Wetenschap
Datawetenschappers bouwen eerlijkere voorspellingsmodellen

Krediet:CC0 Publiek Domein
Op 3 november, 2020 - en nog vele dagen daarna - hielden miljoenen mensen de voorspellingsmodellen voor de presidentsverkiezingen van verschillende nieuwskanalen nauwlettend in de gaten. Met zulke hoge inzetten in het spel, elke tik van een telling en trilling van een grafiek kan schokgolven van overinterpretatie veroorzaken.
Een probleem met ruwe cijfers van de presidentsverkiezingen is dat ze een vals verhaal creëren dat de uiteindelijke resultaten zich nog steeds op drastische manieren ontwikkelen. In werkelijkheid, op de verkiezingsavond is er geen sprake van "achteraf inhalen" of "de voorsprong verliezen" omdat de stemmen al zijn uitgebracht; de winnaar heeft al gewonnen - we weten het alleen nog niet. Meer dan alleen onnauwkeurig zijn, deze meeslepende beschrijvingen van het stemproces kunnen de uitkomsten overdreven verdacht of verrassend doen lijken.
"Voorspellende modellen worden gebruikt om beslissingen te nemen die enorme gevolgen kunnen hebben voor het leven van mensen, " zei Emmanuel Candès, de Barnum-Simons-leerstoel in wiskunde en statistiek aan de School of Humanities and Sciences aan de Stanford University. "Het is uiterst belangrijk om de onzekerheid over deze voorspellingen te begrijpen, zodat mensen geen beslissingen nemen op basis van valse overtuigingen."
Zo'n onzekerheid was precies wat De Washington Post datawetenschapper Lenny Bronner wilde in een nieuw voorspellingsmodel benadrukken dat hij begon te ontwikkelen voor lokale verkiezingen in Virginia in 2019 en verder verfijnd voor de presidentsverkiezingen, met de hulp van John Cherian, een huidige Ph.D. student statistiek aan Stanford die Bronner kende van hun bachelorstudies.
"Het model ging eigenlijk over het toevoegen van context aan de resultaten die werden getoond, " zei Bronner. "Het ging niet om het voorspellen van de verkiezingen. Het ging erom de lezers te vertellen dat de resultaten die ze zagen niet overeenkwamen met waar we dachten dat de verkiezingen zouden eindigen."
Dit model is de eerste toepassing in de echte wereld van een bestaande statistische techniek die door Candès aan Stanford is ontwikkeld, voormalig postdoctoraal wetenschapper Yaniv Romano en voormalig afgestudeerde student Evan Patterson. De techniek is toepasbaar op een verscheidenheid aan problemen en, zoals in het predicatiemodel van de Post, zou kunnen helpen om het belang van eerlijke onzekerheid bij prognoses te vergroten. Terwijl de Post hun model blijft verfijnen voor toekomstige verkiezingen, Candès past de onderliggende techniek elders toe, inclusief gegevens over COVID-19.
Aannames vermijden
Om deze statistische techniek te creëren, Candès, Romano en Evan Patterson combineerden twee onderzoeksgebieden - kwantiele regressie en conforme voorspelling - om te creëren wat Candès 'de meest informatieve, goed gekalibreerde reeks voorspelde waarden die ik weet te bouwen."
Hoewel de meeste voorspellingsmodellen één enkele waarde proberen te voorspellen, vaak het gemiddelde (gemiddelde) van een dataset, kwantielregressie schat een reeks plausibele uitkomsten. Bijvoorbeeld, een persoon wil misschien het 90e kwantiel vinden, dat is de drempel waaronder de waargenomen waarde naar verwachting 90 procent van de tijd zal dalen. Wanneer toegevoegd aan kwantielregressie, conforme voorspelling - ontwikkeld door computerwetenschapper Vladimir Vovk - kalibreert de geschatte kwantielen zodat ze geldig zijn buiten een steekproef, zoals voor tot nu toe ongeziene gegevens. Voor het verkiezingsmodel van de Post, dat betekende het gebruik van stemresultaten uit demografisch vergelijkbare gebieden om voorspellingen over uitstaande stemmen te kalibreren.
Het bijzondere aan deze techniek is dat het begint met minimale aannames die in de vergelijkingen zijn ingebouwd. Om te kunnen werken, echter, het moet beginnen met een representatieve steekproef van gegevens. Dat is een probleem voor de verkiezingsavond, omdat de eerste stemmen tellen - meestal van kleine gemeenschappen met meer persoonlijke stemmen - zelden de uiteindelijke uitkomst weerspiegelen.
Zonder toegang tot een representatieve steekproef van huidige stemmen, Bronner en Cherian moesten een veronderstelling toevoegen. Ze hebben hun model gekalibreerd met behulp van de stemmen van de presidentsverkiezingen van 2016, zodat wanneer een gebied 100 procent van hun stemmen rapporteerde, het model van de Post gaat ervan uit dat eventuele wijzigingen tussen de stemmen van 2020 in dat gebied en de stemmen van 2016 in vergelijkbare provincies gelijkelijk worden weerspiegeld. (Het model zou zich dan verder aanpassen - de invloed van de aanname verminderen - naarmate meer gebieden 100 procent van hun stemmen rapporteerden.) Om de geldigheid van deze methode te controleren, ze testten het model bij elke presidentsverkiezing, beginnend met 1992, en ontdekte dat de voorspellingen nauw overeenkwamen met de real-world uitkomsten.
"Wat leuk is aan het gebruik van Emmanuel's benadering hiervan, is dat de foutbalken rond onze voorspellingen veel realistischer zijn en dat we minimale aannames kunnen handhaven, ' zei Cherian.
Onzekerheid visualiseren
in actie, de visualisatie van het live-model van de Post was nauwgezet ontworpen om die foutbalken en de onzekerheid die ze vertegenwoordigden prominent weer te geven. The Post heeft het model gebruikt om het bereik van waarschijnlijke verkiezingsresultaten in verschillende staten en provincietypes te voorspellen; provincies werden gecategoriseerd op basis van hun demografie. In elk geval, elke genomineerde had zijn eigen horizontale balk die effen blauw opvulde voor Joe Biden, rood voor Donald Trump - om bekende stemmen te tonen. Vervolgens, de rest van de balk bevatte een gradiënt die de meest waarschijnlijke resultaten voor de uitstaande stemmen vertegenwoordigde, volgens het model. Het donkerste deel van het verloop was het meest waarschijnlijke resultaat.
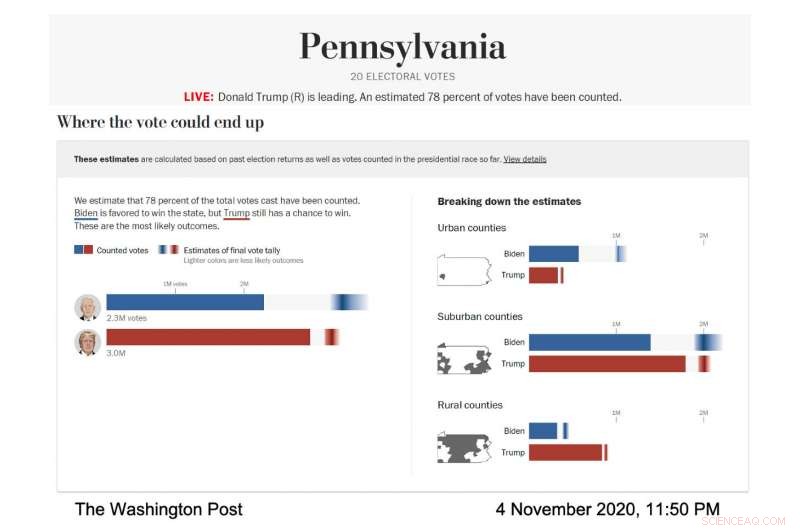
Screenshot van het verkiezingsmodel van de Washington Post, met de stemvoorspelling voor Pennsylvania op 4 november, 2020. Krediet:met dank aan The Washington Post
"We hebben met onderzoekers gesproken over het visualiseren van onzekerheid en we hebben geleerd dat als je iemand een gemiddelde voorspelling geeft en je vervolgens vertelt hoeveel onzekerheid er mee gemoeid is, ze hebben de neiging om de onzekerheid te negeren, "zei Bronner. "Dus hebben we een visualisatie gemaakt die erg 'onzekerheid vooruit' is. We wilden laten zien, dit is de onzekerheid en we gaan je niet eens vertellen wat onze gemiddelde voorspelling is."
Terwijl de verkiezingsavond vorderde, het donkerste deel van de gradiënt van Biden in de totale stemvisualisatie bevond zich verder aan de rechterkant van de balk, wat betekende dat het model voorspelde dat hij meer stemmen zou krijgen. Zijn helling was ook breder en asymmetrisch verspreid naar de hogere stemkant van de balk, wat betekende dat het model voorspelde dat er veel scenario's waren, met redelijke kansen, waar hij meer stemmen zou winnen dan het waarschijnlijke aantal.
"Op de verkiezingsavond we merkten dat de foutbalken erg kort waren aan de linkerkant van de balk van Biden en erg lang aan de rechterkant, "zei Cherian. "Dit was omdat Biden veel voordeel had om mogelijk substantieel beter te presteren dan onze projectie en hij had niet zoveel nadeel." Deze asymmetrische voorspelling was een gevolg van de specifieke modelleringsaanpak die werd gebruikt door Cherian en Bronner Omdat de voorspellingen van het model waren gekalibreerd met behulp van resultaten van demografisch vergelijkbare provincies die klaar waren met het rapporteren van hun stemmen, het werd duidelijk dat Biden een goede kans had om aanzienlijk beter te presteren dan de Democratische stemming van 2016 in de buitenwijken, terwijl het uiterst onwaarschijnlijk was dat hij het slechter zou doen.
Natuurlijk, terwijl het tellen van de stemmen richting de finish ging, de gradiënten slonken en de onzekere voorspellingen van de Post leken steeds zekerder - een zenuwslopende situatie voor datawetenschappers die zulke belangrijke conclusies overdrijven.
"Ik was vooral bang dat de race zou neerkomen op één staat, en we zouden een voorspelling op onze pagina hebben voor dagen die uiteindelijk niet uitkomen, ' zei Bronner.
En die zorg was gegrond omdat het model een aantal dagen sterk en koppig een overwinning van Biden voorspelde, terwijl de eindstemmingen uit niet één staat binnenslopen, maar drie:Wisconsin, Michigan and Pennsylvania.
"He ended up winning those states, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, after all, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. In feite, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, echter, is that the conclusions suffer if there isn't enough data. Bijvoorbeeld, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, Hoewel, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."
 NASA krijgt 's nachts en overdag een blik op een zwakkere brede Irma
NASA krijgt 's nachts en overdag een blik op een zwakkere brede Irma- Natuurlijke veranderingen die een ecosysteem kunnen beïnvloeden
- Dieren die leven op gletsjers en ijsbergen
- Betere communicatiesleutel om het dodental door aardbevingen te verminderen, deskundigen zeggen
- De zeven zeeën van plastic en wat overheden eraan doen
Hoofdlijnen
- Aussie uilen vallen door rattengif
- Wetenschappers zoeken naar overlevenden nadat de Thomas-brand een condorreservaat heeft verschroeid
- Wat zijn de verschillen tussen een plant en een dierlijke cel onder een microscoop?
- Onderzoekers maken een kaart van het microbiële landschap van de darmen
- Wat zijn de 3 meest voorkomende elementen in menselijke lichamen?
- Virusstamping - een veelzijdige nieuwe methode voor genetische manipulatie van afzonderlijke cellen
- Met uitsterven bedreigde mus in Centraal-Florida die in het wild waarschijnlijk niet zal overleven
- Leuke wetenschappelijke experimenten op cellen
- Instrumenten gebruikt in de biologie
Biologen en biologiestudenten gebruiken verschillende instrumenten in hun werk om kennis over levende wezens te verzamelen. Deze instrumenten en hulpmiddelen worden elk jaar gedetailleerder en hightech, evenals
- Mensen worden steeds vaker gestoord op het werk, maar het is niet allemaal slecht

- Hoe mensen in vreemdelingendetentie proberen om te gaan met het leven in het ongewisse

- Wil je de loyaliteit van je medewerkers vergroten? Je moet gezien worden als belangrijk, nieuw onderzoek suggereert:

- Ontslagen VS stegen in maart naar recordhoogte van 11,4 miljoen

- Hoe te onthouden Mean, Mediaan & modus


 Onderzoekers demonstreren groottekwantisatie van Dirac-fermionen in grafeen
Onderzoekers demonstreren groottekwantisatie van Dirac-fermionen in grafeen- Wetenschapper vindt ongrijpbare ster met oorsprong dicht bij de oerknal
- Hoe Roller Coasters te maken voor een Science Fair Project
- SpaceX lanceert 64 satellieten tegelijk
- NASA selecteert voorstellen om smallSat-technologieën te demonstreren om de interplanetaire ruimte te bestuderen
- Onderzoekers rapporteren een isolator gemaakt van twee geleiders
- Nieuw onderzoek analyseert de reactie van beleggers op robo-adviseurs:sommige beleggers missen kansen
- 5 Oorzaken van broeikaseffect
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | Italian |

-
Wetenschap © https://nl.scienceaq.com
