Wetenschap
Spotify-gegevens gebruiken om te voorspellen welke nummers hits worden
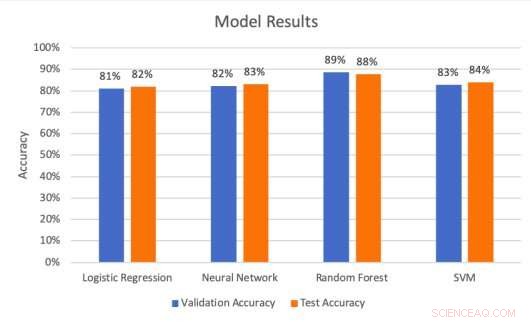
Model Resultaten op de validatie- en testsets. Krediet:Middlebrook &Sheik.
Twee studenten en onderzoekers van de Universiteit van San Francisco (USF) hebben onlangs geprobeerd om billboard-hits te voorspellen met behulp van machine learning-modellen. In hun studie hebben voorgepubliceerd op arXiv, ze trainden vier modellen op liedgerelateerde gegevens die zijn geëxtraheerd met behulp van de Spotify Web API, en evalueerde vervolgens hun prestaties bij het voorspellen welke nummers hits zouden worden.
"Ik ben een enorme muziekfan, en ik luister de hele dag naar muziek; tijdens mijn woon-werkverkeer, op het werk, en met vrienden, "Kai Middelbeek, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Vorige lente, Ik begon een onderzoeksproject over automatische classificatie van muziekgenres met professor David Guy Brizan aan de Universiteit van San Francisco (USF). Het project vereiste een grote hoeveelheid muziekgegevens, en populaire muziekstreamingdiensten hebben precies het soort gegevens dat ik nodig had."
Terwijl hij werkte aan een project met betrekking tot automatische classificatie van muziekgenres, Middlebrook ontdekte dat Spotify ontwikkelaars toegang geeft tot zijn muziekgegevens. Dit stimuleerde hem om te gaan experimenteren met de Spotify Web API om data te verzamelen voor zijn studie. Toen hij het onderzoek naar genreclassificatie voltooide, echter, hij zette de API enige tijd opzij.
"Een paar maanden later, mijn vriend Kyan, die ook datawetenschapper is en van muziek houdt, en ik had een discussie over muziek, ' zei Middlebrook. 'Op een bepaald moment tijdens het gesprek, het algemeen aanvaarde idee dat "alle hitnummers hetzelfde klinken" werd naar voren gebracht. We geloofden niet per se dat het waar was, maar het idee deed ons afvragen:wat als hitnummers enkele overeenkomsten vertonen? Het leek mogelijk, dus Kian en ik besloten om verder te onderzoeken."
Middlebrook en Sheik, die eerder hadden meegewerkt aan het genreclassificatieproject, besloten om nader onderzoek te doen met behulp van gegevens die zijn geëxtraheerd uit Spotify. Dit nieuwe project zou tevens de laatste opdracht zijn voor hun cursus datamining bij USF.
"We werkten samen aan verschillende andere projecten voor verschillende cursussen, dus het was logisch om bij elkaar te blijven, "Kian Sjeik, een andere onderzoeker die bij het onderzoek betrokken was, vertelde TechXplore. "Lil Nas X's hit "Old Town Road" was net uit het niets gekomen, en stond bovenaan de Billboard Hot 100. Kai en ik vroegen ons af of een computer zijn opkomst had kunnen voorspellen, of als het gewoon een hit was die uit het linkerveld kwam. Wat begon als een eenvoudig eindproject eindigde met het uitputten van alle state-of-the-art begeleide leermodellen op een grote dataset om een eenvoudige vraag te beantwoorden:wordt dit nummer een hit?"
In hun studie hebben Middlebrook en Sheik gebruikten de Spotify Web API om gegevens te verzamelen voor 1,8 miljoen nummers, met functies zoals het tempo van een nummer, toets, valentie, enz. Vervolgens verzamelden ze ook ongeveer 30 jaar aan gegevens van de Billboard Hot 100-kaart.
"Ons doel was om te zien of hitnummers vergelijkbare kenmerken hadden, en als het zo is, of die functies kunnen worden gebruikt om te voorspellen welke nummers in de toekomst hits zullen worden, ' zei Middelbeek.
De onderzoekers trainden en evalueerden vier verschillende modellen:een logistische regressie, een neuraal netwerk, een support vector machine (SVM) en een random forest (RF) architectuur. Tijdens de training, deze modellen analyseerden verschillende songkenmerken, inclusief tempo, toets, valentie, energie, akoestiek, dansbaarheid en luidheid.
"Als je een lied krijgt, onze modellen zouden het labelen met een één of een nul, Middlebrook legde uit. "Een nummer met het label een betekent dat het model voorspelt dat het nummer een hit was. Een nummer met een nul betekent dat het model voorspelt dat het nummer geen hit was."
Het door de onderzoekers getrainde logistische regressiemodel gaat ervan uit dat songdata lineair in twee categorieën kunnen worden verdeeld:hits en non-hits. Het model kent een gewicht toe aan elke songfunctie, en gebruikt vervolgens deze gewichten om te voorspellen of een nummer in de categorie "hit" of "non-hit" valt.
Logistische regressiemodellen hebben twee belangrijke voordelen:interpreteerbaarheid en snelheid. Met andere woorden, dit type architectuur maakt het gemakkelijker om de relatie tussen verklarende variabelen (d.w.z. de songkenmerken) en de responsvariabele (d.w.z. geraakt of niet geraakt), en het kan ook relatief snel worden getraind.
Het tweede model dat door de onderzoekers werd getraind, was een RF-architectuur. Dit model werkt door het combineren van een grote hoeveelheid bouwstenen die beslisbomen worden genoemd.
"Eigenlijk, een beslisboom kan worden gezien als een model dat een reeks ja/nee-vragen gebruikt om de gegevens te scheiden, " zei Middlebrook. "Ze zijn interpreteerbaar, maar gevoelig voor overfitting van de gegevens. Overfitting betekent dat een model de trainingsgegevens onthoudt door ze te nauw aan te passen. Het probleem met overfitting is dat het model de daadwerkelijke relatie tussen songkenmerken en songpopulariteit misschien niet leert, omdat de gegevens vaak irrelevante ruis bevatten."
Om het probleem van overfitting te voorkomen, het willekeurige bosmodel dat door Middlebrook en Sheik wordt gebruikt, combineert honderdduizenden beslissingsbomen, die elk worden getraind op een andere subset van de trainingsgegevens en een andere subset van de songkenmerken. Het model maakt dan een voorspelling (d.w.z. bepaalt of een nummer een hit of een non-hit is) door de voorspelling van elke boom te middelen en deze resultaten samen te voegen.
"In onze gebruikssituatie het voordeel van het random forest-model is de flexibiliteit, Middlebrook zei. "Het is flexibeler dan een lineair model (bijvoorbeeld logistische regressie)."
Het derde en vierde model dat door de onderzoekers is getraind, namelijk de SVM en neurale netwerkarchitecturen, zijn beide niet-lineair en dus moeilijker te interpreteren. Het SVM-model werkt door te proberen het "hypervlak" te vinden dat de gegevens het beste in de twee categorieën scheidt (d.w.z. treffers of niet-treffers). De neurale netwerkarchitectuur, anderzijds, gebruikt één verborgen laag met tien filters om van de songdata te leren.
Van de vier modellen die door Middlebrook en Sheik worden gebruikt, het logistische regressiemodel is het gemakkelijkst te interpreteren, terwijl het neurale netwerk het moeilijkst is. De andere twee modellen vallen ergens in het midden.
"Over het algemeen, deze modellen voorspellen op basis van beperkingen die ze ontwikkelen door training, " zei Sheik. "Elk model is getraind op dezelfde set sonische classifiers. De output van de modellen wordt getoetst aan de historische waarheid van de Billboard API, of het gegeven nummer ooit op de Billboard Hot 100-lijst is verschenen. We gebruikten een hele reeks computers bij USF om het rekenwerk te doen en na een paar weken puur rekenen, we hadden de optimale parameters voor elk model berekend."
De onderzoekers voerden een reeks evaluaties uit om te testen hoe goed de vier modellen billboardhits konden voorspellen. Ze ontdekten dat SVM-architectuur de hoogste precisie bereikte (99,53 procent), terwijl het random forest-model de beste nauwkeurigheid (88 procent) en recall-snelheid (85,51 procent) bereikte.
"Recall drukt de mogelijkheid uit om alle relevante instanties in een dataset te vinden, terwijl precisie uitdrukt welk deel van de gegevens waarvan ons model zegt dat het relevant was, daadwerkelijk relevant was, Middlebrook legde uit. Met andere woorden, recall vertelt ons hoe waarschijnlijk het is dat ons model een daadwerkelijke treffer nauwkeurig als treffer voorspelt. Precisie vertelt ons het deel van de voorspelde treffers die daadwerkelijk treffers waren."
Volgens de onderzoekers is als platenlabels een van deze modellen zouden gebruiken om te voorspellen welke nummers succesvoller zullen zijn, ze zouden waarschijnlijk een model met een hoge nauwkeurigheid kiezen dan een met een hoge nauwkeurigheid. Dit komt omdat een model met een hoge nauwkeurigheid minder risico's met zich meebrengt, omdat het minder waarschijnlijk is dat een niet-succesvol nummer een hit wordt.
"Recordlabels hebben beperkte middelen, Middlebrook zei. "Als ze deze middelen in een nummer gieten waarvan het model voorspelt dat het een hit zal worden en dat nummer dat nooit wordt, dan kan het label veel geld verliezen. Dus als een platenlabel wat meer risico wil nemen met de mogelijkheid om meer hits uit te brengen, ze kunnen ervoor kiezen om ons willekeurige bosmodel te gebruiken. Anderzijds, als een platenlabel minder risico wil nemen en toch wat hits wil uitbrengen, ze zouden ons SVM-model moeten gebruiken."
Middlebrook en Sheik ontdekten dat het voorspellen van een billboardhit op basis van kenmerken van de audio van een nummer, in feite, mogelijk. In hun toekomstig onderzoek de onderzoekers zijn van plan om andere factoren te onderzoeken die kunnen bijdragen aan het succes van liedjes, zoals aanwezigheid op sociale media, kunstenaarservaring, en labelinvloed.
"We kunnen ons een wereld voorstellen waarin platenlabels die constant op zoek zijn naar nieuw talent worden overspoeld met mixtapes en demo's van de "volgende hete artiesten, "" zei Sjeik. "Mensen hebben maar zoveel tijd om met menselijke oren naar muziek te luisteren, dus "kunstmatige oren, " zoals onze algoritmen, kan platenlabels in staat stellen een model te trainen voor het soort geluid dat ze zoeken en het aantal nummers dat ze zelf moeten overwegen aanzienlijk te verminderen."
Classifiers zoals die ontwikkeld door Middlebrook en Sheik zouden platenlabels uiteindelijk kunnen helpen om te beslissen in welke nummers ze moeten investeren. Hoewel het idee om machine learning te gebruiken om door demo's te bladeren, interessant kan zijn voor de muziekindustrie, Sheik waarschuwt dat het ook ongewenste gevolgen kan hebben.
"Hoewel dit een gunstige toekomst kan zijn, het vooruitzicht van een spreekwoordelijke "hakblok" waaraan kunstenaars zich moeten meten, heeft de potentie om een echokamer te worden, of een situatie waarin nieuwe muziek als oude muziek moet klinken om op de radio te worden uitgebracht, " Sheik zei. "Contentmakers op platforms zoals YouTube, die ook algoritmen gebruikt om te beslissen welke video's aan de massa worden getoond, hebben de valkuilen van het dwingen van kunstenaars om voor een machine te werken afgekeurd."
Volgens Sjeik, als bedrijven en producenten algoritmen gaan gebruiken om artistieke beslissingen te nemen, deze modellen moeten zo worden ontworpen dat ze de vooruitgang van de kunst niet belemmeren. De architecturen die zijn ontwikkeld door de twee onderzoekers van USF, echter, kunnen dit nog niet realiseren.
"Novelty bias en andere onorthodoxe kenmerken zullen moeten worden geïntroduceerd en uitgevonden om ervoor te zorgen dat muziek als geheel niet een culturele singulariteit benadert door toedoen van opportunisme, ' concludeerde Sjeik.
© 2019 Wetenschap X Netwerk
 Oorlog tegen plastic laat fabrikanten zich aan strohalmen vastklampen
Oorlog tegen plastic laat fabrikanten zich aan strohalmen vastklampen- NASA ziet tropische storm Cindy de Gulf Coast doordrenken
- Mijnbouw voor hernieuwbare energie kan een andere bedreiging voor het milieu zijn
- Q&A:Duurzaamheidsmanager over de voordelen van een verbod op plastic tassen
- Satellietgegevens geleide inspanning om Nepal te helpen herstellen van een reeks aardbevingen
Hoofdlijnen
- Ethiek Research Paper Onderwerpen
- Wat gebeurt er met de nucleaire envelop tijdens cytokinese?
Cytokinese is de verdeling van één cel in twee en is de laatste stap na de mitotische celcyclus in vier stadia. Tijdens cytokinese blijft de nucleaire envelop, of kernmembraan, die het gen
- Kan iemand zich herinneren dat hij geboren is?
- Frankrijk verzet zich tegen EU-verlenging van 5 jaar voor onkruidverdelger glyfosaat
- Wanneer werden DNA-testen het eerst gebruikt?
- Inheemse vissoorten lopen gevaar na verwijdering van water uit de Colorado-rivier
- Studie kan bijdragen aan toolbox voor resourcemanagers
- Ideeën voor het maken van een 3-D DNA-standaard voor middelbare school
- Onderzoek verduidelijkt de functie van de nucleaire hormoonreceptor in planten






 Facebook details politie voor seks, terreur, haat inhoud
Facebook details politie voor seks, terreur, haat inhoud- Nieuwe technologie voor geoptimaliseerde voedselverwerking
- NASA-astronaut beschrijft close call na mislukte lancering
- Onderzoekers vinden een nieuwe toepassing voor afval
- Willekeurige bewegingen helpen kleurdetecterende cellen om het juiste patroon te vormen
- Studie ontleedt opvattingen over kortetermijnvakantieverhuur
- Beter, krachtiger afdrukken met nanostructuren van silicium
- Onder het oppervlak:de (ultrakleine) structuur van silicium nanokristallen begrijpen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
