Wetenschap
Hoe computationele taalkunde helpt om te begrijpen hoe taal werkt
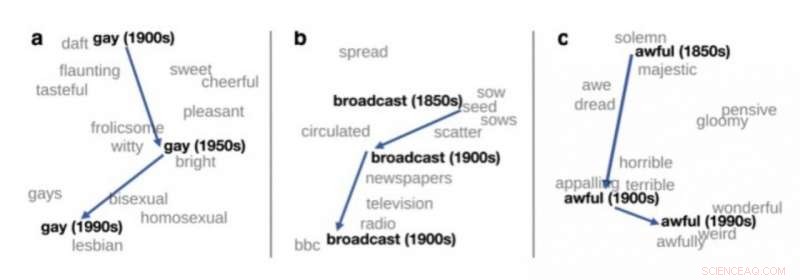
Tweedimensionale weergave van de betekenisverandering van drie Engelse woorden, overgenomen van Hamilton et al. (2016). Krediet:upf
Distributionele semantiek verkrijgt representaties van de betekenis van woorden door duizenden teksten te verwerken en generalisaties te extraheren met behulp van computationele algoritmen. Ondanks de populariteit van distributiesemantiek op gebieden als computerlinguïstiek en cognitieve wetenschap, de impact ervan op de theoretische taalkunde is tot dusver zeer beperkt geweest.
Onderzoek door Gemma Boleda, hoofd van de onderzoeksgroep Computational Linguistics and Language Theory (COLT) en ICREA-onderzoeksprofessor bij de afdeling Vertaal- en Taalwetenschappen van UPF, gepubliceerd in het tijdschrift Jaaroverzicht van de taalkunde , geeft een kritisch overzicht van de overvloedige studies die beschikbaar zijn over distributiesemantiek, met speciale nadruk op de resultaten die relevant zijn voor de theoretische taalkunde. Concreet zijn er drie gebieden:semantische verandering, polysemie en compositie, en de grammatica-semantiek-interface.
Het onderzoek van Gemma Boleda probeert theoretische en computationele benaderingen met elkaar te verbinden om de collectieve kennis over hoe taal werkt te bevorderen. Een van de methoden die ze uitgebreid heeft onderzocht, is de verdelingssemantiek, waarmee automatisch representaties van woorden kunnen worden verkregen. Van deze representaties is aangetoond dat ze significante taalkundige eigenschappen weerspiegelen, zoals hoe twee woorden op elkaar lijken:een persoon zal je vertellen dat "hond" en "puppy" erg op elkaar lijken, en toch lijken "hond" en "democratie" nauwelijks op elkaar; distributiesemantiek zal hetzelfde zeggen, dankzij het feit dat het taalkundige eigenschappen induceert op basis van teksten die door mensen zijn geschreven. Daarom, distributiesemantiek biedt radicaal empirische representaties.
Distributionele semantiek maakt het mogelijk het gebruik van woorden en de evolutie van hun betekenis te analyseren
Distributionele semantiek biedt een aantrekkelijk, complementair kader aan andere, meer traditionele methoden, niet alleen omdat het radicaal empirisch is, maar ook omdat het multidimensionale representaties biedt:twee woorden kunnen worden vergeleken met één betekenisdimensie ("pizza" en "pasta" zijn soorten voedsel), of op een andere ("pizza" en "wiel" zijn rond). Om alle aspecten van betekenis weer te geven, multidimensionale representaties nodig zijn. Distributionele semantiek kan het algemene gebruik van twee woorden vastleggen, evenals hun onderscheidende factoren.
Een van de belangrijke toepassingen van distributiesemantiek in de theoretische taalkunde is het detecteren van betekenisveranderingen. Als taalgegevens uit verschillende perioden worden verwerkt, zoals boeken in het Engels vanaf 1900, 1950 en 1990, distributiesemantiek kan worden gebruikt om automatisch de betekenisverandering van sommige woorden te detecteren. Bijvoorbeeld, het woord 'homo' in het Engels betekende aan het begin van de vorige eeuw 'gelukkig' en wordt in toenemende mate gebruikt in de betekenis van 'homoseksueel'.
Aspecten van onderzoek naar distributiesemantiek die bijdragen aan taaltheorie
Uit de analyse van de bestudeerde werken, Boleda concludeert dat er voldoende bewijs is om de solide resultaten van de distributiesemantiek rechtstreeks te importeren in onderzoek in de theoretische taalkunde.
"Er zijn ten minste vier aspecten van onderzoek naar distributiesemantiek die kunnen bijdragen aan taaltheorie. Het eerste aspect is verkennend:distributierepresentaties kunnen worden gebruikt om grootschalige gegevens te verkennen, bijvoorbeeld door de gelijkenis van woorden te onderzoeken. De tweede is als een hulpmiddel om specifieke gevallen van taalkundige verschijnselen te identificeren. Bijvoorbeeld, woorden kunnen worden geïdentificeerd waarvan de betekenis is veranderd bij het vergelijken van de representaties die zijn verkregen uit teksten uit verschillende perioden. De derde is als een testbank:het evalueren van verschillende taalhypothesen in distributietermen. De vierde en moeilijkste is de ontdekking van nieuwe taalfenomenen of relevante theoretische trends in de gegevens, " legt de auteur uit in haar werk.
 Het veel voorkomende gebruik van wijnsteenzuur
Het veel voorkomende gebruik van wijnsteenzuur- Magnetische T-Budbots gemaakt van theeplanten doden en reinigen biofilms
- Wetenschappers bevestigen verschillende regio's in het populaire oplosmiddel voor het opvangen en synthetiseren van koolstof
- Een minerale spons gebruiken om uranium op te vangen
- Hoe potentieel schadelijke vrije radicalen in sigarettenrook te meten?
- Mos dat arseen uit drinkwater kan verwijderen ontdekt
- Virginia ziet plotselinge toename van het aantal eikenbomen, boswachters zeggen:
- Video toont invasieve koraalduivels die smullen van nieuwe Caribische vissoorten
- Dammen in de bovenste Mekong-rivier wijzigen de biologische beschikbaarheid van voedingsstoffen stroomafwaarts
- Big data en machine learning inzetten om bosbranden in het westen van de VS te voorspellen
Hoofdlijnen
- Hoe een Western Blot te lezen
- Massive Angel Oak is getuige geweest van 500 jaar geschiedenis van South Carolina
- Hoe evolueert de mens?
- Hommels bestuderen om meer te leren over menselijke intelligentie en geheugen
- 5 stadia van mitose
- Is de tweekamerige geest geëvolueerd om het moderne menselijke bewustzijn te creëren?
- Hoe soorten versteend hout te identificeren
- De reden voor incubatie bij verschillende temperaturen in de microbiologie
- Vloeken maakt je sterker,
- Plunderaars plunderen gezonken schatten van Albanië

- De COVID-19-pandemie heeft aangetoond dat wereldwijde toeleveringsketens een enorm kaartenhuis zijn

- Onderzoekers pleiten voor kortere werkweek om productiviteit te verhogen lagere burn-out

- Wat is creatiever, de kunsten of de wetenschappen?
- Coronavirus in de Zweedse media:is het vertrouwen over zijn hoogtepunt heen?

 Nieuw onderzoek verklaart toekomstige effecten van de uitstoot van broeikasgassen
Nieuw onderzoek verklaart toekomstige effecten van de uitstoot van broeikasgassen- Zijn onderdoorgangen veilig tijdens een tornado?
- China bouwt een drijvende ruimtehaven voor raketlanceringen
- Koffie-ringeffect aangewend voor snelle, goedkope analyse van kraanwater
- Nieuwe mitigatiestructuur helpt bij het beschermen van de permafrost van het Tibet-plateau
- Honderden wetenschappers beginnen aan een missie om de voorspellingen van de luchtkwaliteit te verbeteren
- Wanneer eiwitten elkaar het hof maken, de dansmoves zijn belangrijk
- Definitie van Toxic Endpoint
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
