Wetenschap
Een statistische oplossing voor de replicatiecrisis in de wetenschap

Veel wetenschappelijke studies houden geen stand in verdere tests. Krediet:A en N fotografie/Shutterstock.com
In een proef met een nieuw medicijn om kanker te genezen, 44 procent van de 50 patiënten bereikte remissie na behandeling. Zonder het medicijn, slechts 32 procent van de eerdere patiënten deed hetzelfde. De nieuwe behandeling klinkt veelbelovend, maar is het beter dan de standaard?
Die vraag is moeilijk, dus statistici hebben de neiging om een andere vraag te beantwoorden. Ze kijken naar hun resultaten en berekenen iets dat een p-waarde wordt genoemd. Als de p-waarde kleiner is dan 0,05, de resultaten zijn "statistisch significant" - met andere woorden, waarschijnlijk niet worden veroorzaakt door slechts willekeurig toeval.
Het probleem is, veel statistisch significante resultaten worden niet gerepliceerd. Een behandeling die veelbelovend is in de ene studie, levert helemaal geen voordeel op bij de volgende groep patiënten. Dit probleem is zo ernstig geworden dat een psychologietijdschrift p-waarden zelfs helemaal verbood.
Mijn collega's en ik hebben dit probleem bestudeerd, en we denken te weten wat de oorzaak is. De lat voor het claimen van statistische significantie is simpelweg te laag.
De meeste hypothesen zijn onjuist
De open-wetenschappelijke samenwerking, een non-profit organisatie gericht op wetenschappelijk onderzoek, probeerde 100 gepubliceerde psychologie-experimenten te repliceren. Terwijl 97 van de eerste experimenten statistisch significante bevindingen rapporteerden, slechts 36 van de gerepliceerde onderzoeken deden dat.
Verschillende afgestudeerde studenten en ik gebruikten deze gegevens om de kans te schatten dat een willekeurig gekozen psychologisch experiment een echt effect testte. We ontdekten dat slechts ongeveer 7 procent dat deed. In een soortgelijke studie, econoom Anna Dreber en collega's schatten dat slechts 9 procent van de experimenten zou repliceren.
Beide analyses suggereren dat slechts ongeveer één op de dertien nieuwe experimentele behandelingen in de psychologie – en waarschijnlijk vele andere sociale wetenschappen – een succes zal blijken te zijn.
Dit heeft belangrijke implicaties bij het interpreteren van p-waarden, vooral als ze dicht bij 0,05 zijn.
De Bayes-factor
P-waarden in de buurt van 0,05 zijn waarschijnlijker te wijten aan willekeurig toeval dan de meeste mensen beseffen.
Om het probleem te begrijpen, laten we terugkeren naar ons denkbeeldige medicijnonderzoek. Onthouden, 22 van de 50 patiënten op het nieuwe medicijn gingen in remissie, vergeleken met een gemiddelde van slechts 16 van de 50 patiënten op de oude behandeling.
De kans op 22 of meer successen op 50 is 0,05 als het nieuwe medicijn niet beter is dan het oude. Dat betekent dat de p-waarde voor dit experiment statistisch significant is. Maar we willen weten of de nieuwe behandeling echt een verbetering is, of als het niet beter is dan de oude manier van doen.
Er achter komen, we moeten de informatie in de gegevens combineren met de informatie die beschikbaar was voordat het experiment werd uitgevoerd, of de 'voorafgaande kansen'. De prior odds weerspiegelen factoren die niet direct in het onderzoek worden gemeten. Bijvoorbeeld, ze zouden het feit kunnen verklaren dat in 10 andere onderzoeken met vergelijkbare medicijnen, geen enkele bleek succesvol te zijn.
Als het nieuwe medicijn niet beter is dan het oude medicijn, dan vertellen de statistieken ons dat de kans om precies 22 van de 50 successen te zien in deze proef 0,0235 is - relatief laag.
Wat als het nieuwe medicijn echt beter is? We kennen het slagingspercentage van het nieuwe medicijn niet, maar een goede gok is dat het dicht bij het waargenomen succespercentage ligt, 22 van de 50. Als we aannemen dat, dan is de kans om precies 22 van de 50 successen waar te nemen 0,113 - ongeveer vijf keer meer kans. (Niet bijna 20 keer meer kans, Hoewel, zoals je zou kunnen raden als je wist dat de p-waarde van het experiment 0,05 was.)
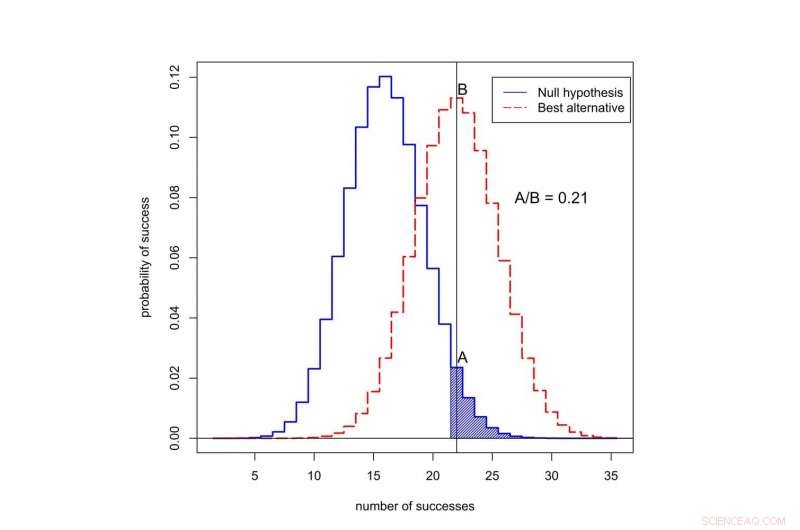
Wat is de kans op succes in 50 proeven? De zwarte curve vertegenwoordigt kansen onder de 'nulhypothese, ’ als de nieuwe behandeling niet beter is dan de oude. De rode curve geeft kansen weer wanneer de nieuwe behandeling beter is. Het gearceerde gebied vertegenwoordigt de p-waarde. In dit geval, de verhouding van de kansen toegekend aan 22 successen is A gedeeld door B, of 0,21. Krediet:Valen Johnson, CC BY-SA
Deze verhouding van de kansen wordt de Bayes-factor genoemd. We kunnen de stelling van Bayes gebruiken om de Bayes-factor te combineren met de prior odds om de kans te berekenen dat de nieuwe behandeling beter is.
Ter wille van het argument, stel dat slechts 1 op de 13 experimentele kankerbehandelingen een succes zal blijken te zijn. Dat komt dicht in de buurt van de waarde die we schatten voor de psychologische experimenten.
Als we deze prior odds combineren met de Bayes-factor, het blijkt dat de kans dat de nieuwe behandeling niet beter is dan de oude minimaal 0,71 is. Maar de statistisch significante p-waarde van 0,05 suggereert precies het tegenovergestelde!
Een nieuwe aanpak
Deze inconsistentie is typerend voor veel wetenschappelijke studies. Het is vooral gebruikelijk voor p-waarden rond de 0,05. Dit verklaart waarom zo'n hoog percentage statistisch significante resultaten niet repliceren.
Dus hoe moeten we de eerste claims van een wetenschappelijke ontdekking evalueren? In september, mijn collega's en ik stelden een nieuw idee voor:alleen P-waarden van minder dan 0,005 moeten als statistisch significant worden beschouwd. P-waarden tussen 0,005 en 0,05 zijn slechts suggestief te noemen.
In ons voorstel statistisch significante resultaten hebben meer kans om te repliceren, zelfs na rekening te hebben gehouden met de kleine eerdere kansen die typisch betrekking hebben op studies in de sociale, biologische en medische wetenschappen.
Bovendien, we denken dat statistische significantie niet mag dienen als een heldere drempel voor publicatie. Statistisch suggestieve resultaten - of zelfs resultaten die grotendeels niet overtuigend zijn - kunnen ook worden gepubliceerd, gebaseerd op het al dan niet rapporteren van belangrijk voorlopig bewijs met betrekking tot de mogelijkheid dat een nieuwe theorie waar zou kunnen zijn.
Op 11 oktober we presenteerden dit idee aan een groep statistici op het ASA Symposium on Statistical Inference in Bethesda, Maryland. Ons doel bij het wijzigen van de definitie van statistische significantie is om de bedoelde betekenis van deze term te herstellen:dat gegevens substantiële ondersteuning hebben geboden voor een wetenschappelijke ontdekking of behandelingseffect.
Kritiek op ons idee
Niet iedereen is het met ons voorstel eens, waaronder een andere groep wetenschappers onder leiding van psycholoog Daniel Lakens.
Zij stellen dat de definitie van Bayes-factoren te subjectief is, en dat onderzoekers andere veronderstellingen kunnen maken die hun conclusies zouden kunnen veranderen. In de klinische proef, bijvoorbeeld, Lakens zou kunnen beweren dat onderzoekers het remissiepercentage van drie maanden in plaats van zes maanden zouden kunnen rapporteren, als het sterker bewijs leverde voor het nieuwe medicijn.
Lakens en zijn groep vinden ook dat de schatting dat slechts ongeveer één op de 13 experimenten zal worden herhaald, te laag is. Ze wijzen erop dat deze schatting geen rekening houdt met effecten zoals p-hacking, een term voor wanneer onderzoekers hun gegevens herhaaldelijk analyseren totdat ze een sterke p-waarde vinden.
In plaats van de lat voor statistische significantie te verhogen, de Lakens-groep vindt dat onderzoekers hun eigen niveau van statistische significantie moeten bepalen en rechtvaardigen voordat ze hun experimenten uitvoeren.
Ik ben het niet eens met veel van de beweringen van de Lakens-groep - en, puur praktisch gezien, Ik heb het gevoel dat hun voorstel een non-starter is. De meeste wetenschappelijke tijdschriften bieden geen mechanisme voor onderzoekers om hun keuze van p-waarden vast te leggen en te rechtvaardigen voordat ze experimenten uitvoeren. Belangrijker, onderzoekers hun eigen bewijsdrempels laten bepalen lijkt geen goede manier om de reproduceerbaarheid van wetenschappelijk onderzoek te verbeteren.
Het voorstel van Lakens zou alleen werken als tijdschriftredacteuren en financieringsinstanties van tevoren overeenkomen om rapporten te publiceren van experimenten die niet zijn uitgevoerd op basis van criteria die wetenschappers zelf hebben opgelegd. Ik denk dat dit in de nabije toekomst waarschijnlijk niet zal gebeuren.
Tot het zover is, Ik raad je aan om claims uit wetenschappelijke studies die gebaseerd zijn op p-waarden rond de 0,05 niet te vertrouwen. Dring aan op een hogere standaard.
Dit artikel is oorspronkelijk gepubliceerd op The Conversation. Lees het originele artikel. 
 De effecten van verwarming H2O2 en stabiliteit
De effecten van verwarming H2O2 en stabiliteit - Dun, rekbare biosensoren kunnen chirurgie veiliger maken
- Welke chemicaliën zijn schadelijk voor rubberafdichtingen?
- Onderzoek naar kant-en-klare therapeutische voeding streeft naar drastische vermindering van sterfgevallen door ernstige acute ondervoeding
- Veiligere toekomst voor spoorvervoer van gevaarlijke stoffen in ontwikkeling
- Fossiele bomen op het centrale Andesplateau van Peru vertellen een verhaal over dramatische veranderingen in het milieu
- De Amazone is niet gestopt met branden. Er waren 19, 925 branduitbarstingen vorige maand, en er zijn nog meer branden in de toekomst
- Snel, nauwkeurige schatting van het aardmagnetisch veld voor detectie van natuurrampen
- Voors en tegens van dierproeven
- Lijst van bacteriën in het gematigde bladverliezende wouden
Hoofdlijnen
- Trucs voor het onthouden van dieren Phylum
- De 3 soorten bacteriën
- Zijn mensen het slimste dier?
- Lijst met genotypes
- Gekapte tropische regenwouden ondersteunen nog steeds de biodiversiteit, zelfs als de hitte aan staat
- Stadia van meiose met een beschrijving
- Geluidsoverlast storend voor scholende vissen
- Nest van bedreigde reuzenweekschildpad gevonden in Cambodja
- Wat is het oudste levende wezen op aarde?
- De CDC heeft niet langer de controle over de ziekenhuisopnamegegevens van COVID-19 - dit betekent dat:

- Dierenwelzijn:als je goedkoop breiwerk wilt, het zijn de schapen die kunnen lijden

- Hoe het familievijandige beleid van Amerika vrouwen en kinderen schaadt

- Een octrooi indienen?

- Publiek ziet verfijning, coördinatie als belangrijkste bedreiging bij terroristische aanslagen, studie vondsten


 Pay-it-forward financieringsbeleid voor universiteiten onderzocht in nieuwe studie
Pay-it-forward financieringsbeleid voor universiteiten onderzocht in nieuwe studie- Volkswagen biedt vanaf 2019 volledig elektrisch autodelen aan
- Chinese rover vindt maannachten kouder dan verwacht
- Geavanceerde 3D-geprinte onderdelen voor NASA's Orion ontworpen om extreme temperaturen te weerstaan
- Corrupte banden cultiveren in post-Mao China
- Griekse megabranden wijzen op mislukking in voorbereiding deskundigen zeggen
- Drone-waarnemingen verstoren Singapore-vluchten voor de tweede keer
- Metasurfaces zorgen voor verbeterde optische lensprestaties
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
