Wetenschap
Een diepgaand leerraamwerk om de mogelijkheden van een robotachtige schetsagent te verbeteren
Krediet:Lee et al.
In de afgelopen jaren hebben deep learning-algoritmen opmerkelijke resultaten behaald op verschillende gebieden, waaronder artistieke disciplines. Veel computerwetenschappers over de hele wereld hebben zelfs met succes modellen ontwikkeld waarmee artistieke werken kunnen worden gemaakt, waaronder gedichten, schilderijen en schetsen.
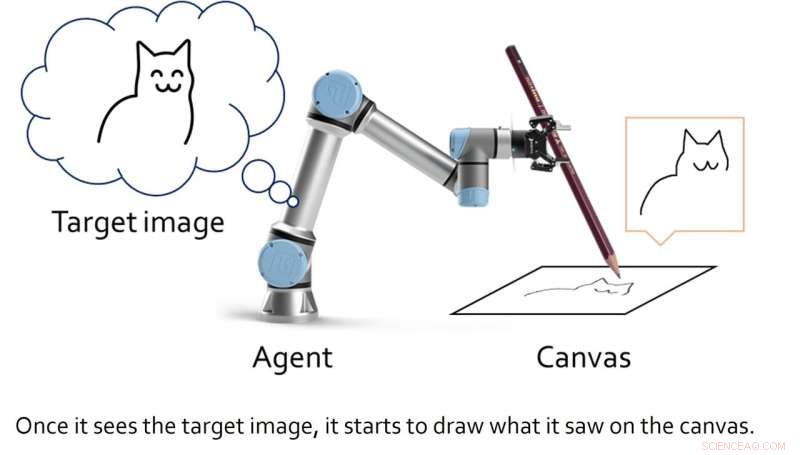
Onderzoekers van de Seoul National University hebben onlangs een nieuw artistiek deep learning-raamwerk geïntroduceerd, dat is ontworpen om de vaardigheden van een schetsrobot te verbeteren. Hun raamwerk, geïntroduceerd in een paper gepresenteerd op ICRA 2022 en vooraf gepubliceerd op arXiv, stelt een schetsrobot in staat om zowel op slag gebaseerde rendering als motorbesturing tegelijkertijd te leren.
"De primaire motivatie voor ons onderzoek was om iets cools te maken met niet-regelgebaseerde mechanismen zoals deep learning; we dachten dat tekenen cool was om te laten zien of de tekenaar een geleerde robot is in plaats van een mens," Ganghun Lee, de eerste auteur van het artikel, vertelde TechXplore. "Recente deep learning-technieken hebben verbluffende resultaten opgeleverd op artistiek gebied, maar de meeste gaan over generatieve modellen die in één keer hele pixelresultaten opleveren."
In plaats van een generatief model te ontwikkelen dat artistieke werken produceert door specifieke pixelpatronen te genereren, creëerden Lee en zijn collega's een raamwerk dat tekenen voorstelt als een sequentieel beslissingsproces. Dit opeenvolgende proces lijkt op de manier waarop mensen individuele lijnen zouden tekenen met een pen of potlood om geleidelijk een schets te maken.
De onderzoekers hoopten hun raamwerk vervolgens toe te passen op een robotachtige schetsagent, zodat deze in realtime schetsen kon maken met een echte pen of potlood. Terwijl andere teams in het verleden deep learning-algoritmen voor 'robotkunstenaars' creëerden, vereisten deze modellen doorgaans grote trainingsdatasets met schetsen en tekeningen, evenals inverse kinematische benaderingen om de robot te leren een pen te manipuleren en ermee te schetsen.
Het raamwerk dat door Lee en zijn collega's is gemaakt, is daarentegen niet getraind op echte tekenvoorbeelden. In plaats daarvan kan het in de loop van de tijd autonoom zijn eigen tekenstrategieën ontwikkelen, door middel van vallen en opstaan.
"Ons raamwerk maakt ook geen gebruik van inverse kinematica, waardoor robotbewegingen een beetje streng zijn, maar laat het systeem ook zijn eigen bewegingstrucs vinden (aanpassen van gewrichtswaarden) om de bewegingsstijl zo natuurlijk mogelijk te maken," zei Lee. "Met andere woorden, het beweegt zijn gewrichten rechtstreeks zonder primitieven, terwijl veel robotsystemen gewoonlijk primitieven gebruiken om te bewegen."
Krediet:Lee et al.
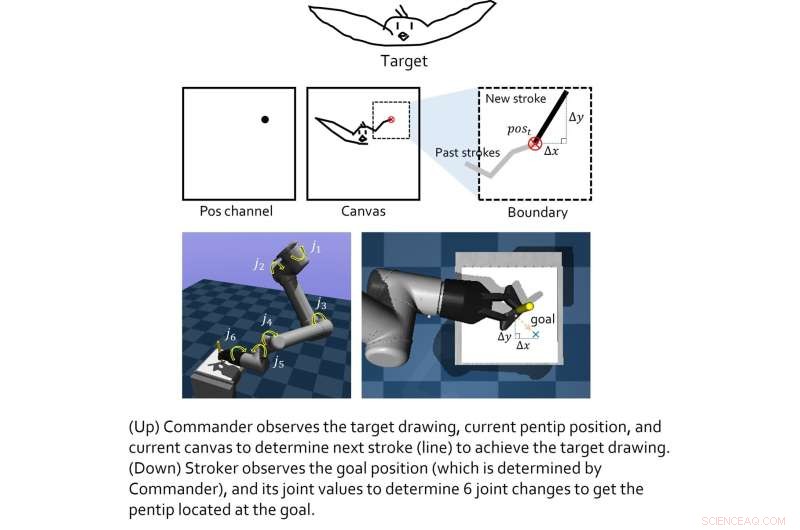
Het model dat door dit team van onderzoekers is gemaakt, omvat twee 'virtuele agenten', namelijk de agent van de hogere klasse en de lagere klasse. De rol van de hogere klasse agent is om nieuwe tekentrucs te leren, terwijl de lagere klasse agent effectieve bewegingsstrategieën leert.
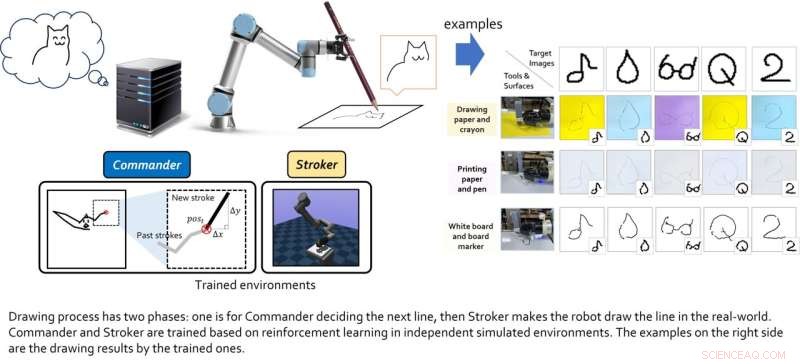
De twee virtuele agenten werden individueel getraind met behulp van versterkingsleertechnieken en werden pas gekoppeld nadat ze hun respectievelijke training hadden voltooid. Lee en zijn collega's testten vervolgens hun gecombineerde prestaties in een reeks real-world experimenten, met behulp van een 6-DoF robotarm met een 2D-grijper erop. De resultaten die in deze eerste tests werden behaald, waren zeer bemoedigend, omdat het algoritme de robotagent in staat stelde goede schetsen van specifieke afbeeldingen te maken.

Krediet:Lee et al.
"We vinden dat de op versterking gebaseerde leermodules die voor elk doel zijn getraind, kunnen worden samengevoegd om grotere samenwerkingsdoelen te bereiken", legt Lee uit. "In een hiërarchische setting kunnen beslissingen van de hogere agent de 'tussenstatus' zijn, waardoor de lagere agent kan observeren om lagere beslissingen te nemen. het hele systeem van elke module kan geweldige dingen doen. De eerste voorwaarde is echter dat, zoals bij alle benaderingen voor versterkend leren, de beloningsfuncties voor elke agent goed moeten zijn gevormd (het is niet gemakkelijk)."
In de toekomst zou het door Lee en zijn collega's gecreëerde raamwerk kunnen worden gebruikt om de prestaties van zowel bestaande als nieuw ontwikkelde robotachtige schetsagenten te verbeteren. Ondertussen ontwikkelt Lee vergelijkbare modellen op basis van creatieve bekrachtiging, waaronder een systeem dat artistieke collages kan produceren.
Krediet:Lee et al.
"We zouden de taak ook graag uitbreiden naar meer gecompliceerde robottekeningen zoals schilderijen, maar ik concentreer me nu meer op de praktische problemen van toepassingen voor het leren van versterkingen zelf dan op de robottekeningen," voegde Lee eraan toe. "Ik hoop dat onze paper een leuk en zinvol voorbeeld wordt van pure, op versterking gebaseerde, op leren gebaseerde toepassingen, speciaal uitgerust met robots." + Verder verkennen
Een versterkend leerkader om de voetbalschietvaardigheden van viervoetige robots te verbeteren
© 2022 Science X Network
 Groenere manieren om kleding te kleuren
Groenere manieren om kleding te kleuren- Wat doet een katalysator in een chemische reactie?
- Plastic dat de planeet redt? Nieuwe hars voor startups helpt de industrie groen te worden
- De deuren openen naar effectieve COVID-19-behandelingen
- Witte wijn, Combo met citroensap voorkomt ongewenste verkleuring van deeg
- Materialen die de hitte voor kinderen erger maken, vragen om heroverweging door ontwerpers
- Nieuwe Aarde-missie zal stijgende oceanen volgen tot 2030
- Eerlijkere financiering zou het netto nulpunt voor Afrika met een decennium kunnen versnellen
- Mijnbouw en megaprojecten komen naar voren als alarmerende bedreiging voor tropische bossen en biodiversiteit
- Recordhoeveelheid hernieuwbare energiecapaciteit toegevoegd in 2016:UN
Hoofdlijnen
- Zeewier bevat veel vitamines en mineralen, maar dat is niet de enige reden waarom westerlingen er meer van zouden moeten eten
- Microscopie onthult mechanisme achter nieuwe CRISPR-tool
- Hoe diepe hersenstimulatie werkt
- Een zwaartekrachttheorie ontwikkelen voor ecologie
- Fossiele apentanden openen een nieuw venster in oude seizoensklimaten
- Onderzoeker koppelt zalmseks aan geologische verandering
- Stimulering van plantengroei door hoge CO2 hangt af van fosforhomeostase in chloroplasten
- Het verschil tussen prokaryotische en eukaryotische genexpressie
- Heb je testangst? Hier is hoe we het moeten aanpakken
- Hoe te voorkomen dat de robotapocalyps een einde maakt aan de bevalling zoals we die kennen?

- Betaalbare en mobiele zuivering van dialysewater
- Samsung patent talk verkent televisies die draadloos zijn gemaakt
- ONS, Europese functionarissen brengen aanklacht in in wereldwijde malwarezaak

- Autofabrikanten willen autoshow Genève elektrificeren, somberheid bestrijden


 Uw vakantiefoto's kunnen helpen om bedreigde diersoorten te redden
Uw vakantiefoto's kunnen helpen om bedreigde diersoorten te redden- Proxima Centauris niet goed, heel slechte dag
- De liefde van mensen voor de zeeën zou de sleutel kunnen zijn voor een oplossing voor plasticvervuiling
- Lijst van de soorten diergedrag
- Nieuw onderzoek integreert borofeen en grafeen in 2D heterostructuren
- Venetië zet zich schrap voor meer hoogwater als alarm afgaat
- Britse voetbalfans verwerpen het nemen van de knie als een hol gebaar dat racisme niet bestrijdt
- Hoe is fruit gevormd in planten?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
