Wetenschap
WayPtNav:een nieuwe benadering voor robotnavigatie in nieuwe omgevingen

De onderzoekers beschouwen het probleem van navigatie van een startpositie naar een doelpositie. Hun aanpak (WayPtNav) bestaat uit een leergebaseerde perceptiemodule en een dynamische modelgebaseerde planningsmodule. De waarnemingsmodule voorspelt een waypoint op basis van de huidige first-person RGB-beeldobservatie. Dit waypoint wordt door de modelgebaseerde planningsmodule gebruikt om een controller te ontwerpen die het systeem soepel naar dit waypoint stuurt. Dit proces wordt herhaald voor de volgende afbeelding totdat de robot het doel bereikt. Krediet:Bansal e al.
Onderzoekers van UC Berkeley en Facebook AI Research hebben onlangs een nieuwe aanpak ontwikkeld voor robotnavigatie in onbekende omgevingen. Hun aanpak, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, combineert modelgebaseerde besturingstechnieken met op leren gebaseerde perceptie.
De ontwikkeling van tools waarmee robots door de omgeving kunnen navigeren, is een belangrijke en voortdurende uitdaging op het gebied van robotica. In de afgelopen decennia, onderzoekers hebben geprobeerd dit probleem op verschillende manieren aan te pakken.
De controleonderzoeksgemeenschap heeft voornamelijk onderzoek gedaan naar navigatie voor een bekende agent (of systeem) binnen een bekende omgeving. In deze gevallen, een dynamisch model van de agent en een geometrische kaart van de omgeving waarin hij zal navigeren beschikbaar zijn, vandaar dat optimale controleschema's kunnen worden gebruikt om soepele en botsingsvrije trajecten te verkrijgen voor de robot om een gewenste locatie te bereiken.
Deze schema's worden doorgaans gebruikt om een aantal echte fysieke systemen te besturen, zoals vliegtuigen of industriële robots. Echter, deze benaderingen zijn enigszins beperkt, omdat ze expliciete kennis vereisen van de omgeving waarin een systeem zal navigeren. In de lerende onderzoeksgemeenschap, anderzijds, robotnavigatie wordt over het algemeen bestudeerd voor een onbekende agent die een onbekende omgeving verkent. Dit betekent dat een systeem beleid verwerft om de sensormetingen aan boord rechtstreeks in kaart te brengen voor het besturen van opdrachten op een end-to-end manier.
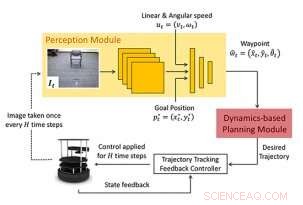
Voorgesteld kader:De nieuwe benadering van navigatie bestaat uit een op leren gebaseerde waarnemingsmodule en een op dynamische modellen gebaseerde planningsmodule. De perceptiemodule bestaat uit een CNN die een gewenste volgende status of waypoint uitvoert. Dit waypoint wordt door de modelgebaseerde planningsmodule gebruikt om een controller te ontwerpen om het systeem soepel naar het waypoint te sturen. Krediet:Bansal e al.
Deze benaderingen kunnen verschillende voordelen hebben, omdat ze het mogelijk maken om beleid te leren zonder enige kennis van het systeem en de omgeving waarin het zal navigeren. Niettemin, eerdere studies suggereren dat deze technieken niet goed generaliseren over verschillende middelen. In aanvulling, het leren van dergelijk beleid vereist vaak een groot aantal trainingsvoorbeelden.
"In deze krant, we bestuderen robotnavigatie in statische omgevingen onder de aanname van perfecte robottoestandmeting, " schreven de onderzoekers in hun paper. "We maken de cruciale opmerking dat de meeste interessante problemen een bekend systeem in een onbekende omgeving betreffen. Deze observatie motiveert het ontwerp van een gefactoriseerde benadering die leren gebruikt om onbekende omgevingen aan te pakken en optimale controle gebruikt met behulp van bekende systeemdynamiek om soepele voortbeweging te produceren."
Het team van onderzoekers van UC Berkeley en Facebook heeft een op convolutioneel neuraal netwerk (CNN) gebaseerd model getraind op beleid op hoog niveau, die huidige RGB-beeldwaarnemingen gebruiken om een reeks tussentoestanden te produceren, of 'waypoints'. Deze waypoints leiden een robot uiteindelijk naar de gewenste locatie langs een botsingsvrij pad, in voorheen onbekende omgevingen.
Hun aanpak, nagesynchroniseerde op waypoints gebaseerde navigatie (WayPtNav), koppelt in wezen modelgebaseerde controletechnieken aan op leren gebaseerde perceptie. De op leren gebaseerde waarnemingsmodule genereert waypoints, die de robot via een botsingsvrij pad naar zijn doellocatie leiden. De modelgebaseerde planner, anderzijds, gebruikt deze waypoints om een soepel en dynamisch haalbaar traject te genereren, die vervolgens op het systeem wordt uitgevoerd met behulp van feedbackregeling.
De onderzoekers evalueerden hun aanpak op een hardware-testbed, genaamd TurtleBot2. Hun tests leverden veelbelovende resultaten op, met WayPtNav voor navigatie in onoverzichtelijke en dynamische omgevingen, terwijl het ook beter presteert dan een end-to-end leerbenadering.
"Onze experimenten in gesimuleerde real-world rommelige omgevingen en op een echt grondvoertuig tonen aan dat de voorgestelde aanpak doellocaties betrouwbaarder en efficiënter kan bereiken in nieuwe omgevingen in vergelijking met een puur end-to-end, op leren gebaseerd alternatief, ’ schreven de onderzoekers.
De nieuwe benadering die door dit team van onderzoekers wordt gepresenteerd, zou de robotnavigatie in nieuwe binnenomgevingen kunnen verbeteren. Toekomstige studies zouden kunnen proberen WayPtNav verder te verbeteren, enkele van de huidige beperkingen aan te pakken.
"Onze voorgestelde aanpak gaat uit van een perfecte schatting van de robotstatus en maakt gebruik van een puur reactief beleid, " legden de onderzoekers uit. "Deze aannames en keuzes zijn misschien niet optimaal, vooral voor langeafstandstaken. Het opnemen van ruimtelijk of visueel geheugen om deze beperkingen aan te pakken, zou een vruchtbare toekomstige richting zijn."
© 2019 Wetenschap X Netwerk
 Nieuwe methode maakt het spinnen van collageenmicrovezels sneller, goedkoper, en gemakkelijker
Nieuwe methode maakt het spinnen van collageenmicrovezels sneller, goedkoper, en gemakkelijker- Een gevaarlijk gif veranderen in een biosensor
- Video:Hortensia's, de vreemde van kleur veranderende bloemen
- Fotochemische deracemisatie van chirale verbindingen bereikt
- Eierflotation Science Project Procedures
Hoofdlijnen
- Voors en tegens van Forensic Science
- Hoe is de concentratie van een oplossing van invloed op osmose?
- Genetische redding bevordert het herstel van de met uitsterven bedreigde Australische dwergbuidelmuizen
- Onverwachte regulatie van transcriptiefactoren die cruciaal zijn voor ontwikkeling
- Ezels hebben meer bescherming nodig tegen de winter dan paarden
- Dodelijke vispathogeen gedetecteerd in Australië
- Hoe het Jeruzalem-syndroom werkt
- (Her)verwerven van het potentieel om alles te worden
- Hoe werkt ureum denatureiwitten?
- British Airways ontslaat tijdelijk 28, 000 medewerkers:vakbond

- Porsche roept automodel terug voor de allerkleinsten

- WhatsApp verdedigt encryptie aangezien het meer dan 2 miljard gebruikers heeft

- Op een dag, een vliegtuig kan je vlieglessen geven

- Onderzoekers brengen Jedi-krachten tot leven met Force Push


 Nieuwe antenne in Alaska breidt de communicatiemogelijkheden van ruimtevaartuigen uit
Nieuwe antenne in Alaska breidt de communicatiemogelijkheden van ruimtevaartuigen uit- Een multidimensionaal beeld van SARS-CoV-2
- Wat betekent het woordproduct in wiskunde?
- Algoritmen en lasers temmen chemische reactiviteit
- Onderzoek suggereert dat T. rex een airconditioner in zijn hoofd had
- Grazende paarden op betere weiden
- Lasers brengen een revolutie teweeg in het in kaart brengen van bossen
- Zeer efficiënte interconversie van lading naar spin in grafeenheterostructuren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
