Wetenschap
Wiskundigen stellen een nieuwe manier voor om neurale netwerken te gebruiken om te werken met lawaaierige, hoogdimensionale gegevens
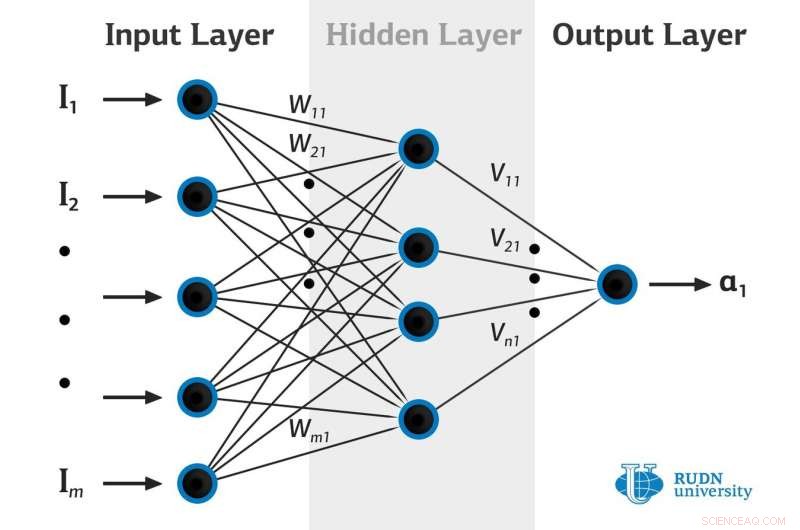
Krediet:RUDN University
Wiskundigen van de RUDN Universiteit en de Vrije Universiteit van Berlijn hebben een nieuwe benadering voorgesteld voor het bestuderen van de kansverdelingen van waargenomen gegevens met behulp van kunstmatige neurale netwerken. De nieuwe aanpak werkt beter met zogenaamde uitbijters, d.w.z., invoergegevensobjecten die aanzienlijk afwijken van de totale steekproef. Het artikel is gepubliceerd in het tijdschrift Kunstmatige intelligentie .
Het herstel van de kansverdeling van waargenomen gegevens door kunstmatige neurale netwerken is het belangrijkste onderdeel van machine learning. De kansverdeling stelt ons niet alleen in staat om het gedrag van het bestudeerde systeem te voorspellen, maar ook om de onzekerheid waarmee prognoses worden gemaakt te kwantificeren. De grootste moeilijkheid is dat, als een regel, alleen de gegevens worden waargenomen, maar hun exacte kansverdelingen zijn niet beschikbaar. Om dit probleem op te lossen, Bayesiaanse en andere vergelijkbare benaderingsmethoden worden gebruikt. Maar het gebruik ervan verhoogt de complexiteit van een neuraal netwerk en maakt daarom de training ingewikkelder.
RUDN University en de Vrije Universiteit van Berlijn wiskundigen gebruikten deterministische gewichten in neurale netwerken, die zou helpen de beperkingen van Bayesiaanse methoden te overwinnen. Ze ontwikkelden een formule waarmee men de variantie van de verdeling van de waargenomen gegevens correct kan inschatten. Het voorgestelde model is getest op verschillende gegevens:synthetisch en echt; op gegevens met uitbijters en op gegevens waarvan de uitbijters zijn verwijderd. Met de nieuwe methode kunnen kansverdelingen worden hersteld met een nauwkeurigheid die voorheen onhaalbaar was.
De wiskundigen van de RUDN Universiteit en de Vrije Universiteit van Berlijn gebruikten deterministische gewichten voor neurale netwerken en gebruikten de netwerkuitgangen om de verdeling van latente variabelen te coderen voor de gewenste marginale verdeling. Een analyse van de trainingsdynamiek van dergelijke netwerken stelde hen in staat een formule te verkrijgen die de variantie van de waargenomen gegevens correct schat, ondanks de aanwezigheid van uitbijters in de data. Het voorgestelde model is getest op verschillende gegevens:synthetisch en echt. Met de nieuwe methode kunnen kansverdelingen met een hogere nauwkeurigheid worden hersteld in vergelijking met andere moderne methoden. De nauwkeurigheid werd beoordeeld met behulp van de AUC-methode (gebied onder de curve is het gebied onder de grafiek waarmee de gemiddelde kwadratische fout van de voorspellingen kan worden beoordeeld, afhankelijk van de steekproefomvang die door het netwerk als "betrouwbaar" wordt geschat; hoe hoger de AUC-score, hoe beter de voorspellingen).
 Goed nieuws:habitats die bescherming verdienen in Duitsland worden beschermd
Goed nieuws:habitats die bescherming verdienen in Duitsland worden beschermd- Persoonlijke netwerken worden geassocieerd met het gebruik van schone brandstof voor het koken op het platteland van Zuid-India
- Prioriteit geven aan hulp aan de armsten die getroffen zijn door dodelijke natuurrampen
- Heeft orkaan Barry een bijna-record dode zone voorkomen?
- Japan kan radioactief water van Fukushima in het milieu vrijgeven
Hoofdlijnen
- De centrale hoek vinden
- Gemuteerd kikkergen stoot roofdieren af
- Het verzoenen van taxonveroudering met de Red Queens-hypothese
- Wetenschapsprojecten over Dominant en Recessieve Genen
- Menselijke schedelgroei
- Kan eten mensen gelukkig maken?
- Overlevingsstrategie van boodschapper-RNA's tijdens cellulair suikertekort
- Ideeën voor het maken van een 3D-model van een cel
- Natte celbatterij versus Dry Cell Battery
- 6, 000 jaar oud monument biedt een verleidelijke glimp van de neolithische beschaving van Groot-Brittannië

- Individueel zelfmoordrisico kan drastisch worden veranderd door sociale gelijkheid, studie vondsten

- DC-charters bieden innovaties in het onderwijs in het pandemische tijdperk

- Illegale jagers vormen een groter probleem op boerderijen dan dierenactivisten

- Wat betekent complementair in wiskunde?


 Luchthaven Denvers heropent na krachtige winterstorm (update)
Luchthaven Denvers heropent na krachtige winterstorm (update)- bosbranden, rook snuff out outdoor-avonturen in de VS
- Projectideeën voor natuurrampen
- Google verlaagt de prijzen voor opslag onder een nieuwe naam. Dit is hoe Google One zich verhoudt tot zijn rivalen
- Nissan streeft naar schone lei met vertrek van CEO maar uitdagingen blijven
- Frankrijk luchtverkeer verantwoordelijk voor een derde van de vertragingen in Europa:rapport
- Mars InSight-lander om bovenop de mol te duwen
- India plant bemande ruimtemissie in december 2021
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
