Wetenschap
Computationele wetenschappers genereren moleculaire datasets op extreme schaal
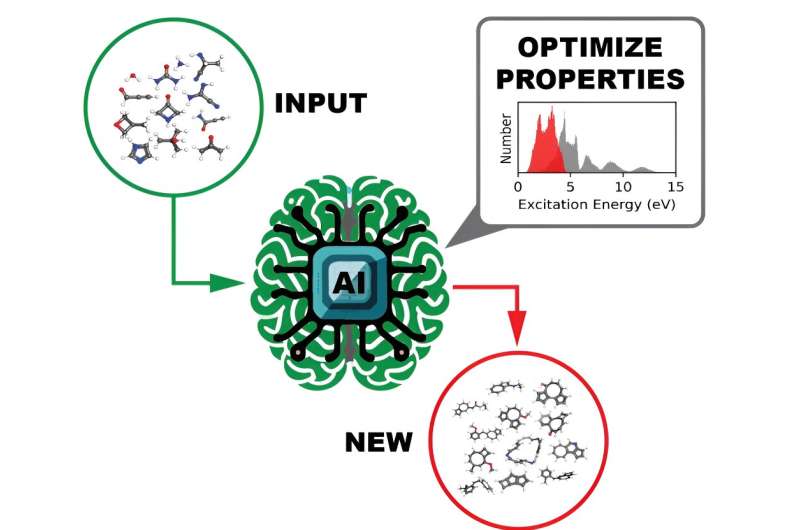
Een team van computationele wetenschappers van het Oak Ridge National Laboratory van het Department of Energy heeft datasets van ongekende omvang gegenereerd en vrijgegeven die de ultraviolette zichtbare spectrale eigenschappen van meer dan 10 miljoen organische moleculen verschaffen. Begrijpen hoe een molecuul interageert met licht is essentieel om de elektronische en optische eigenschappen ervan bloot te leggen, die op hun beurt potentiële fotoactieve toepassingen hebben in producten zoals zonnecellen of medische beeldvormingssystemen.
Met behulp van krachtige computerbronnen in de Oak Ridge Leadership Computing Facility voerde het ORNL-team kwantumchemische berekeningen uit om de enorme datasets te genereren. Voor elk van deze organische moleculen voerde het team atomistische materiaalmodelleringsberekeningen uit met verschillende benaderingen om verschillende interessante eigenschappen van de geëxciteerde toestand te berekenen. De bevindingen van het team zijn gepubliceerd in Scientific Data .
Het uiteindelijke beoogde gebruik van de open-source datasets is het trainen van een deep learning-model om moleculen te identificeren met op maat gemaakte opto-elektronische en fotoreactiviteitseigenschappen, een aanpak die veel sneller en gemakkelijker uit te voeren is dan de huidige methoden.
"Het gebruik van DL-modellen voor moleculair ontwerp is essentieel omdat de chemische ruimte die moet worden verkend voor het zoeken naar deze moleculen extreem groot is", zegt hoofdauteur Massimiliano Lupo Pasini, een datawetenschapper bij de Computational Sciences and Engineering Division van ORNL. P>
“Zowel experimenten als bestaande berekeningen op basis van de basisprincipes, die gebaseerd zijn op de natuurwetten die bepalen hoe materie en energie op subatomair niveau met elkaar omgaan, zijn om verschillende redenen eenvoudigweg onbetaalbaar. Experimenten zijn arbeidsintensief en berekeningen op basis van de principes kunnen supercomputing gemakkelijk de kop indrukken. Maar DL-modellen bieden veelbelovende hulpmiddelen om deze barrières te overwinnen”, aldus Lupo Pasini.
Het project kwam van de grond toen Stephan Irle, leider van de groep Computational Chemistry and Nanomaterials Sciences van ORNL, de in ultraviolet zichtbare spectrums van moleculen identificeerde als een nuttige eigenschap om te voorspellen met DL-modellen.
Het bouwen van een DL-model dat voldoende complex is om gewenste moleculaire eigenschappen te identificeren, vereist training ervan met enorme hoeveelheden gegevens die alle verschillende gebieden van de chemische ruimte onderzoeken. Hoe meer gegevens worden verzameld, hoe beter het daarop getrainde DL-model de noodzakelijke robuustheid en generaliseerbaarheid kan bereiken om effectief te kunnen functioneren. Het verzamelen van zulke grote hoeveelheden wetenschappelijke gegevens voor schaalbare DL kan echter problemen met de gegevensstroom opleveren, vooral bij faciliteiten met meerdere gebruikers zoals de OLCF, een gebruikersfaciliteit van het DOE Office of Science in ORNL.
"Eén uitdaging die zich voordoet bij het genereren van grote hoeveelheden gegevens is dat het aantal te beheren bestanden drastisch toeneemt. Als een dergelijk groot gegevensvolume niet correct wordt beheerd, kan dit de werking van het parallelle bestandssysteem in gevaar brengen, wat een belangrijk onderdeel is van de staat. -moderne HPC-faciliteiten", aldus Lupo Pasini.
Om deze uitdaging aan te pakken, werkte Lupo Pasini samen met ORNL-computerwetenschapper Kshitij Mehta om schaalbare workflowsoftware te ontwikkelen die ervoor zorgt dat de bestanden die door de kwantummechanicacode worden gegenereerd, op de juiste manier worden afgehandeld zonder het bestandssysteem te belasten, zoals Orion van OLCF, een gedeeld systeem. bron die de invoer, uitvoer en opslag van gegevens op supercomputersystemen afhandelt.
Als proof-of-concept-test genereerde het team de GDB-9-Ex-dataset van 96.766 moleculen bestaande uit koolstof, stikstof, zuurstof en fluor, met maximaal negen niet-waterstofatomen. Hieruit bleek dat de ontworpen workflow effectief is en dat de DL-training nauwkeurig de positie en de intensiteit van de meest relevante pieken van het ultraviolette zichtbare spectrum voorspelt.
Vanaf dat eerste succes heeft het team zijn volume opgevoerd met de ORNL_AISD-Ex-dataset, die 10.502.917 moleculen bevat die zijn samengesteld uit koolstof, stikstof, zuurstof, fluor en zwavel, met maximaal 71 niet-waterstofatomen. Pilsun Yoo, een postdoctoraal onderzoeksmedewerker in de groep van Irle, ontwikkelde hulpmiddelen om de resulterende datasets te analyseren.
Het ultraviolet-zichtbare spectrum, dat de excitatiemodi van een molecuul beschrijft, werd berekend voor elk van de meer dan 10 miljoen moleculen. Deze informatie onthult welke lichtfrequentie nodig is om een molecuul te targeten en enkele bindingen van de chemische verbinding te verbreken.
Een andere interessante eigenschap die voor elk molecuul werd berekend, was de HOMO-LUMO-kloof – de energiekloof tussen de hoogst bezette moleculaire orbitaal en de laagste onbezette moleculaire orbitaal – die op betrouwbare wijze de stabiliteit van het molecuul meet. Met deze informatie zou een DL-model de gegevens efficiënt kunnen doorzoeken om veelbelovende moleculen voor verschillende potentiële toepassingen te identificeren.
Lupo Pasini en zijn team bij ORNL, waaronder computerwetenschapper op het gebied van machinaal leren Pei Zhang en HPC-dataonderzoeker Jong Youl Choi, ontwikkelen precies zo'n DL-model:HydraGNN.
"De HydraGNN-architectuur neemt de atomaire structuur op, zet deze om in een grafiek en probeert vervolgens als uitvoer te voorspellen wat de code van de eerste principes zou opleveren. Het is een surrogaatmodel voor dure berekeningen van de eerste principes", zei Lupo Pasini.
De resultaten van HydraGNN's training over de datasets en de moleculaire ontdekkingen ervan zullen gedetailleerd worden beschreven in een komende paper.
Meer informatie: Massimiliano Lupo Pasini et al, Twee datasets in geëxciteerde toestand voor kwantumchemische UV-vis spectra van organische moleculen, Wetenschappelijke gegevens (2023). DOI:10.1038/s41597-023-02408-4
Journaalinformatie: Wetenschappelijke gegevens
Geleverd door Oak Ridge National Laboratory
 Hybride katalysator met hoge enantiomeerselectiviteit
Hybride katalysator met hoge enantiomeerselectiviteit- Zwavel verbetert dubbele breking voor het ontwikkelen van vloeibaar-kristallijne moleculen
- Onderzoekers stellen elektrokatalytische ammoniaksynthese voor als een milieuvriendelijkere methode
- Het beste van twee werelden:hoge entropie ontmoet lage dimensies, opent oneindige mogelijkheden
- Wetenschappers werken aan biologisch afbreekbaar plastic van zonlicht
- Superbug-gen gevonden op een van de meest afgelegen plekken op aarde
- Kunstmatige intelligentie gebruiken om koraalriffen te redden
- Onderwateronderzoeken in Emerald Bay onthullen de aard en activiteit van Lake Tahoe-fouten
- Meer natuurlijk stof in de lucht verbetert de luchtkwaliteit in Oost-China
- Regen beukt centraal Japan, gevreesde 61 doden in het zuiden
Hoofdlijnen
- Psychologische theorie over de vijf menselijke zintuigen
- Wat is het verschil in de cellen van een menselijke baby en een volwassen mens?
Nieuwe baby's zijn allebei erg op elkaar en lijken erg op volwassenen. De meeste celontwikkeling en -differentiatie vinden plaats voorafgaand aan de geboorte van een ba
- Voor duurzame vliegtuigbrandstof ontwikkelen onderzoekers een veelbelovend micro-organisme voor de productie van precursoren
- Nieuwe mobiele app diagnosticeert gewasziekten in het veld en waarschuwt boeren op het platteland
- Perfect bewaarde prehistorische leeuwenwelp gevonden in Russische permafrost
- Duurzame biotechnologie werkelijkheid maken:Gebundelde krachten willen biokatalysatoren verbeteren
- Nieuwe aanpak kan de sleutel zijn tot de behandeling van antibioticaresistente bacteriën
- De jacht op een van de Top 50 meest gezochte schimmels is voorbij
- De Middellandse Zee:onvergelijkbare rijkdom in scherpe daling
- Afstotend onderzoek:marine ontwikkelt scheepscoatings om brandstof te verminderen, energiekosten

- Implanteerbaar piëzo-elektrisch polymeer verbetert gecontroleerde afgifte van medicijnen
- Wetenschappers werken aan het maken van microchip-elementen van moleculaire grootte

- Een lasertechniek blijkt effectief om materiaal terug te winnen dat is ontworpen om industriële producten te beschermen

- Onderzoekers ontrafelen meer mysteries van metallische waterstof


 Enquête onthult verschillende motieven achter Amerikaans wapenbezit
Enquête onthult verschillende motieven achter Amerikaans wapenbezit- Als Betelgeuze boomt:hoe DUNE zou reageren op een nabijgelegen supernova
- Met Comcast uit, hoe Disney's imperium eruit zal zien met Fox
- Stabiele elektroden voor het verbeteren van gedrukte elektronica
- Nanotechnologie pakt diabetes aan
- Studie:Haat op sociale media tegengaan
- Oproep voor schuld rijbewijs
- Onderzoekers rapporteren een eenvoudigere methode voor nauwkeurige moleculaire orbitale visualisatie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
