Wetenschap
Door het trainen van hersenprocessen wordt het lezen efficiënter
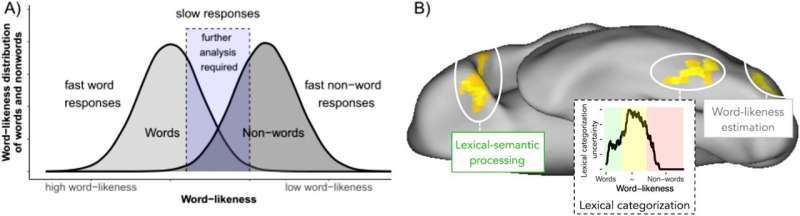
Een team van onderzoekers van de Universiteit van Keulen en de Universiteit van Würzburg heeft in trainingsstudies ontdekt dat het onderscheid tussen bekende en onbekende woorden kan worden getraind en tot efficiënter lezen leidt. Het herkennen van woorden is noodzakelijk om de betekenis van een tekst te begrijpen. Als we lezen, bewegen we onze ogen zeer efficiënt en snel van woord naar woord.
Deze leesstroom wordt onderbroken wanneer we een woord tegenkomen dat we niet kennen, een situatie die vaak voorkomt bij het leren van een nieuwe taal. Het kan zijn dat de woorden van de nieuwe taal nog niet in hun geheel kunnen worden begrepen, en taalspecifieke eigenaardigheden in de spelling moeten nog worden geïnternaliseerd. Het team van psychologen onder leiding van junior professor Dr. Benjamin Gagl van de Faculteit der Menswetenschappen van de Universiteit van Keulen heeft nu een methode gevonden om dit proces te optimaliseren.
De huidige onderzoeksresultaten zijn gepubliceerd in npj Science of Learning onder de titel "Onderzoek naar lexicale categorisatie bij het lezen op basis van gezamenlijke diagnostische en trainingsbenaderingen voor taalleerders." Vanaf mei zullen vervolgstudies worden uitgevoerd ter verlenging van het trainingsprogramma.
"Lezen is essentieel voor informatieverwerking", zegt hoofdauteur Benjamin Gagl, die al jaren de cognitieve en neurale processen van woordherkenning bestudeert. Twee jaar geleden toonden hij en een team van onderzoekers aan dat psychologische theorieën, in ons begrip van de processen die bij woordherkenning worden geïmplementeerd, geen voldoende nauwkeurige aannames doen over de exacte functies van een van de meest geactiveerde hersengebieden in de linker temporaalkwab.
Om deze kenniskloof te dichten, ontwikkelden Gagl en zijn collega's een model dat gevestigde gedragsmatige bevindingen uit de psychologie gebruikt om de activering van dit leesgebied in de hersenen te voorspellen; dit model dient als basis voor het trainingsprogramma dat in de nieuwe studie wordt beschreven.
Woordfilters als bouwsteen voor efficiënt lezen
Het model gaat ervan uit dat dit hersengebied als een filter functioneert en reeds bekende woorden scheidt van irrelevante of nog niet bekende lettercombinaties; alleen bekende woorden mogen 'doorgeven' om daaruit voortvloeiende taalkundige verwerking te initiëren. Wanneer we echter een nieuw woord tegenkomen, kunnen we niet verder lezen, maar moeten we het woord opzoeken in een lexicon of op internet om de betekenis ervan te begrijpen.
De trainingsprocedures die centraal staan in het huidige onderzoek werden gemotiveerd door de aannames van het ‘Lexical Categorization Model’. Gedragsstudies hebben aangetoond dat de leesvaardigheid verbeterde als deelnemers werden getraind in dit filterproces dat essentieel is voor efficiënt lezen. De trainingsprocedure omvatte eenvoudige taken waarbij lezers woorden van niet-woorden moesten onderscheiden (bijvoorbeeld pad vs. poth) door op een knop te drukken.
Na drie trainingsdagen verbeterden de leesprestaties substantieel in drie afzonderlijke onderzoeken. Het team gebruikte ook een op machine learning gebaseerde diagnostische procedure die de efficiëntie van de training kan verhogen, omdat het deelnemers kan detecteren die waarschijnlijk geen baat zouden hebben bij verdere training. Hierdoor kan voor elke leerling individueel worden besloten of de training in lexicale categorisatie de moeite waard is of dat er in plaats daarvan een alternatieve training moet worden gegeven.
Nieuwe manieren om leesproblemen te compenseren
Als onderdeel van een nieuw verworven project dat op 1 mei start, zullen de onderzoekers de computermodellen verder ontwikkelen, wat nieuwe trainingsbenaderingen voor het leren van talen of voor de compensatie van andere leesstoornissen zal motiveren. Naast het vakgebied Duits als vreemde taal kunnen de trainingsbenaderingen potentieel worden gebruikt bij de behandeling van dyslexie.
"Neuro-cognitieve computermodellen kunnen worden gebruikt om fundamentele wetenschappelijke bevindingen te implementeren die kunnen worden gebruikt in individuele diagnostische trainingsprogramma's in educatieve en klinische omgevingen. Dit stelt ons in staat individuele leerlingen te helpen hun leesvaardigheid te optimaliseren en zo hun informatieverwerkingsvaardigheden aanzienlijk te verbeteren," zei Gagl.