Wetenschap
AlphaZero AI-systeem in staat om zichzelf te leren games te spelen, speel op het hoogste niveau

Beginnend met willekeurig spelen en gezien geen domeinkennis behalve de spelregels, AlphaZero versloeg op overtuigende wijze een programma van wereldkampioenen in zowel schaken en shogi (Japans schaken) als Go. Krediet:DeepMind Technologies Ltd
Een team van onderzoekers van de DeepMind-groep en University College, zowel in het VK, heeft een AI-systeem ontwikkeld dat zichzelf drie moeilijke bordspellen kan leren spelen en beheersen. In hun artikel gepubliceerd in het tijdschrift Wetenschap , de groep beschrijft hun nieuwe systeem en legt uit waarom ze denken dat het een nieuwe grote stap voorwaarts is in de ontwikkeling van AI-systemen. Murray Campbell van het T.J Watson Research Center in de VS biedt in hetzelfde tijdschriftnummer een Perspective-artikel over het werk van het team.
Het is meer dan 20 jaar geleden dat een supercomputer, bekend als Deep Blue, wereldkampioen schaken Gary Kasparov versloeg. de wereld laten zien hoe ver AI-computing was gekomen. In de jaren daarna, computers zijn steeds slimmer geworden en verslaan nu mensen bij spellen als schaken, shogi en Go. Maar dergelijke systemen zijn allemaal aangepast om ze echt goed te maken in slechts één game. In deze nieuwe poging de onderzoekers hebben een AI-systeem gemaakt dat niet alleen goed is in meer dan één game, maar verwerft dergelijke expertise op zijn eigen.
Het nieuwe systeem, genaamd AlphaZero, is een versterkend leersysteem, die, zoals de naam al aangeeft, betekent dat het leert door herhaaldelijk een spel te spelen en te leren van zijn ervaringen. Dit is, natuurlijk, vergelijkbaar met hoe mensen leren. Er wordt een basisset met regels opgesteld en vervolgens speelt de computer het spel - met zichzelf. Het hoeft niet eens met andere partners te spelen. Het speelt zichzelf herhaaldelijk af, opmerken welke spelen goede zetten zijn en dus winnen, en die slechte zetten en verliezen vormen. Overuren, het verbetert. Eventueel, het wordt zo goed dat het niet alleen mensen kan verslaan, maar andere speciale bordspel-AI-systemen. Het systeem gebruikte ook een zoekmethode die bekend staat als de Monte Carlo-boomzoekmethode. Door de twee technologieën te combineren, kan het systeem zichzelf leren hoe het beter kan worden in het spelen van games. De onderzoekers gaven hun testsysteem veel kracht, ook, door 5000 tensorverwerkingseenheden in te zetten, waardoor het op één lijn staat met grote supercomputers.
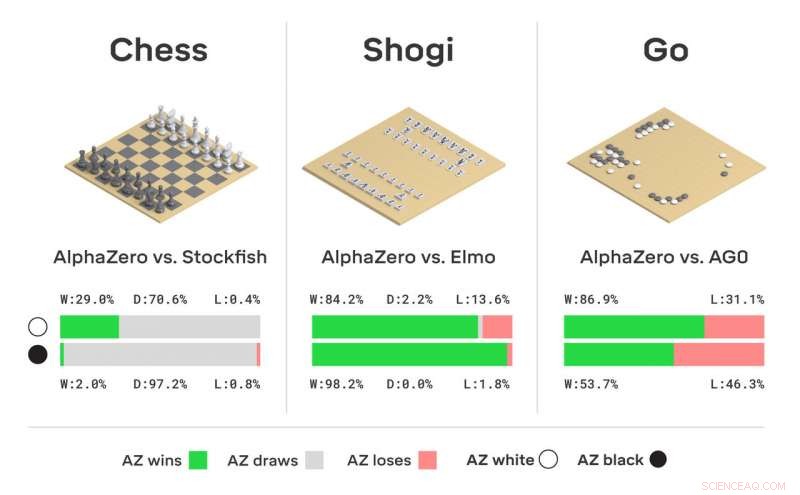
Toernooievaluatie van AlphaZero in schaken, shogi, en gaan, als gewonnen wedstrijden, getekend of verloren vanuit het perspectief van AlphaZero, in wedstrijden tegen Stockfish, Elmo, en AlphaGo Zero (AG0) die drie dagen werd getraind. Krediet:DeepMind Technologies Ltd
Zo ver, AlphaZero beheerst het schaken, shogi en Go—games die bijzonder geschikt zijn voor AI-toepassingen. Campbell suggereert dat de volgende stap voor dergelijke systemen zou kunnen zijn om uit te breiden naar spellen zoals poker, of zelfs populaire videogames.
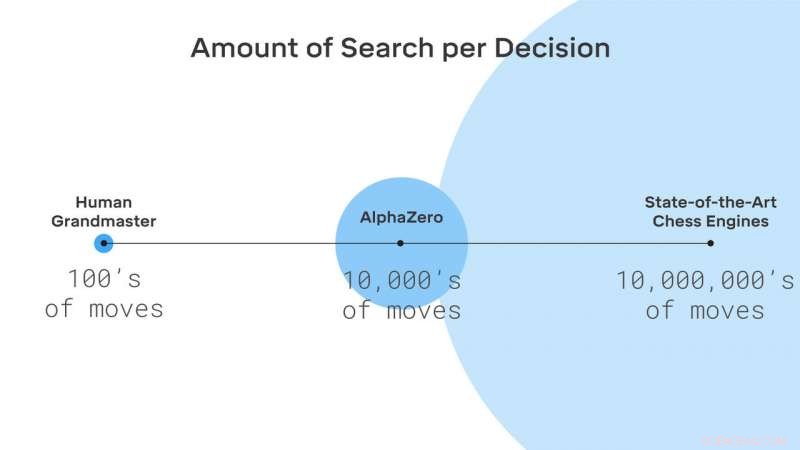
AlphaZero doorzoekt slechts een klein deel van de posities die door traditionele schaakengines worden overwogen. Krediet:DeepMind Technologies Ltd
© 2018 Wetenschap X Netwerk
 Een nieuwe generatie kunstmatige netvliezen op basis van 2D-materialen
Een nieuwe generatie kunstmatige netvliezen op basis van 2D-materialen- Science Projects on Dish Detergents
- Hoe de polariteit van verbindingen te vinden
- Afvalkoolstof van de staalproductie kan worden gerecycled tot nieuwe producten
- Wetenschappers ontwikkelen methode om de porositeit van transparante materialen te berekenen
- COVID-19:Aeolus en weersvoorspellingen
- Studie ontdekt waarom de opwarming van de aarde zal versnellen naarmate de CO2-niveaus stijgen
- De morele waarde van wildernis
- Britse temperatuurrecords tuimelden in 2019
- Onderzoekers onderzoeken de reactie van consumenten op het gebruik van gerecycled water bij de wijnproductie
Hoofdlijnen
- Een zwaartekrachttheorie ontwikkelen voor ecologie
- Kluizenaar of niet? Wetenschappers gebruiken Twitter om spidervragen aan te pakken
- Mitosis vs Meiosis: Wat zijn de overeenkomsten en verschillen?
- Hoe de wet van Sines
- Zeegras is wereldwijd een belangrijk visgebied
- Uitsterven dreigt voor twee zeldzame vogelsoorten na verwoestende orkanen
- Wat is het ultieme eindresultaat van glycolyse?
- Wat zijn Agar Slants?
- Voeding door mensen verandert het gedrag en de fysiologie van groene schildpadden op de Canarische Eilanden
- Rapporten:Coördinatie van regelgeving essentieel voor optimalisatie van grensoverschrijdende elektriciteitshandel in Zuid-Azië

- Nieuw tijdperk bij Alibaba als Jack Ma de zonsondergang tegemoet rijdt

- Wat is Hertz in elektriciteit?

- Kerncentrale Fukushima zonder ruimte voor radioactief water

- California AG laat de uitdaging voor de fusie tussen T-Mobile en Sprint vallen


 Degrowth-scenario's van 1,5 ° C suggereren de noodzaak van nieuwe mitigatieroutes
Degrowth-scenario's van 1,5 ° C suggereren de noodzaak van nieuwe mitigatieroutes- Politie minder proactief na negatieve publieke controle, studie zegt:
- Hoe de boog en lengte van een akkoord te vinden
- Volkswagen laat Audi-chef vallen die wordt beschuldigd van dieselfraude
- Nieuwe kleptechnologie belooft goedkoper, groenere motoren
- Kenmerken van een Catalase-enzym
- Wetenschappers vinden recept voor groenere verwijdering van tuinafval
- Een nieuwe benadering van schooltransitie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | German | Dutch | Danish | Norway | Spanish | Swedish |

-
Wetenschap © https://nl.scienceaq.com
