Wetenschap
Wetenschappers verbeteren gerasterde neerslaggegevensset voor Tibetaans plateau
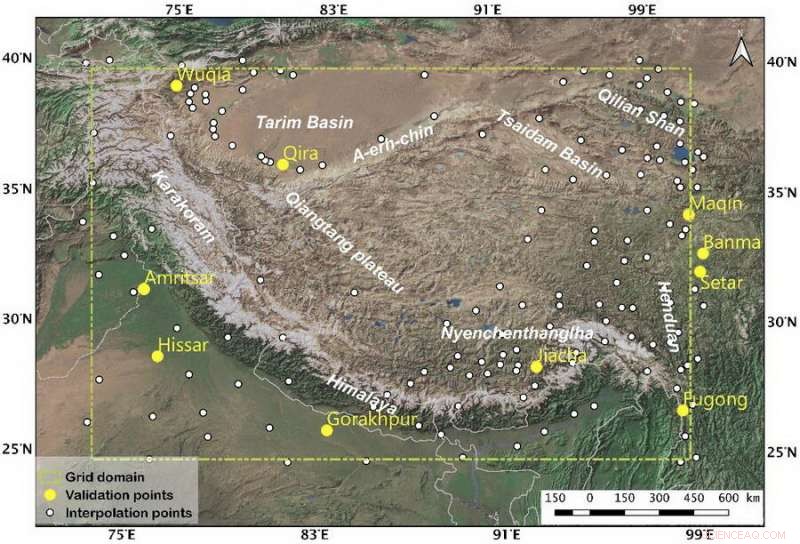
Fig. 1. Het studiegebied en de spreiding van waarnemingsplaatsen. De tien gele punten vertegenwoordigen de onafhankelijke sites die worden gebruikt voor de validatie van de frequentieverdeling, en de witte punten vertegenwoordigen de punten voor rastering. De gele gestippelde rechthoek is het interpolatiebereik. Krediet:LI Hongyi
Een nauwkeurige gerasterde neerslagdataset is essentieel voor een beter begrip van klimaatverandering, en hydrologische en ecologische processen op het Tibetaanse plateau. Echter, het neerslagobservatienetwerk in deze regio is schaars. De waargenomen neerslag is onderhevig aan complexe meteorologische en orografische omstandigheden, het beperken van de nauwkeurigheid van de gerasterde neerslagdataset. De verscheidenheid aan neerslaginstrumenten op het Tibetaanse plateau en de omliggende gebieden heeft ook de correctie van gemeten neerslag ernstig beïnvloed.
Door de neerslagondervangst van verschillende soorten instrumenten rond het Tibetaanse plateau te compenseren en de neerslagfrequentieverdeling in het interpolatieschema te optimaliseren, een onderzoeksteam van het Northwest Institute of Eco-Environment and Resources (NIEER) van de Chinese Academie van Wetenschappen (CAS) stelde een nieuwe neerslagdataset voor.
De dataset gebruikt de waargenomen neerslag van 159 stations als gegevensbron (Fig. 1) en corrigeert de ondervangst. Door vervolgens zes veelgebruikte interpolatieschema's te vergelijken met de neerslagfrequentiefout als evaluatiestandaard, het optimale interpolatieschema dat geschikt is voor het Tibetaanse plateau wordt verkregen.
In aanvulling, een set dagelijkse gerasterde neerslaggegevenssets met een ruimtelijke resolutie van 10 km vanaf 1 januari 1980 tot 31 december Op basis van die werken wordt 2009 verkregen.
De resultaten laten zien dat ondervangcorrectie nodig is voor stationsgegevens, die de verdelingsfout met maximaal 30% kan verminderen. Een interpolatie-algoritme voor dunne-plaatsplines waarbij hoogte als een covariabele wordt beschouwd, is nuttig om de statistische verdelingsfout in het algemeen te verminderen.
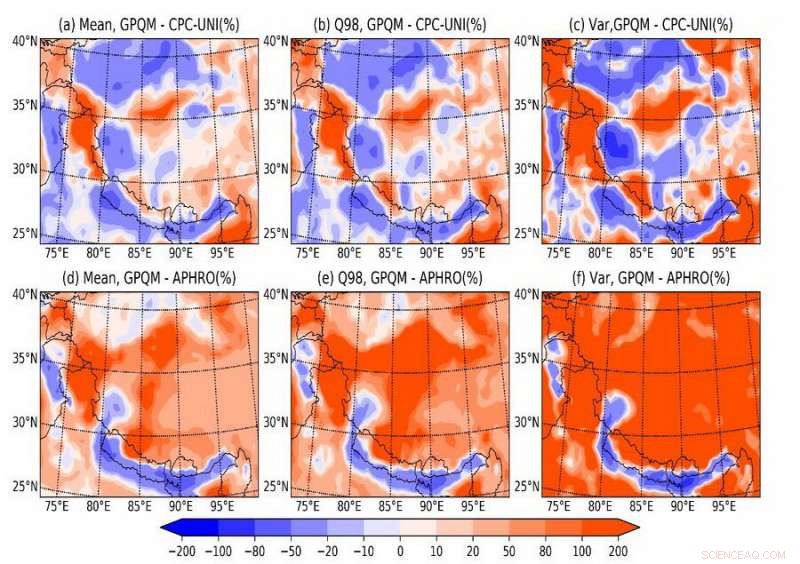
Fig. 2. Het verschil tussen de gecorrigeerde resultaten en de vorige dataset. Het gemiddelde is het dagelijkse gemiddelde, Q98 is het 98e percentiel, Var is de variantie en APHRO betekent de APHRODITE-dataset. Alle resultaten houden alleen rekening met natte dagen, die worden geclassificeerd door een drempel van 0,1 mm/d. De eerste kolom (a, d) toont het verschil in het daggemiddelde. De tweede kolom (b, e) toont het verschil in het dagelijkse 98e percentiel. De derde kolom (c, f) toont het verschil in de dagelijkse variantie. Krediet:LI Hongyi
Vergeleken met de bestaande gerasterde neerslagdataset, deze dataset heeft betere verdelingskarakteristieken van de neerslagfrequentie, een meer redelijke gemiddelde waarde, variantie, en een beter onderdrukkend afvlakkingseffect dat algemeen bestaat in de eerdere gerasterde neerslagproducten (figuur 2).
De resultaten bieden een relatief betrouwbare gerasterde neerslaggegevensset voor die hydrometeorologische studies op het Tibetaanse plateau.
De dataset is online gepubliceerd in een paper met de titel "Reducing the Statistical Distribution Error in Gridded Data for the Tibetan Plateau" in de Tijdschrift voor Hydrometeorologie .
 Cohesieonderzoekers ontrafelen het mysterie van waterstofeffecten op materialen
Cohesieonderzoekers ontrafelen het mysterie van waterstofeffecten op materialen- Nobelweek gaat door met Scheikundeprijs
- Nieuwe draai aan CRISPR-technologie
- Drugsbibliothecaris ontdekt nieuwe stof die veelvoorkomende chirurgische complicaties kan dwarsbomen
- Brandstofcellen met turbocompressor met een multifunctionele katalysator
Hoofdlijnen
- Kan de wetenschap verklaren waarom we zoenen met onze ogen dicht?
- Namen van de enzymen in de mond & slokdarm
- Hoe werkt ureum denaturisch?
- Wetenschappers ontdekken patronen van olifantenstroperij in Oost-Afrika
- Wat is het verschil tussen hardhout en zachthout?
- Wat is het verschil tussen erfelijke en milieudefecten?
- Hoe bloedzuigende insecten donkergecoat vee in het donker vinden
- Wanneer treedt melkzuurfermentatie op?
- Ontdekking:Bernie Sanders spin
- Groeiende stapel menselijk en dierlijk afval herbergt bedreigingen, mogelijkheden

- Opwarming van de aarde verandert het Great Barrier Reef

- Voor slachtoffers van orkanen, langdurige onderbreking van nutsvoorzieningen, beperkte voorbereiding leidt tot langere hersteltijden

- Meer vervuiling, minder regen

- Lijst van peulvruchten


 Sterke cycloon treft Oost-India, beïnvloedt Aziatisch subcontinent
Sterke cycloon treft Oost-India, beïnvloedt Aziatisch subcontinent- Dieptelading:atoomkrachtmicroscopie gebruiken om ondergrondse structuren te bestuderen
- Meta-oppervlakken die licht op kleine schaal manipuleren, kunnen worden gebruikt in consumententechnologie
- Decibelstijging converteren naar procent
- Duitsland meldt eerste daling van de uitstoot van broeikasgassen in vijf jaar
- Veganistisch is het nieuwe vegetarisch - waarom supermarkten plantaardig moeten gaan om de planeet te redden
- Wiskundige activiteiten voor de buiten klas
- Experiment en theorie komen eindelijk samen in debat over microbiële nanodraden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
