Wetenschap
Hoe machine learning onderzoekers helpt bij het verfijnen van klimaatmodellen om ongekende details te bereiken
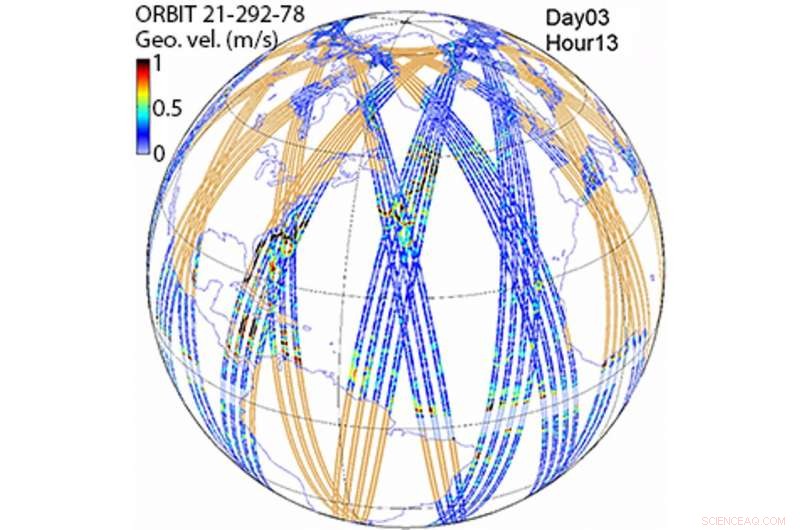
Dit diagram toont het gebied dat wordt bestreken door de SWOT-satelliet na drie dagen in een baan om de aarde. Hoewel SWOT zeer nauwkeurige metingen mogelijk maakt, aangrenzende gebieden in de oceaan worden niet zo vaak bemonsterd. Krediet:C. Ubelmann/CLS
Van filmsuggesties tot zelfrijdende voertuigen, machine learning heeft een revolutie teweeggebracht in het moderne leven. Experts gebruiken het nu om een van de grootste problemen van de mensheid op te lossen:klimaatverandering.
Met machinaal leren, we kunnen onze overvloed aan historische klimaatgegevens en observaties gebruiken om voorspellingen van het toekomstige klimaat op aarde te verbeteren. En deze voorspellingen zullen de komende jaren een grote rol spelen bij het verminderen van onze klimaatimpact.
Wat is machinaal leren?
Machine learning is een tak van kunstmatige intelligentie. Hoewel het een modewoord is geworden, het is in wezen een proces van het extraheren van patronen uit gegevens.
Machine learning-algoritmen gebruiken beschikbare datasets om een model te ontwikkelen. Dit model kan vervolgens voorspellingen doen op basis van nieuwe gegevens die geen deel uitmaakten van de oorspronkelijke dataset.
Terugkomend op ons klimaatprobleem, er zijn twee hoofdbenaderingen waarmee machine learning ons kan helpen het klimaat beter te begrijpen:observaties en modellering.
In recente jaren, de hoeveelheid beschikbare data uit observatie- en klimaatmodellen is exponentieel gegroeid. Het is onmogelijk voor mensen om dit allemaal te doorstaan. Gelukkig, machines kunnen dat voor ons doen.
Waarnemingen vanuit de ruimte
Satellieten houden continu het oppervlak van de oceaan in de gaten, wetenschappers nuttig inzicht geven in hoe oceaanstromen veranderen.

Een artist impression van de SWOT-satelliet. Krediet:NASA/CERN, CC BY
NASA's Surface Water and Ocean Topography (SWOT) -satellietmissie - gepland voor eind volgend jaar - heeft tot doel het oceaanoppervlak in ongekend detail te observeren in vergelijking met de huidige satellieten.
Maar een satelliet kan niet de hele oceaan tegelijk observeren. Het kan alleen het gedeelte van de oceaan eronder zien. En de SWOT-satelliet heeft 21 dagen nodig om elk punt over de hele wereld te passeren.
Is er een manier om de ontbrekende gegevens in te vullen, zodat we op elk moment een volledig globaal beeld van het oceaanoppervlak kunnen hebben?
Dit is waar machine learning om de hoek komt kijken. Algoritmen voor machine learning kunnen gegevens gebruiken die door de SWOT-satelliet zijn opgehaald om de ontbrekende gegevens tussen elke SWOT-revolutie te voorspellen.
Obstakels bij klimaatmodellering
Waarnemingen informeren ons over het heden. Echter, om het toekomstige klimaat te voorspellen, moeten we vertrouwen op uitgebreide klimaatmodellen.
Het laatste klimaatrapport van het IPCC is gebaseerd op klimaatprognoses van verschillende onderzoeksgroepen over de hele wereld. Deze onderzoekers hebben een groot aantal klimaatmodellen gebruikt die verschillende emissiescenario's vertegenwoordigen die voorspellingen van honderden jaren in de toekomst opleverden.
Om het klimaat te modelleren, computers overlappen een rekenraster op de oceanen, atmosfeer en land. Vervolgens, door te beginnen met het klimaat van vandaag, ze kunnen de vergelijkingen van vloeistof- en warmtebeweging binnen elke doos van dit raster oplossen om te modelleren hoe het klimaat in de toekomst zal evolueren.
De grootte van elk vak in het raster is wat we de "resolutie" van het model noemen. Hoe kleiner het formaat van de doos, hoe fijner de stroomdetails die het model kan vastleggen.

Hier, je kunt oceaanstromingen zien gemodelleerd met twee verschillende resoluties. Aan de linkerkant is een model dat lijkt op het model dat doorgaans wordt gebruikt voor klimaatprojecties. Het model rechts is veel nauwkeuriger en realistischer, maar is helaas te rekenkundig te beperkend om te worden gebruikt voor klimaatprojecties. Krediet:COSIMA, Auteur verstrekt
Maar het draaien van klimaatmodellen die honderden jaren vooruit projecteren, brengt zelfs de krachtigste supercomputers op hun knieën. Dus, we zijn momenteel genoodzaakt om deze modellen met een grove resolutie uit te voeren. In feite, het is soms zo grof dat de stroom in niets lijkt op het echte leven.
Bijvoorbeeld, oceaanmodellen die voor klimaatprojecties worden gebruikt, zien er meestal uit als die aan de linkerkant hieronder. Maar in werkelijkheid, oceaanstroom lijkt veel meer op de afbeelding rechts.
Helaas, we hebben momenteel niet de rekenkracht die nodig is om realistische klimaatmodellen met hoge resolutie voor klimaatprojecties uit te voeren.
Klimaatwetenschappers proberen manieren te vinden om de effecten van de boete, kleinschalige turbulente bewegingen in de afbeelding rechtsboven in het klimaatmodel met grove resolutie aan de linkerkant.
Als we dit kunnen, we kunnen klimaatprojecties genereren die nauwkeuriger zijn, maar nog steeds rekenkundig mogelijk. Dit is wat we 'parameterisatie' noemen - de heilige graal van klimaatmodellering.
gewoon, dit is wanneer we een model kunnen bereiken dat niet noodzakelijkerwijs alle kleinere complexe stroomfuncties omvat (die enorme hoeveelheden verwerkingskracht vereisen) - maar dat hun effecten nog steeds op een eenvoudiger en goedkopere manier in het algemene model kan integreren.
Een duidelijker beeld
Sommige parametriseringen bestaan al in modellen met grove resolutie, maar slagen er vaak niet goed in om de kleinere stroomfuncties op een effectieve manier te integreren.
Algoritmen voor machinaal leren kunnen output gebruiken van realistische, klimaatmodellen met hoge resolutie (zoals die rechts hierboven) om veel nauwkeurigere parametrering te ontwikkelen.
Naarmate onze rekencapaciteit groeit - samen met onze klimaatgegevens - zullen we steeds geavanceerdere algoritmen voor machine learning kunnen gebruiken om deze informatie te doorzoeken en verbeterde klimaatmodellen en -projecties te leveren.
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 
 Nieuwe stikstof-assemblage koolstofkatalysator heeft potentieel om chemische productie te transformeren
Nieuwe stikstof-assemblage koolstofkatalysator heeft potentieel om chemische productie te transformeren- Katalytische hydrogenering van kooldioxide tot methanol
- Blauwdrukken voor geneesmiddelen tegen kanker ontdekt in bacteriële genomen
- Studie onthult geheim 18e-eeuws portret
- Wetenschappers gaan diep om de eigenschappen van perovskiet te kwantificeren
- We kunnen onze vis eten en ook klimaatverandering bestrijden
- Geleerden kunnen de code van de Etruskische taal kraken met grote,
- Advies:Methoden voor het beschermen van Engelse kustgemeenschappen zijn niet geschikt voor hun doel
- De wereldwijde uitstoot van kooldioxide stijgt, zelfs als steenkool afneemt en hernieuwbare energiebronnen toenemen
- Ecologische impact van kippenhouderijen
Hoofdlijnen
- De chemische samenstelling van uitgeademde lucht uit menselijke longen
- De ontwerpprincipes van celcompartimenten blootleggen
- Hoop vervlogen voor gigantisch nieuw Antarctisch zeereservaat
- Ambtenaren:GGO-muggen zijn geen drugs, EPA-toezicht nodig
- Celstructuur van een dier
- Chemische reacties vereist voor het onderhoud van Homeostasis
- De functie van macromoleculen
- Studie maakt ingang naar landbouw zwanenhals zeepokken
- Hoe een zevende-graadsmodel van een dierencel te bouwen
- Kunnen we stoppen met het offshoren van ons plasticprobleem?

- Wat is de drijvende kracht achter de vermindering van de uitstoot van broeikasgassen in de VS?

- Onderzoek toont aan dat N95-ademhalingstoestellen robuuste bescherming kunnen bieden tegen natuurbrandrook
- Big data gebruiken om rampen te bestrijden
- Dodental overstromingen Japan stijgt tot 15


 THOR:Samenwerking stimuleren bij onderzoek naar botsingen met zware ionen
THOR:Samenwerking stimuleren bij onderzoek naar botsingen met zware ionen- Profilering van extreme bundels:wetenschappers bedenken nieuwe diagnostiek voor geavanceerde en next-gen deeltjesversnellers
- Hoe een blowerweerstand te testen
- Verstrengeling van fotonen van verschillende kleuren
- Werknemers ontslagen bij Google plannen federale arbeidsklacht
- Onderzoekers bereiken fused silica met een hoge schadedrempel door chemisch etsen en laserpolijsten te combineren
- betasten, slijpen, grijpen:uit nieuw onderzoek naar nachtclubs blijkt dat mannen het vaak doen, maar weten dat het verkeerd is
- Schimmelwegen op kaaskorst beïnvloeden voedselveiligheid, rijpheid
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
