Wetenschap
Wetenschappers ontwikkelen AI om het succes van startende bedrijven te voorspellen
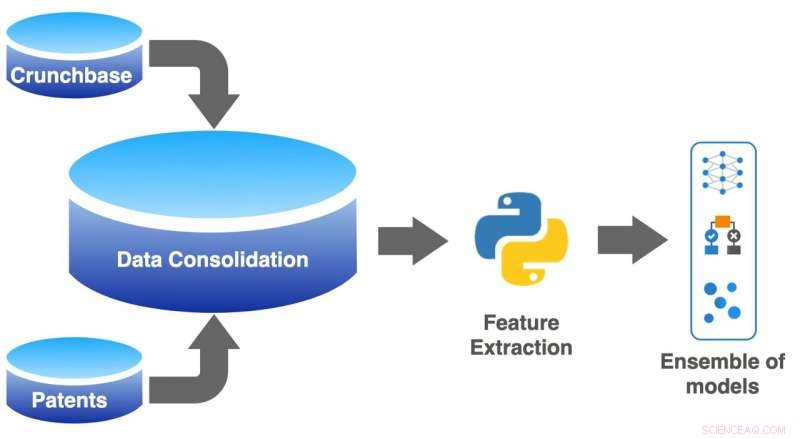
De machine learning-pijplijn die wordt gebruikt om de modellen te trainen. Krediet:Greg Ross
Een onderzoek waarin machine learning-modellen werden getraind om meer dan 1 miljoen bedrijven te beoordelen, heeft aangetoond dat kunstmatige intelligentie (AI) nauwkeurig kan bepalen of een startup-bedrijf zal mislukken of succesvol zal worden. Het resultaat is een hulpmiddel, Venhound, dat het potentieel heeft om investeerders te helpen de volgende eenhoorn te identificeren.
Het is algemeen bekend dat ongeveer 90% van de startups niet succesvol is:tussen 10% en 22% faalt in het eerste jaar, en dit vormt een aanzienlijk risico voor durfkapitalisten en andere investeerders in beginnende bedrijven. In een poging om vast te stellen welke bedrijven meer kans van slagen hebben, onderzoekers hebben machinale leermodellen ontwikkeld die zijn getraind op de historische prestaties van meer dan 1 miljoen bedrijven. hun resultaten, gepubliceerd in KeAi's The Journal of Finance and Data Science , laten zien dat deze modellen de uitkomst van een bedrijf tot 90% nauwkeurig kunnen voorspellen. Dit betekent dat potentieel 9 van de 10 bedrijven correct worden beoordeeld.
"Dit onderzoek laat zien hoe ensembles van niet-lineaire modellen voor machinaal leren toegepast op big data een enorm potentieel hebben om grote functiesets toe te wijzen aan bedrijfsresultaten, iets dat onhaalbaar is met traditionele lineaire regressiemodellen, " legt co-auteur Sanjiv Das uit, Professor in Finance en Data Science aan de Leavey School of Business van Santa Clara University in de VS.
De auteurs ontwikkelden een nieuw ensemble van modellen waarin de gecombineerde bijdrage van de modellen opweegt tegen het voorspellende potentieel van elk afzonderlijk. Elk model classificeert een bedrijf, door het in een van meerdere succescategorieën of een mislukkingscategorie met een specifieke waarschijnlijkheid te plaatsen. Bijvoorbeeld, een bedrijf kan zeer waarschijnlijk slagen als het ensemble zegt dat het 75% kans heeft om deel te nemen aan de IPO (beursgenoteerd) of 'overgenomen door een ander bedrijf', terwijl slechts 25% van zijn voorspelling in de mislukte categorie zou vallen.
De onderzoekers trainden de modellen op data afkomstig van Crunchbase, een crowd-sourced platform met gedetailleerde informatie over veel bedrijven. Ze trouwden met de Crunchbase-waarnemingen met patentgegevens van de USPTO (United States Patent and Trademark Office). Gezien het crowd-sourced karakter van Crunchbase, het was geen verrassing om te horen dat in de inzendingen van sommige bedrijven informatie ontbreekt. Deze observatie inspireerde de auteurs om de hoeveelheid ontbrekende informatie voor elk bedrijf te meten en deze waarde te gebruiken als input voor het model. Deze observatie bleek een van de meest kritische kenmerken te zijn bij het bepalen of een bedrijf zou worden overgenomen of anderszins zou falen.
Hoofdauteur Greg Ross van Venhound Inc. merkt op dat het ensemble van modellen, samen met nieuwe gegevensfuncties, "genereert een niveau van nauwkeurigheid, precisie en herinnering die andere vergelijkbare onderzoeken overtreft. Beleggers kunnen dit gebruiken om prospects snel te evalueren, potentiële rode vlaggen verhogen en beter geïnformeerde beslissingen nemen over de samenstelling van hun portefeuilles."
 Inosine zou een mogelijke route kunnen zijn naar het eerste RNA en de oorsprong van het leven op aarde
Inosine zou een mogelijke route kunnen zijn naar het eerste RNA en de oorsprong van het leven op aarde- Waarom scheren zelfs de scherpste scheermessen dof maakt
- Nieuwe fotokatalysatoren kunnen door zonne-energie aangedreven omzetting van koolstofdioxide in brandstof uitvoeren
- Xylitol en cellulose nanovezels maken van papierpasta – naar een groene en duurzame samenleving
- Met water over nanosnelwegen rijden
- We kunnen luchthavens niet uitbreiden nadat we een klimaatnoodtoestand hebben uitgeroepen - laten we in plaats daarvan overschakelen op koolstofarm transport
- Franse aardbevingsfout in kaart gebracht
- Onderzoek onderzoekt de impact van koraalverbleking op de kustlijn van West-Australië
- Onderzoekers identificeren bacteriën en virussen die uit de oceaan zijn uitgestoten
- Landbouw:een klimaatschurk? Misschien niet!
Hoofdlijnen
- Niet zo koude eend? Man blijft zoeken naar uitgestorven vogel
- Meer waarnemingen van een bedreigde diersoort betekent niet altijd dat deze zich herstelt
- Een geslacht van Europese papierwespen voor het eerst herzien met behulp van integratieve taxonomie
- Alle informatie die nodig is om proteïnen te maken is gecodeerd in DNA door wat?
- Hoe een bloeiende legale marihuana-industrie de luchtkwaliteit kan schaden
- Ideeën voor Cookie Science Fair Projects
- Wat is een chromosoom?
- Waar bevindt het DNA zich in een cel?
- Wat is de elektrische impuls die een Axon naar beneden beweegt?
- Kosten om een jaar weg te lopen van Facebook? Meer dan $1, 000, nieuwe studie vondsten

- Voedselprijzen na harde Brexit kunnen met 50 GBP per week stijgen

- Een eerste blik op thermostaatoorlogen suggereert dat vrouwen deze gevechten misschien aan het verliezen zijn

- Het welzijn van leerlingen begint af te nemen vanaf het moment dat ze naar de middelbare school gaan

- Abba:Wie vindt ze eigenlijk leuk?


 Wetenschappers ontwikkelen op wolfraam gebaseerde waterstofdetectoren
Wetenschappers ontwikkelen op wolfraam gebaseerde waterstofdetectoren- Projectiesysteem om het zicht van insecten te bestuderen kan leiden tot nieuwe navigatiehulpmiddelen
- Hoogwaardige polarisatiegevoelige fotodetectoren op 2D-halfgeleider
- Supergeleidende sondes gebruiken om een beeld te krijgen van hoe het er in CNT's uitziet
- Het toelatingssysteem voor de middelbare school is nog steeds een werk in uitvoering
- Hoe te vertellen of een pauw mannelijk of vrouwelijk is
- Investeringen in de autosector in het VK storten in door de impact van de Brexit:gegevens uit de sector
- Onderzoekers bevorderen de productie van zonnemateriaal
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Norway | Swedish |

-
Wetenschap © https://nl.scienceaq.com
