Wetenschap
Een multi-representatieve convolutionele neurale netwerkarchitectuur voor tekstclassificatie
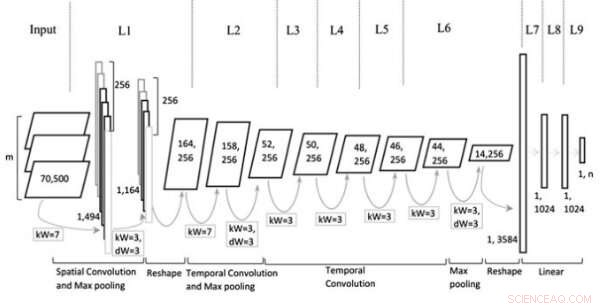
Model architectuur. Krediet:Jin et al, Wiley Computational Intelligence-tijdschrift.
In de afgelopen tien jaar of zo, convolutionele neurale netwerken (CNN's) hebben bewezen zeer effectief te zijn bij het aanpakken van een verscheidenheid aan taken, inclusief natuurlijke taalverwerking (NLP) taken. NLP omvat het gebruik van computertechnieken om taal te analyseren of te synthetiseren, zowel in geschreven als gesproken vorm. Onderzoekers hebben CNN's met succes toegepast op verschillende NLP-taken, inclusief semantische ontleding, het ophalen van zoekopdrachten en tekstclassificatie.
Typisch, CNN's die zijn opgeleid voor tekstclassificatietaken, verwerken zinnen op woordniveau, individuele woorden als vectoren voorstellen. Hoewel deze benadering consistent lijkt met hoe mensen taal verwerken, recente studies hebben aangetoond dat CNN's die zinnen op karakterniveau verwerken, ook opmerkelijke resultaten kunnen behalen.
Een belangrijk voordeel van analyses op karakterniveau is dat ze geen voorkennis van woorden vereisen. Dit maakt het voor CNN's gemakkelijker om zich aan verschillende talen aan te passen en abnormale woorden te verwerven die worden veroorzaakt door spelfouten.
Eerdere studies suggereren dat verschillende niveaus van tekstinbedding (d.w.z. karakter-, woord-, of -documentniveau) zijn effectiever voor verschillende soorten taken, maar er is nog steeds geen duidelijke leidraad voor het kiezen van de juiste inbedding of wanneer over te schakelen naar een andere. Met dit in gedachten, een team van onderzoekers van de Tianjin Polytechnic University in China heeft onlangs een nieuwe CNN-architectuur ontwikkeld op basis van soorten representatie die doorgaans worden gebruikt bij tekstclassificatietaken.
"We stellen een nieuwe architectuur van CNN voor op basis van meerdere representaties voor tekstclassificatie door meerdere vlakken te construeren zodat meer informatie in de netwerken kan worden gedumpt, zoals verschillende delen van tekst die zijn verkregen via een benoemde entiteitsherkenner of tagging-tools voor deel van spraak, verschillende niveaus van tekstinsluiting of contextuele zinnen, ’ schreven de onderzoekers in hun paper.
Het door de onderzoekers bedachte multi-representational CNN (Mr-CNN) model is gebaseerd op de veronderstelling dat alle delen van geschreven tekst (bijv. werkwoorden, enz.) een sleutelrol spelen bij classificatietaken en dat verschillende tekstinbeddingen effectiever zijn voor verschillende doeleinden. Hun model combineert twee belangrijke instrumenten, de Stanford Named Entity Herkenner (NER) en de Part-of-Speech (POS) tagger. De eerste is een methode voor het taggen van semantische rollen van dingen in teksten (bijv. persoon, bedrijf, enzovoort.); de laatste is een techniek die wordt gebruikt om woordsoorttags toe te kennen aan elk tekstblok (bijv. zelfstandig naamwoord of werkwoord).
De onderzoekers gebruikten deze tools om zinnen voor te verwerken, het verkrijgen van verschillende subsets van de oorspronkelijke zin, die elk specifieke soorten woorden in de tekst bevatten. Vervolgens gebruikten ze de subsets en de volledige zin als meerdere representaties voor hun Mr-CNN-model.
Bij evaluatie op tekstclassificatietaken met tekst uit verschillende grootschalige en domeinspecifieke datasets, het Mr-CNN-model behaalde opmerkelijke prestaties, met een maximum van 13 procent verbetering van het foutenpercentage op de ene dataset en een verbetering van 8 procent op een andere. Dit suggereert dat meerdere representaties van tekst het netwerk in staat stellen om adaptief zijn aandacht te richten op de meest relevante informatie, het verbeteren van de classificatiemogelijkheden.
"Diverse grootschalige, domeinspecifieke datasets werden gebruikt om de voorgestelde architectuur te valideren, " schreven de onderzoekers. "De geanalyseerde taken omvatten ontologiedocumentclassificatie, categorisatie van biomedische gebeurtenissen, en sentimentanalyse, waaruit blijkt dat multi-representatieve CNN's, die leren de aandacht te vestigen op specifieke representaties van tekst, kunnen verdere prestatiewinst behalen ten opzichte van geavanceerde diepe neurale netwerkmodellen."
In hun toekomstige werk, de onderzoekers zijn van plan te onderzoeken of fijnmazige functies kunnen helpen om overfitting van de trainingsdataset te voorkomen. Ze willen ook andere methoden verkennen die de analyse van specifieke delen van zinnen kunnen verbeteren, mogelijk de prestaties van het model verder verbeteren.
© 2019 Wetenschap X Netwerk
 Tweedelijnswetenschapslessen met zout
Tweedelijnswetenschapslessen met zout - Nieuw ontdekt quasikristal werd gecreëerd door de eerste nucleaire explosie op Trinity Site
- Waterstofenergie maken met het gewone nikkel
- Eindelijk synthetisch canataxpropellane:een van de meest complexe producten van de natuur reproduceren
- Humanitaire forensische wetenschappers sporen de vermiste, identificeer de doden en troost de levenden
Hoofdlijnen
- Volledige structuur van mitochondriaal respiratoir supercomplex gedecodeerd
- Celgroei en -deling: een overzicht van mitose en meiose
- Wat is de ergste uitsterving in de geschiedenis van de aarde?
- Een aap en een virus:een miljoen jaar samen
- In de strijd tegen virale infectie, spelling telt
- Fysische en chemische eigenschappen van lipiden
- Het verschil tussen glycolyse en gluconeogenese
- Deze 8 foto's van puppy's kunnen je helpen focussen,
- Detectorhonden bieden hoop om numbats te redden
- Als het gaat om de levensduur van smartphones, merknaam is belangrijker dan hardware

- Trapkracht:de opkomst van bakfietsen in Duitsland

- Geavanceerde Emotet-malwarelader die gedijt op niet-geavanceerde wachtwoorden

- Drones voor vroege detectie van bosbranden

- Waarom het verhogen van het alcoholgehalte van Europese brandstoffen de CO2-uitstoot kan verminderen?


 Relationele mobiliteit kan uw interpersoonlijke gedrag beïnvloeden
Relationele mobiliteit kan uw interpersoonlijke gedrag beïnvloeden- Een doorbraak op papier die sterker is dan staal
- Russische wetenschappers leren echografie kankercellen te vinden en te doden
- Microsoft en Amazon laten zien dat Cortana en Alexa met elkaar kunnen praten, in ieder geval op het podium van Build-conferentie
- Herziening van de geschiedenis van grote, klimaatveranderende vulkaanuitbarstingen
- De hitte blijft in juli in het grootste deel van de VS extra hoog
- Waarom moeten een buret en pipet worden gespoeld met de juiste oplossing voor een titratie?
- Studie in Ethiopië koppelt gezonde bodems aan voedzamere granen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
