Wetenschap
Kan het additieve boommodel machine learning in de geneeskunde uitbreiden?
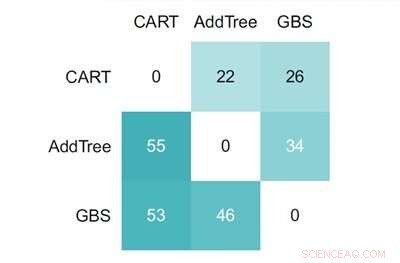
Een weergave van hoe vaak de Additive Tree beter presteerde dan CART en gradiëntversterking (GBS) binnen het onderzoek. Krediet:Perelman School of Medicine aan de Universiteit van Pennsylvania
Wanneer zorgverleners een test bestellen of een geneesmiddel voorschrijven, ze willen 100 procent vertrouwen hebben in hun beslissing. Dat betekent dat ze hun beslissing kunnen uitleggen en bestuderen, afhankelijk van hoe een patiënt reageert. Naarmate de voetafdruk van kunstmatige intelligentie in de geneeskunde toeneemt, dat vermogen om werk te controleren en het pad van een beslissing te volgen, kan een beetje vertroebeld worden. Dat is de reden waarom de ontdekking van een ooit verborgen doorgaande lijn tussen twee populaire voorspellende modellen die worden gebruikt in kunstmatige intelligentie, de deur veel breder opent om machine learning met vertrouwen verder te verspreiden in de gezondheidszorg. De ontdekking van het koppelingsalgoritme en de daaropvolgende creatie van de "additievenboom" wordt nu gedetailleerd beschreven in de Proceedings van de National Academy of Sciences ( PNAS ).
"In de geneeskunde, de kosten van een verkeerde beslissing kunnen erg hoog zijn, " zei een van de auteurs van de studie, Lyle Ungar, doctoraat, een professor in computer- en informatiewetenschappen aan Penn. "In andere sectoren bijvoorbeeld, als een bedrijf beslist welke reclame aan zijn consumenten wordt getoond, ze hoeven waarschijnlijk niet nogmaals te controleren waarom de computer een bepaalde advertentie heeft geselecteerd. Maar in de zorg aangezien het mogelijk is om iemand kwaad te doen met een verkeerde beslissing, het is het beste om precies te weten hoe en waarom een beslissing is genomen."
Het team onder leiding van Jose Marcio Luna, doctoraat, een onderzoeksmedewerker in Radiation Oncology en lid van de Computational Biomarker Imaging Group (CBIG) bij Penn Medicine, en Gilmer Valdes, doctoraat, een assistent-professor Radiation Oncology aan de Universiteit van Californië, San Francisco, ontdekte een algoritme dat loopt van nul tot één op een schaal. Wanneer een voorspellend model op nul wordt gezet op de schaal van het algoritme, de voorspellingen zijn het meest nauwkeurig, maar ook het moeilijkst te ontcijferen, vergelijkbaar met "gradient boosting" -modellen. Wanneer een model is ingesteld op één, het is gemakkelijker te interpreteren, hoewel de voorspellingen minder nauwkeurig zijn, zoals "classificatie- en regressiebomen" (CART's). Luna en zijn co-auteurs ontwikkelden vervolgens hun beslisboom ergens in het midden van de schaal van het algoritme.
"Eerder, mensen gebruikten CART en gradiëntversterking afzonderlijk, als twee verschillende tools in de toolbox, Luna zei. "Maar het algoritme dat we hebben ontwikkeld, laat zien dat ze allebei aan de uiterste uiteinden van een spectrum bestaan. De additievenboom gebruikt dat spectrum zodat we het beste van twee werelden krijgen:hoge nauwkeurigheid en grafische interpreteerbaarheid."
In de studie, de onderzoekers ontdekten dat de additieve boom superieure voorspellende prestaties vertoonde ten opzichte van CART in 55 van de 83 verschillende taken. Aan de andere kant, gradiëntversterking presteerde beter in voorspelling in 46 van 83 scenario's. Hoewel dit niet significant beter was, het laat wel zien dat de additievenboom competitief was en toch beter interpreteerbaar was.
Vooruit gaan, de additievenboom biedt een aantrekkelijke optie voor zorgstelsels, vooral voor diagnostiek en het genereren van prognoses in een tijd waarin er meer vraag is naar precisiegeneeskunde. Verder, de additieve boom heeft het potentieel om te helpen bij het nemen van weloverwogen beslissingen in andere belangrijke domeinen zoals strafrecht en financiën, waar het interpreteren van de modellen zou kunnen helpen om mogelijke ernstige risico's te overwinnen.
 Gemeenschapskenmerken geven vorm aan discussies over klimaatverandering na extreem weer
Gemeenschapskenmerken geven vorm aan discussies over klimaatverandering na extreem weer- Top 10 Redenen om te Verminderen, Recyclen & Hergebruiken
- Welke twee continenten liggen volledig op het zuidelijk halfrond?
- Het smeltwater van de Groenlandse ijskap kan in de winter stromen, te
- Zeespiegelstijging in 20e eeuw het snelst in 2, 000 jaar langs een groot deel van de oostkust
Hoofdlijnen
- Wat zijn de functies van mRNA & tRNA?
- Wat veroorzaakt smeren bij elektroforese?
- Hoe kan een mutatie in DNA invloed hebben op eiwitsynthese?
- Hoe werken het ademhalingsstelsel en het cardiovasculaire systeem samen?
- Kan eten mensen gelukkig maken?
- Voor een gestreepte mangoest in het noorden van Botswana, communiceren met familie kan dodelijk zijn
- Waardoor stinkt de durian-vrucht? Kankerwetenschappers kraken het durian-genoom
- Kan boos worden goed voor je zijn?
- Onderzoek naar klimaatverandering van de achteruitgang van de jongen van lederschildpadden levert geen antwoorden op
- Amazon investeert in Britse voedselkoerier Deliveroo

- Drone-expert ontwikkelt drone-technologie om de grootte van kleine, onderwater sedimenten

- Visuele weergave van vormen op 2D-weergaveapparaten aan de hand van handgebaren
- Een geglobaliseerde toekomst op zonne-energie is economisch onrealistisch

- Onderzoek toont aan dat regelgevers nutsbedrijven een hoger rendement toestaan


 Pulserende aurora:Killer-elektronen in tokkelende luchtlichten
Pulserende aurora:Killer-elektronen in tokkelende luchtlichten- Klimaatrampen vormen de basis voor belangrijk wetenschappelijk VN-rapport
- Americas 180 over atletenactivisme
- Wetenschappers lossen mysterie op over hoe de meeste antimaterie in de Melkweg wordt gevormd
- Ierse hongersnoodslachtoffers zwaar roken leidde tot tandbederf, nieuw onderzoek onthult
- Vloeibaar water is begraven onder het landschap van Mars, studie zegt:
- Waarom mensen hun smartphone gebruiken in cafés
- Theories About the Origins of the First American Indians
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | German | Dutch | Danish | Norway | Portuguese | Swedish |

-
Wetenschap © https://nl.scienceaq.com
