Wetenschap
Een nieuw algoritme om informatie-superspreaders op sociale media te voorspellen
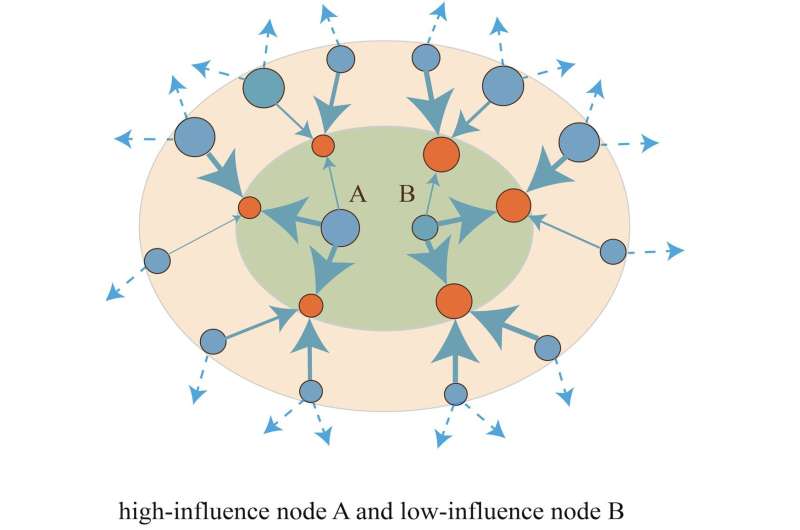
Begrijpen hoe informatie binnen sociale netwerken stroomt, is van cruciaal belang om gevaarlijke desinformatie tegen te gaan, de verspreiding van nieuws te bevorderen en gezonde online sociale omgevingen te ontwerpen. Wetenschappers zijn zich al lang bewust van de rol van informatie-superspreaders, namelijk gebruikers met de mogelijkheid om berichten en ideeën snel naar vele anderen te verspreiden.
Een lange onderzoekstraditie identificeert de superspreaders aan de hand van hun positie in het sociale netwerk. Recent onderzoek, gepubliceerd in het tijdschrift National Science Review en geleid door prof. Linyuan Lü (Universiteit voor Elektronische Wetenschap en Technologie van China) en Dr. Manuel S. Mariani (Universiteit van Zürich), daagt dit al lang bestaande paradigma uit. Het laat zien dat de gedragskenmerken van gebruikers (d.w.z. hoe ze zich neigen te gedragen) nauwkeurigere vroege indicatoren bieden van hun verspreidingsvermogen dan waar ze zich in het sociale netwerk bevinden.
De auteurs vertrokken van traditionele netwerkbenaderingen door te beginnen met een model voor hoe informatie van individu naar individu stroomt. Gemotiveerd door eerdere empirische bevindingen gaat het model ervan uit dat de waarschijnlijkheid dat een bericht van een bron naar een doelgebruiker wordt verzonden, wordt bepaald door zowel de invloed van de bron (namelijk een parameter die haar waarschijnlijkheid weergeeft om informatie naar anderen door te geven) als de gevoeligheid van het doelwit. beïnvloeden.
De invloeds- en gevoeligheidsparameters van de gebruikers zijn niet a priori bekend. De auteurs hebben echter een paar gekoppelde vergelijkingen afgeleid die de invloed en gevoeligheid van de gebruikers verbinden met de structuur van het onderliggende propagatienetwerk, waardoor berekeningen op enorme gedragsdatasets mogelijk zijn.
Door deze vergelijkingen konden de auteurs de invloed- en gevoeligheidsscores van miljoenen gebruikers in Weibo en Twitter meten, wat ons begrip van informatie-superspreaders op twee manieren verbetert. Ten eerste dagen de resultaten van de auteurs het paradigma uit dat de netwerkhubs (dat wil zeggen de gebruikers met veel volgers) de meest effectieve informatieverspreiders zijn.
Ze laten zien dat in plaats daarvan de invloed- en gevoeligheidsscores van de gebruikers nauwkeurigere voorspellers zijn voor het feit dat ze een superspreader zijn dan het aantal volgers van de gebruiker. Ten tweede worden superspreaders gekenmerkt door verbindingen met meer besmettingsgevaar (d.w.z. het product tussen hun invloed en de gevoeligheid van hun publiek is vaak groot), en ze hebben de neiging invloedrijkere gebruikers te beïnvloeden.
Dit suggereert dat het verklaren van de superspreaders de integratie vereist van netwerkstructuren en gedragskenmerken op individueel niveau.
Deze bevindingen zouden nieuwe richtingen kunnen openen in onderzoek naar sociale netwerken. Op het gebied van informatieverspreiding zouden de vereenvoudigende aannames van het propagatiemodel geleidelijk kunnen worden versoepeld. Meer verfijnde modellen kunnen onderwerpdiversiteit, algoritmische invloeden en geheugeneffecten omvatten, die allemaal kunnen leiden tot verschillende vergelijkingen voor de invloed- en gevoeligheidsscores van gebruikers.
De invloed- en gevoeligheidsscores kunnen ook per onderwerp verschillen, wat uiteindelijk zou kunnen leiden tot een multidimensionale karakterisering van de gebruikers en hun verspreidingsmogelijkheden.
Meer algemeen gezien zou het paradigma dat in dit onderzoek wordt voorgesteld ook implicaties kunnen hebben voor interventies gericht op grootschalige gedragsverandering. Traditioneel richten deze activiteiten zich op het overtuigen van de sociale hubs om vroegtijdig een nieuw product of nieuw gedrag te adopteren. De bevindingen van de auteurs suggereren dat een effectievere aanpak zou kunnen berusten op het identificeren van verbindingen met een hoog besmettingspercentage die zeer invloedrijke en zeer gevoelige potentiële adopters met elkaar verbinden.
Daartoe is aanvullend onderzoek nodig om het algoritme aan te passen aan de verspreiding van gedrag, waarvoor waarschijnlijk andere sets vergelijkingen nodig zijn dan die welke worden verkregen voor de verspreiding van informatie. Veldexperimenten zullen nodig zijn om de resulterende inzichten te valideren. Uiteindelijk zouden deze inspanningen kunnen onthullen hoe de posities van individuen in hun sociale netwerken het beste kunnen worden geïntegreerd met hoe zij zich doorgaans gedragen, om interventies voor gedragsverandering te ontwerpen, wat van cruciaal belang is voor organisaties en beleidsmakers.