Wetenschap
Een op deep learning gebaseerde methode om cyberpesten op Twitter te detecteren
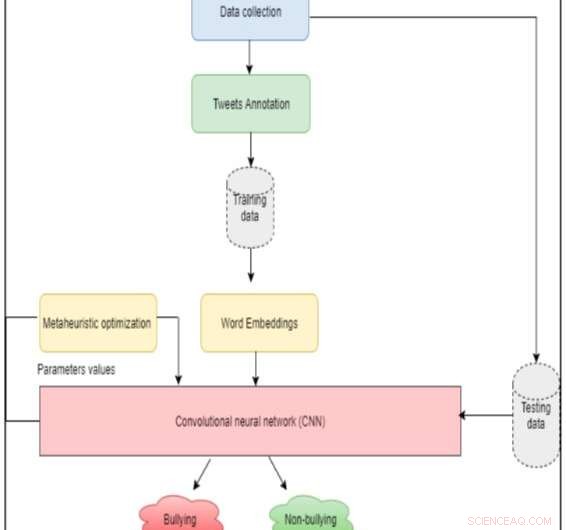
De architectuur van het systeem. Krediet:Al-Ajlan &Ykhlef.
Onderzoekers van de King Saud University, in Saudi Arabie, hebben een nieuwe aanpak ontwikkeld om cyberpesten op Twitter te detecteren met behulp van deep learning, OCDD genaamd. In tegenstelling tot andere benaderingen van diep leren, die functies uit tweets halen en deze naar een classifier voeren, hun methode vertegenwoordigt een tweet als een set woordvectoren.
In recente jaren, cyberpesten op sociale media is een enorm en veelbesproken probleem geworden. Cyberpesten omvat het gebruik van online communicatiekanalen om andere gebruikers te pesten door intimiderende, bedreigende of beledigende berichten. Dit kan psychologische en soms levensbedreigende gevolgen hebben voor de slachtoffers.
Wereldwijd proberen onderzoekers nieuwe manieren te ontwikkelen om cyberpesten op te sporen, beheren en de prevalentie ervan op sociale media verminderen. Veel deep learning-benaderingen om cyberpesten te identificeren door tekst- en gebruikersfuncties te analyseren. Echter, deze technieken hebben verschillende beperkingen, die hun prestaties aanzienlijk kunnen verminderen.
Bijvoorbeeld, sommige van deze benaderingen proberen de detectie te verbeteren door nieuwe functies te introduceren. Maar het vergroten van het aantal features kan de fases voor het extraheren en selecteren van features bemoeilijken. Bovendien, deze benaderingen gaan er niet van uit dat sommige gebruikersgegevens, zoals leeftijd en geboortedatum, gemakkelijk kan worden gefabriceerd. Om de beperkingen van bestaande detectiemethoden voor cyberpesten aan te pakken, Monirah A. Al-Ajlan en Mourad Ykhlef, twee onderzoekers van de King Saud University, stelde een nieuwe aanpak voor genaamd geoptimaliseerde Twitter cyberpestendetectie (OCDD).
"In tegenstelling tot eerder werk op dit gebied, OCDD haalt geen kenmerken uit tweets en voert ze naar een classifier:in plaats daarvan het vertegenwoordigt een tweet als een set woordvectoren, " leggen de onderzoekers uit in hun paper, gepubliceerd op IEEE Explore en gepresenteerd op de 21 NS Saudi Computer Society Nationale Computerconferentie (NCC). "Op deze manier, de semantiek van woorden blijft behouden, en de fases voor het extraheren en selecteren van kenmerken kunnen worden geëlimineerd."
Al-Ajlan en Ykhlef bouwden hun aanpak op gelabelde trainingsgegevens en genereerden woordinsluitingen voor individuele woorden met GloVe, een niet-gesuperviseerd leeralgoritme dat vectorrepresentaties voor woorden kan verkrijgen. Deze woordinbeddingen worden vervolgens naar een convolutioneel neuraal netwerk (CNN) gevoerd om te detecteren of ze in verband kunnen worden gebracht met cyberpesten.
CNN-algoritmen bestaan meestal uit een invoer- en uitvoerlaag, evenals verschillende andere lagen. Het handmatig instellen van parameters voor elk van deze lagen kan een tijdrovende en uitdagende taak zijn. De onderzoekers besloten daarom een metaheuristisch optimalisatie-algoritme in hun model op te nemen, die dit proces kan vergemakkelijken door optimale of bijna optimale waarden te identificeren die voor classificatie moeten worden gebruikt.
"OCDD verbetert de huidige staat van detectie van cyberpesten door de moeilijke taak van het extraheren/selecteren van functies te elimineren en te vervangen door woordvectoren die de semantiek van woorden vastleggen en CNN dat tweets op een intelligentere manier classificeert dan traditionele classificatie-algoritmen, ' schrijven de onderzoekers in hun paper.
Wanneer getest op text mining-taken, OCDD behaalde veelbelovende resultaten. Echter, het moet nog worden geïmplementeerd en geëvalueerd binnen de context van detectie van cyberpesten. De onderzoekers zijn nu van plan hun aanpak aan te passen, zodat deze ook tekst in het Arabisch kan analyseren.
© 2019 Wetenschap X Netwerk
 Amerikaanse functionarissen worden geconfronteerd met toenemende druk over het gebruik van dicamba-herbiciden
Amerikaanse functionarissen worden geconfronteerd met toenemende druk over het gebruik van dicamba-herbiciden- De achteruitgang van het Caribische koraalrif begon in de jaren vijftig en zestig door lokale menselijke activiteiten
- EPA trekt beleid uit het Trump-tijdperk in dat de regels voor schone lucht versoepelde
- Zeven staten zoeken Amerikaanse steun voor droogteplan Colorado River
- Aerosoldeeltjes koelen het klimaat minder af dan we dachten
Hoofdlijnen
- Angiosperm versus Gymnosperm: wat zijn de overeenkomsten & verschillen?
- Osmose: definitie, proces, voorbeelden
- Verschil tussen homozygoot en heterozygoot
- Nieuwe studie wijst op onverwachte voordelen van rabiësvaccinatie bij honden
- Wanneer stopt het leven op aarde?
- Verkoudheidsvirussen onthullen een van hun sterke punten
- Dennen kappen:eerder vroeger dan later doen is beter voor fynbos
- Een onwaarschijnlijke held vergiftigen bij het afweren van exotische indringers?
- Minder gewassen voeden wereldwijd meer mensen - en dat is niet goed
- Ons digitale erfgoed beschermen in het tijdperk van cyberdreigingen

- Japanse SoftBank geschokt door WeWork, maar miljarden uitgeven

- VPN-providers pakken bevindingen van kwetsbaarheden door onderzoekers aan

- Fabricage van meer dan 7nm . mogelijk maken
- Ontwerpen van stedelijke energiesystemen op basis van het stadsklimaat

 Wereldwijde samenwerking leidt tot 3D-geprinte veldtestkit
Wereldwijde samenwerking leidt tot 3D-geprinte veldtestkit- Afbeelding:Robotachtige vultrechter
- Afstemming van reactiebarrières voor elektroreductie van kooldioxide tot producten met meerdere koolstofatomen
- Bandicoots overleefden eeuwen van veranderende klimaten,
- Food Speech Topics
- Etnische diversiteit op scholen kan goed zijn voor de cijfers van leerlingen, studie suggereert:
- Wat is een geleidbaarheidsmeter?
- Plunderaars plunderen gezonken schatten van Albanië
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
