Wetenschap
Domeinkennis stimuleert datagestuurde kunstmatige intelligentie bij het loggen van boorputten
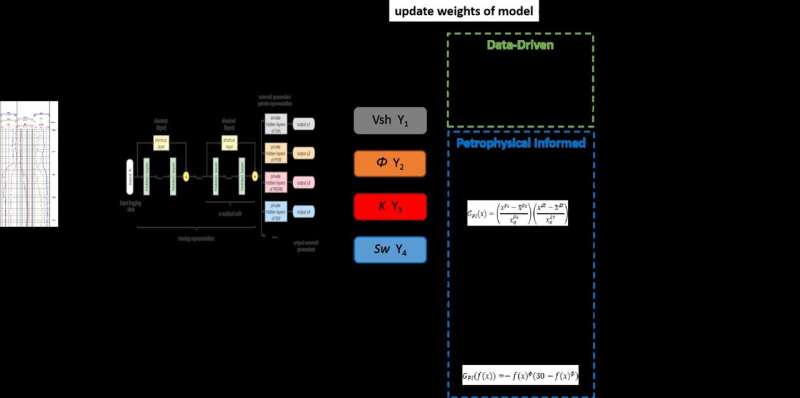
Datagestuurde kunstmatige intelligentie, zoals deep learning en versterkend leren, beschikt over krachtige mogelijkheden voor data-analyse. Deze technieken maken de statistische en probabilistische analyse van gegevens mogelijk, waardoor het in kaart brengen van relaties tussen inputs en outputs wordt vergemakkelijkt zonder te vertrouwen op vooraf bepaalde fysieke aannames.
Centraal in het proces van het trainen van datagestuurde modellen is het gebruik van een verliesfunctie, die de ongelijkheid berekent tussen de output van het model en de gewenste doelresultaten (labels). De optimalisatie past vervolgens de parameters van het model aan op basis van de verliesfunctie om het verschil tussen de uitvoer en labels te minimaliseren.
Ondertussen omvat geofysische houtkap een schat aan domeinkennis, wiskundige modellen en fysieke modellen. Het uitsluitend vertrouwen op datagestuurde modellen kan soms uitkomsten opleveren die in tegenspraak zijn met gevestigde kennis. Bovendien kunnen trainingsgegevens met een ongelijkmatige verdeling en subjectieve labels ook van invloed zijn op de prestaties van datagestuurde modellen.
Een recente studie gepubliceerd in Artificial Intelligence in Geoscience rapporteerde de implementatie van beperkingen op de training van datagestuurde machine learning-modellen met behulp van log-responsfuncties bij het loggen van reservoirparameter-voorspellingstaken.
"Ons model, genaamd Petrophysics Informed Neural Network (PINN), integreert petrofysische beperkingen in de verliesfunctie om training te begeleiden", zegt de eerste auteur van het onderzoek, Rongbo Shao, een Ph.D. kandidaat van de Chinese Universiteit van Petroleum-Beijing. "Als tijdens modeltraining de modeluitvoer verschilt van petrofysische kennis, wordt de verliesfunctie bestraft door petrofysische beperkingen. Dit brengt de output dichter bij de theoretische waarde en vermindert de impact van labelfouten op modeltraining."
Bovendien helpt deze aanpak bij het onderscheiden van de juiste relaties uit trainingsgegevens, vooral als het om kleine steekproeven gaat.
"We introduceren toegestane fout- en petrofysische beperkingsgewichten om de invloed van mechanismemodellen in het machine learning-model flexibeler te maken", legt Shao uit. "We hebben het vermogen van het PINN-model om reservoirparameters te voorspellen geëvalueerd met behulp van gemeten gegevens."
Shao en zijn collega's ontdekten dat het model de nauwkeurigheid en robuustheid heeft verbeterd in vergelijking met pure datagestuurde modellen. Desalniettemin merkten de onderzoekers op dat het selecteren van petrofysische beperkingsgewichten en toegestane fouten subjectief blijft en daarom verder onderzoek vereist.
Corresponderend auteur prof. Lizhi Xiao van de China University of Petroleum onderstreept het belang van dit onderzoek:“Het integreren van datagestuurde AI-modellen met kennisgestuurde mechanismemodellen is een veelbelovend onderzoeksgebied. Het succes van het PINN-model bij het loggen van boorputten is een belangrijke stap voorwaarts. voor de geowetenschappen in deze richting."
Xiao benadrukt de noodzaak van voortdurende verfijning:“De selectie van petrofysische beperkingsgewichten en toegestane fouten, evenals het aanpassingsvermogen van domeinkennis aan verschillende geologische lagen, zorgen voor voortdurende uitdagingen. Bovendien is de kwaliteit van datasets cruciaal voor de toepassing van AI in Er zijn uitgebreide, openbaar beschikbare datasets voor putregistratie met hoge kwaliteit en kwantiteit nodig."