordt overgedragen via "complexe besmetting, " wat betekent dat hoe vaker mensen online worden blootgesteld aan een idee, hoe groter de kans dat ze het overnemen en opnieuw delen. Wanneer sociale media mensen vertellen dat een item viraal gaat, hun cognitieve vooroordelen treden in werking en vertalen zich in de onweerstaanbare drang om er aandacht aan te schenken en het te delen.
Niet-zo-wijs publiek
We hebben onlangs een experiment uitgevoerd met een app voor nieuwsgeletterdheid genaamd Fakey. Het is een spel ontwikkeld door ons lab, die een nieuwsfeed simuleert zoals die van Facebook en Twitter. Spelers zien een mix van actuele artikelen van nepnieuws, junk wetenschap, partijdige en samenzweerderige bronnen, evenals mainstream bronnen. Ze krijgen punten voor het delen of leuk vinden van nieuws uit betrouwbare bronnen en voor het markeren van artikelen met een lage geloofwaardigheid voor feitencontrole.
We ontdekten dat spelers artikelen vaker leuk vinden of delen en minder geneigd zijn om artikelen uit bronnen met een lage geloofwaardigheid te markeren als spelers kunnen zien dat veel andere gebruikers zich met die artikelen hebben beziggehouden. Blootstelling aan de engagementstatistieken creëert dus een kwetsbaarheid.
De wijsheid van de menigte faalt omdat ze is gebaseerd op de valse veronderstelling dat de menigte bestaat uit verschillende, onafhankelijke bronnen. Er kunnen verschillende redenen zijn dat dit niet het geval is.
Eerst, vanwege de neiging van mensen om met soortgelijke mensen om te gaan, hun online buurten zijn niet erg divers. Het gemak waarmee gebruikers van sociale media de vriendschap met degenen met wie ze het niet eens zijn, kunnen ontvrienden, duwt mensen in homogene gemeenschappen, vaak aangeduid als echokamers.
Tweede, omdat de vrienden van veel mensen vrienden van elkaar zijn, ze beïnvloeden elkaar. Een beroemd experiment toonde aan dat weten welke muziek je vrienden leuk vinden, invloed heeft op je eigen uitgesproken voorkeuren. Je sociale verlangen om te conformeren verstoort je onafhankelijke oordeel.
Derde, populariteitssignalen kunnen worden gespeeld. Door de jaren heen, zoekmachines hebben geavanceerde technieken ontwikkeld om zogenaamde "linkfarms" en andere schema's om zoekalgoritmen te manipuleren, tegen te gaan. Sociale mediaplatforms, anderzijds, beginnen net te leren over hun eigen kwetsbaarheden.
Mensen die de informatiemarkt willen manipuleren, hebben nepaccounts aangemaakt, zoals trollen en sociale bots, en georganiseerde nep-netwerken. Ze hebben het netwerk overspoeld om de schijn te wekken dat een complottheorie of een politieke kandidaat populair is, zowel platformalgoritmen als de cognitieve vooroordelen van mensen tegelijk bedriegen. Ze hebben zelfs de structuur van sociale netwerken veranderd om illusies te creëren over de mening van de meerderheid.
Betrokkenheid terugbellen
Wat te doen? Technologieplatforms zijn momenteel in het defensief. Ze worden agressiever tijdens verkiezingen in het verwijderen van nepaccounts en schadelijke desinformatie. Maar deze inspanningen kunnen lijken op een spel van mep.
Een andere, preventieve aanpak zou zijn om wrijving toe te voegen. Met andere woorden, om het proces van informatieverspreiding te vertragen. Hoogfrequent gedrag, zoals automatisch leuk vinden en delen, kan worden geremd door CAPTCHA-tests of vergoedingen. Dit zou niet alleen de mogelijkheden voor manipulatie verminderen, maar met minder informatie zouden mensen meer aandacht kunnen besteden aan wat ze zien. Het zou minder ruimte laten voor betrokkenheidsbias om de beslissingen van mensen te beïnvloeden.
Het zou ook helpen als sociale-mediabedrijven hun algoritmen zouden aanpassen om minder afhankelijk te zijn van betrokkenheid bij het bepalen van de inhoud die ze u aanbieden. Misschien zullen de onthullingen van Facebook's kennis van trollenboerderijen die gebruik maken van betrokkenheid de nodige impuls geven.
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 
 Het beheersen van de nanoschaalstructuur van membranen is essentieel voor schoon water, onderzoekers vinden
Het beheersen van de nanoschaalstructuur van membranen is essentieel voor schoon water, onderzoekers vinden- Video:Hoe chemie de warme chocolademelk kan verbeteren
- Onderzoeksteam ontwikkelt goedkope, nauwkeurig COVID-19 antilichaamdetectieplatform
- Wetenschappers ontwikkelen metaalvrije fotokatalysator om pathogeenrijk water binnen enkele minuten te zuiveren
- Wetenschappers ontwikkelen eiwitten die zichzelf assembleren tot supramoleculaire complexen
- Kenmerken van champignons
- Indiase moessons zijn de afgelopen 15 jaar sterker geworden, studie toont
- Zijn alle boerderijen in de toekomst binnen?
- Noord-Atlantische Oceaan wordt minder zout, maar het is te vroeg om klimaatverandering de schuld te geven
- NASA kijkt naar regenval in tropische cycloon Yvette
Hoofdlijnen
- Vissen en schepen:het scheepvaartverkeer verkleint het communicatiebereik voor Atlantische kabeljauw, Schelvis
- Antibiotica kunnen het vermogen van immuuncellen om bacteriën te doden verminderen
- Functies van menselijke organen
- Verschillen tussen gisten en vormpjes
- Alles in de familie:gerichte genomische vergelijkingen
- Door bewijzen gesteunde manieren om gefocust te blijven wanneer u studeert
- Pizza-nachtmerries:kan uw dieet uw dromen bepalen?
- Hoe noteer ik een Karyotype
- Hoe te studeren voor menselijke biologie examens
- Studie identificeert ernstige economische impact van COVID-19 in Afrika

- Waarom discrimineren mensen sprekers met een buitenlands accent?

- Nieuwe dinosaurus ter grootte van een wallaby uit de oude Australisch-Antarctische kloofvallei

- Onderzoek:het verbieden van strafrechtelijke veroordelingen bij sollicitaties verhoogt de aanwerving van ex-gedetineerden

- Meer paars dan blauw:religieus niet-gelieerde verschillen in politieke overtuigingen


 Wetenschappers identificeren ontbrekende bron van atmosferisch carbonylsulfide
Wetenschappers identificeren ontbrekende bron van atmosferisch carbonylsulfide- pinMOS:nieuw geheugenapparaat kan optisch of elektrisch worden beschreven en uitgelezen
- Artistiek raadsel ontcijferd door kosmische Tsjechische start-up
- Er zijn geen leeftijdsbeperkingen voor gokken in videogames, ondanks mogelijke risico's voor kinderen
- Hoe speciale systemen in Algebra op te lossen
- Welke fundamentele wetgeving wordt in evenwichtsvergeli gingen aangetoond?
- Wat maakt een allel dominant, recessief of mede-dominant?
- Een gemakkelijkere manier om vegetarisch te worden:vitamine B12 kan worden geproduceerd tijdens deegfermentatie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
