Wetenschap
Computervisie in het donker met terugkerende CNN's
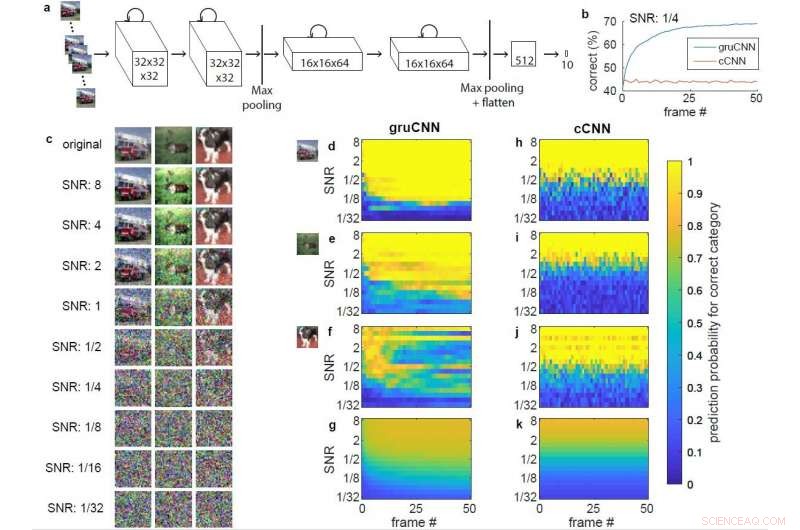
Architectuur en voorbeeldgegevens. a) Architectuur van gruCNN. Elke kanaalactiviteit is afhankelijk van zowel de huidige invoer als de vorige status. b) Classificatieprestaties van voorbeeld gruCNN en cCNN wanneer alle testsequenties een SNR van 1/4 hadden. c) Originele afbeelding en afbeelding met verschillende SNR's voor een brandweerwagen (categorie vrachtwagen) een rendier (categorie hert), en een hond, weergegeven zonder jitter. d–k) Kleurgecodeerde voorspelde kansen (output van softmax) van de juiste (positieve) afbeeldingscategorie voor gruCNN (d–g) en cCNN (h–k). Horizontale assen tonen voorspelde kansen over 51 frames, verticale assen over een reeks SNR's. d) &h) en e) &i) komen overeen met de prestaties in de voorbeelden van brandweerwagens en rendieren, respectievelijk. De voorspellende waarschijnlijkheid bij lage SNR's blijft verbeteren ten opzichte van frames voor de gruCNN-voorspellingen, maar zijn relatief constant voor de cCNN. f) &j) Gegevens voor het derde voorbeeld (de hond), waarin de gruCNN faalt (wat zeldzaam is), terwijl de cCNN de categorie correct voorspelt bij de meeste SNR's. De gemiddelde voorspelde kans op de juiste (positieve) afbeeldingscategorie voor alle 10, 000 testbeelden wordt weergegeven in g) &k). Credit:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
De afgelopen jaren is klassieke convolutionele neurale netwerken (cCNN's) hebben geleid tot opmerkelijke vooruitgang in computervisie. Veel van deze algoritmen kunnen nu objecten in afbeeldingen van goede kwaliteit met hoge nauwkeurigheid categoriseren.
Echter, in echte toepassingen, zoals autonoom rijden of robotica, beeldgegevens bevatten zelden foto's die zijn gemaakt onder ideale lichtomstandigheden. Vaak, de afbeeldingen die CNN's nodig zouden hebben om verstopte objecten te verwerken, bewegingsvervorming, of lage signaal-ruisverhoudingen (SNR's), hetzij als gevolg van slechte beeldkwaliteit of lage lichtniveaus.
Hoewel cCNN's ook met succes zijn gebruikt om beelden te de-ruisen en hun kwaliteit te verbeteren, deze netwerken kunnen geen informatie van meerdere frames of videosequenties combineren en worden daarom gemakkelijk overtroffen door mensen op afbeeldingen van lage kwaliteit. Tot S. Hartmann, een neurowetenschappelijk onderzoeker aan de Harvard Medical School, heeft onlangs een studie uitgevoerd die deze beperkingen aanpakt, introductie van een nieuwe CNN-aanpak voor het analyseren van afbeeldingen met ruis.
Hartmann, die een achtergrond heeft in de neurowetenschappen, heeft meer dan een decennium besteed aan het bestuderen van hoe mensen visuele informatie waarnemen en verwerken. In recente jaren, hij raakte steeds meer gefascineerd door de overeenkomsten tussen diepe CNN's die worden gebruikt in computervisie en het visuele systeem van de hersenen.
In de visuele cortex, hersengebied gespecialiseerd in het verwerken van visuele input, de meeste neurale verbindingen worden gemaakt in laterale en feedbackrichtingen. Dit suggereert dat visuele verwerking veel meer inhoudt dan de technieken die door cCNN's worden gebruikt. Dit motiveerde Hartmann om convolutionele lagen te testen die terugkerende verwerking bevatten, wat van vitaal belang is voor de verwerking van visuele informatie door het menselijk brein.
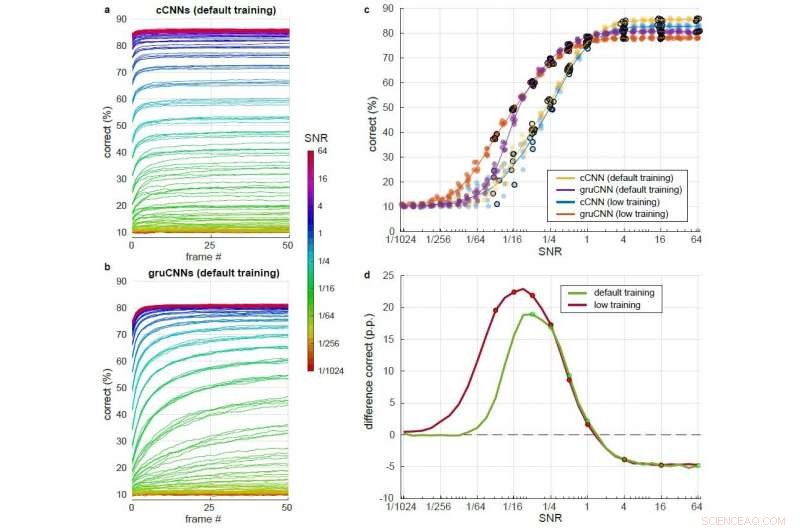
Gedetailleerde vergelijking van cCNN met Bayesiaanse gevolgtrekking en gruCNN-prestaties over een groot aantal SNR-niveaus. Elke modelarchitectuur werd getest na training met iets hogere SNR's (standaardtraining) en na training met iets lagere SNR's (lage training). a) &b) Percentage correct in de loop van 51 frames voor verschillende SNR's (kleurgecodeerd) met standaardtraining voor a) de cCNN (met Bayesiaanse inferentie) en b) de gruCNN. c) Punten:correcte classificatie voor de modelarchitecturen bij het laatste frame. Jitter in SNR-waarden is toegevoegd om de leesbaarheid van plots te vergroten, maar stond niet in de gegevens. Lijnen:gemiddelde prestaties van de vijf modellen per architectuur. d) Gemiddelde prestatie van gruCNN's minus gemiddelde prestatie van cCNN's voor modellen die zijn getraind met standaard en lagere SNR's (groen en rood, respectievelijk). SNR-niveaus die tijdens de training worden gebruikt, worden aangegeven met stippen. Credit:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Met behulp van terugkerende verbindingen binnen de convolutionele lagen van CNN, De aanpak van Hartmann zorgt ervoor dat netwerken beter zijn toegerust om pixelruis te verwerken, zoals die aanwezig zijn in foto's die zijn gemaakt onder slechte lichtomstandigheden. Wanneer getest op gesimuleerde videosequenties met ruis, terugkerende CNN's (gruCNN's) presteerden veel beter dan klassieke benaderingen, met succes objecten classificeren in gesimuleerde video's van lage kwaliteit, zoals die welke 's nachts zijn genomen.
Het toevoegen van terugkerende verbindingen aan een convolutionele laag voegt uiteindelijk ruimtelijk beperkt geheugen toe, waardoor het netwerk kan leren hoe informatie in de loop van de tijd kan worden geïntegreerd voordat het signaal te abstract wordt. Deze functie kan met name handig zijn bij een lage signaalkwaliteit, zoals in beelden met ruis of die zijn gemaakt bij slechte lichtomstandigheden.
In zijn studeerkamer Hartmann ontdekte dat cCNN's goed presteerden op afbeeldingen met hoge SNR's, gruCNN's, presteerden beter dan ze op lage SNR-beelden. Zelfs het toevoegen van Bayes-optimale temporele integraties, waarmee cCNN's meerdere afbeeldingsframes kunnen integreren, kwam niet overeen met de prestaties van gruCNN. Hartmann merkte ook op dat bij lage SNR's, gruCNNs-voorspellingen hadden hogere betrouwbaarheidsniveaus dan die geproduceerd door cCNNs.
Terwijl het menselijk brein is geëvolueerd om in de duisternis te zien, de meeste bestaande CNN zijn nog niet uitgerust om wazige of ruisrijke beelden te verwerken. Door netwerken te voorzien van de capaciteit om afbeeldingen in de loop van de tijd te integreren, de door Hartmann bedachte aanpak zou uiteindelijk het computerzicht kunnen verbeteren tot het punt dat het overeenkomt, of zelfs overtreft, menselijke prestaties. Dit kan enorm zijn voor toepassingen zoals zelfrijdende auto's en drones, maar ook in andere situaties waar een machine moet 'zien' onder niet-ideale lichtomstandigheden.
De studie van Hartmann zou de weg kunnen effenen voor de ontwikkeling van meer geavanceerde CNN's die beelden kunnen analyseren die zijn genomen onder slechte lichtomstandigheden. Het gebruik van terugkerende verbindingen in de vroege stadia van neurale netwerkverwerking zou de computervisiehulpmiddelen enorm kunnen verbeteren, het overwinnen van de beperkingen van klassieke CNN-benaderingen bij het verwerken van afbeeldingen met ruis of videostreams.
Als volgende stap, Hartmann zou de reikwijdte van zijn onderzoek kunnen uitbreiden door real-life toepassingen van gruCNN's te verkennen, testen ze in een breed scala van real-world scenario's. Mogelijk, zijn aanpak kan ook worden gebruikt om de kwaliteit van amateurvideo's of wankele homevideo's te verbeteren.
© 2018 Wetenschap X Netwerk
 Undruggable Parkinsons-molecuul verklapt zijn geheimen
Undruggable Parkinsons-molecuul verklapt zijn geheimen- Ultrasone techniek onthult de identiteit van grafiet
- Bacteriële enzymen:de biologische rol van europium
- Het mysterie van een Picasso onthuld door wetenschappers
- Chemici ontwikkelen nieuw materiaal voor het scheiden van kooldioxide uit industriële afvalgassen
- Zonlicht kan zeeplastic afbreken tot tienduizenden chemische verbindingen
- De vroegste rond-de-wereld mariene onderzoeksreizen geven nieuwe inzichten over klimaatverandering
- Ontdekking transformeert begrip van waterstofuitputting op de zeebodem
- Opwarming van de aarde nu al verantwoordelijk voor een op de drie hittegerelateerde sterfgevallen
- Knaagdieren van Arizona
Hoofdlijnen
- Welk proces voeren Ribosomes uit?
- Wetenschappers publiceren het genoom van de waterbuffel
- Aleppo-momenten:wat zorgt ervoor dat onze hersenen onder druk bevriezen?
- spijt,
- Drone-foto's bieden snellere, goedkopere gegevens over de belangrijkste Antarctische soorten
- Wat doet de Nucleolus in interfase?
- Wat is histonacetylatie?
- Wat is de basis voor uitzonderingen op het Aufbau-principe?
- Onderzoek toont lagere letselpercentages bij Nieuw-Zeelandse renpaarden
- Leger dringt aan op hogere snelheden in toekomstige tiltrotorvliegtuigen

- VAE-luchtvaartmaatschappijen hervatten beperkte passagiersvluchten

- Uber-aandelen blijven dalen in eerste volledige handelsdag

- Ik heb het gedaan:Portugese hacker zegt dat hij Afrikaanse tycoon heeft ontmaskerd

- Onderzoekers tonen aan dat vliegtuigbrandstoffen gemaakt van planten kostenconcurrerend kunnen zijn met conventionele fossiele brandstoffen


 NASA ziet nieuw gevormde tropische depressie 08W in de Zuid-Chinese Zee
NASA ziet nieuw gevormde tropische depressie 08W in de Zuid-Chinese Zee- Hoe kan je de struik het beste verbranden om het risico op bosbranden te verkleinen?
- Groot-Brittannië hoopt de sterren op één lijn te houden met de ruimteprojecten van de EU
- Nieuwe elektronenmicroscopie biedt nanoschaal, schadevrije isotopentracking in aminozuren
- Grafeentechnologie opent nieuwe horizonten voor de behandeling van ziekten
- Hoe orchideeën werken
- Boventoon
- NASA vindt tropische cycloon 02S consoliderend
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French |

-
Wetenschap © https://nl.scienceaq.com
