Wetenschap
TACC COVID-19 twitter-dataset maakt sociaalwetenschappelijk onderzoek naar pandemie mogelijk
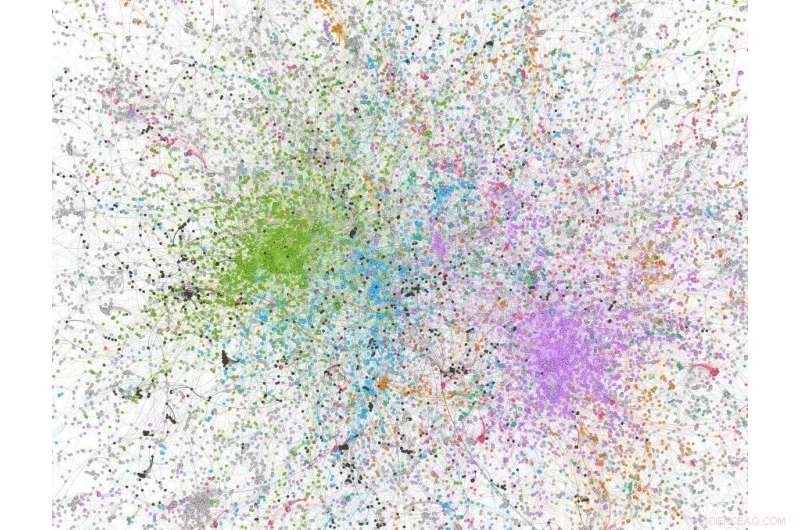
Netwerkanalysecijfer afgeleid van een steekproef van 100, 000 tweets met 'covid' in de tweet; groen gekleurd knooppunten zijn alt-rechts/sterk conservatieve Twitter-gebruikers/organisaties. Krediet:Dhiraj Murthy, UT Austin
Van de talloze manieren waarop onderzoekers de verspreiding van het coronavirus bestrijden, het bestuderen van Tweets is misschien niet de eerste die in je opkomt. Maar nu, zoals in eerdere crises, gebruik maken van een van 's werelds toonaangevende realtime berichtenservices kan helpen bij het identificeren van nieuwe pandemische hotspots, markeer nieuwe symptomen, of interpreteren hoe mensen en gemeenschappen reageren op bevelen om sociale afstand te nemen.
Het deskundige data science-team van het Texas Advanced Computing Center (TACC) heeft in het verleden de analyse van sociale media gefaciliteerd, en heeft machine learning-tools ontwikkeld om naalden van inzicht beter uit de enorme hooibergen van de Twitterverse te trekken.
Vanaf maart, TACC begon dagelijks grote hoeveelheden tweets op te nemen - ongeveer 40 miljoen berichten, waarvan één miljoen uniek. Door hun collectie te combineren met soortgelijke inspanningen van groepen op UT Austin, de Universiteit van Zuid-Californië, en George State University, ze hebben hun verzameling COVID-19-gerelateerde tweets uitgebreid tot januari. (Vorige week, Twitter heeft aangekondigd dat het nieuwe API-eindpunten zou vrijgeven voor zijn eigen COVID-19-gerelateerde tweetverzameling voor goedgekeurde ontwikkelaars en onderzoekers.)
"Er is veel belangstelling voor dit soort collecties. Het is erg handig in datawetenschap, " zei Weijia Xu, die de Scalable Computational Intelligence-groep bij TACC beheert.
Vandaag, TACC heeft een nieuwe GitHub-repository aangekondigd waar geïnteresseerde onderzoekers toegang hebben tot zowel verwijzingen naar onbewerkte Twitter-gegevens met betrekking tot COVID-19 als grootschalige analyses die worden gefaciliteerd door de supercomputers van TACC.
De eerste van de beschikbare analyses voor onderzoekers is een set van n-grammen:aaneengesloten reeksen woorden uit een bepaalde steekproef van tweets. de top 1, 000 een-, twee-, en voor elke dag van de pandemie zijn reeksen van drie woorden samengesteld. Het samenstellen van zelfs een enkele gram van enkele miljoenen tweets kan tot een uur duren op een laptop vanwege de hoeveelheid gegevensverwerking die ermee gemoeid is, maar kan in enkele minuten worden gedaan op de supercomputers van TACC.
Het TACC-onderzoeksteam, geleid door Xu, heeft ook gewerkt aan analyses van onderwerpmodellering, het identificeren van termen die vaak in verband met elkaar voorkomen, hoewel niet noodzakelijk in orde. Deze zullen in de komende weken worden toegevoegd aan de GitHub-repository.
Beide clusteringmethoden kunnen nuttig zijn bij het identificeren van trends in de manier waarop de pandemie, en de reactie van mensen daarop, zijn aan het evolueren.
Toekomstige projecten die de gegevens gebruiken, omvatten een doorzoekbare openbare database; entiteitsanalyse:het inspecteren van tweets op bekende entiteiten zoals publieke figuren of organisaties en het teruggeven van informatie over die entiteiten; en gebeurtenisdetectie:het automatisch detecteren van gebeurtenissen en deze categoriseren.
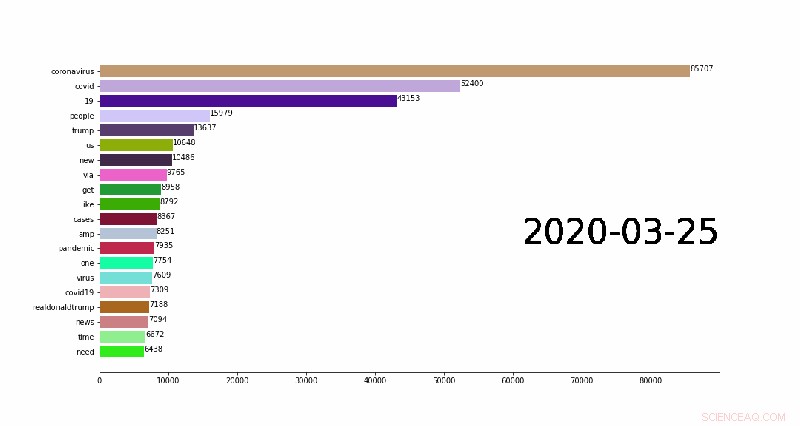
Een animatie die de top 20 dagelijkse n-grammen (veelvoorkomende woorden in Twitter-post) laat zien die overuren veranderen. Krediet:Weijia Xu, TACC
Deze inspanningen zullen worden vergemakkelijkt door instrumenten die zijn ontwikkeld bij TACC, zoals het project Domain Information &Vocabulary Extraction, een door de National Science Foundation gefinancierde inspanning om biologische entiteiten uit publicaties en andere tekstdocumenten te extraheren met behulp van machine learning, die is aangepast voor andere soorten extractie.
TACC's belangrijkste doel - hier, zoals bij de meeste dingen - is om het onderzoek van anderen te vergemakkelijken en ontdekkingen kracht bij te zetten. "We zijn vooral geïnteresseerd om mensen toegang te geven tot samengestelde datasets en hen te helpen bij het doen van onderzoek, " zei Xu. "We zijn aan het verzamelen, schoonmaken, en het verwerken van gegevens zodat het klaar is voor gebruik door anderen."
Onderzoekers van de Universiteit van Texas in Austin (UT Austin) behoren tot de eersten die interesse tonen in het gebruik van de TACC COVID-19 Twitter-datasets voor gericht onderzoek.
"De TACC COVID-19 Twitter-collectie zal van onschatbare waarde zijn om ons in staat te stellen communicatiepatronen en onderwerpen te modelleren die zich voordoen in verschillende stadia van de ziekte, " said Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."
 Nieuwe methode helpt orthotope beeldvorming van hersentumoren duidelijker en sneller te maken
Nieuwe methode helpt orthotope beeldvorming van hersentumoren duidelijker en sneller te maken- Slimme diëlektrische elastomeren voor zelfherstellende zachte robots
- Hoe snelheid te berekenen van temperatuur
- Kristallen kweken om willekeurige getallen te genereren
- Een schokgeïnduceerd mechanisme voor het maken van organische moleculen
- Onderzoek naar aardbevingen in Kaikoura suggereert nieuwe benadering van aardbevingsvoorspelling
- Explosieve uitbarstingen bij vulkaan Japan
- Sterke aardbeving schudt West-Indonesië; geen tsunami-alarm
- Wijdverbreide degradatie van permafrost gezien in hoog Arctisch terrein
- De onderwateroerwouden van de zee geven helderder water
Hoofdlijnen
- Onderzoekers brengen druggable genomische doelwitten in kaart in evoluerende malariaparasieten
- Studie lost waarom drinken je de munchies geeft
- Eenmaal uitgestorven verklaard, Lord Howe Island wandelende takken leven echt
- BigH1 - de belangrijkste histon voor mannelijke vruchtbaarheid
- Het genoom van Leishmania onthult hoe deze parasiet zich aanpast aan veranderingen in de omgeving
- Turkije bevrijdt 7, 500 illegaal opgejaagde kikkers de rivier in
- Nieuwe bevindingen verduidelijken de rol van de schildklier bij seizoensveranderingen bij zoogdieren
- Wat is de rol van glucose in het lichaam?
- Gletsjermuizen bewegen en dat heeft wetenschappers versteld doen staan
- Kunnen financiële prikkels de toegang tot de gezondheidszorg in India gelijk maken?

- Duitsland:Geen voorbereidingen getroffen in geval van buitenaardse landing

- Politieagenten zeer gemotiveerd door toezicht door supervisor

- Oude genomica lokaliseert de oorsprong en snelle omzet van vee in de Vruchtbare Halve Maan

- Mijn buik is boos, mijn keel is verliefd:lichaamsdelen en emoties in inheemse talen


 Baanbrekende ontdekking van inkt kan de productie van nieuwe laser- en opto-elektronische apparaten transformeren
Baanbrekende ontdekking van inkt kan de productie van nieuwe laser- en opto-elektronische apparaten transformeren- Wat is een stroomdiagram van kunststof?
- VS missen doelstelling klimaatpact Parijs met een derde
- Twee manieren om optische waarneming te verbeteren met verschillende resonatortechnieken
- Single fotonen emissie van geïsoleerde monolaag eilanden van InGaN
- De Noordelijke IJszee kan in 2044 een deel van het jaar ijsvrij zijn
- Lezen meisjes beter dan jongens? Als, genderstereotypen kunnen de schuld zijn
- Difference Between Muriatic & Sulphuric Acid
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
