Wetenschap
Een kern van waarheid benaderen
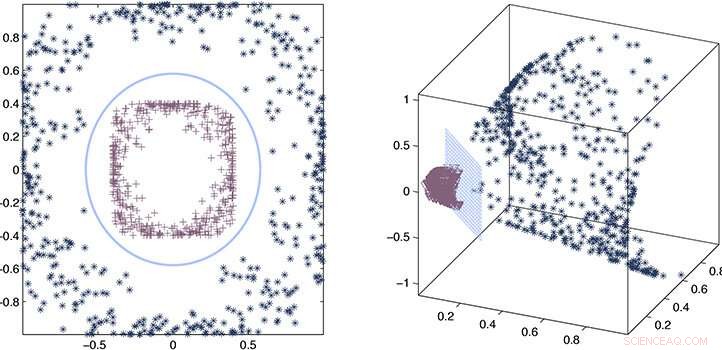
De onderzoekers gebruikten een proces van foutschatting en wiskundige benadering om te bewijzen dat hun geschatte kern consistent blijft met de nauwkeurige kern. Krediet:2020 Ding et al.
Door een benaderende in plaats van expliciete "kernel" -functie te gebruiken om relaties in zeer grote datasets te extraheren, KAUST-onderzoekers hebben de snelheid van machine learning drastisch kunnen verhogen. De aanpak belooft de snelheid van kunstmatige intelligentie (AI) in het tijdperk van big data sterk te verbeteren.
Wanneer AI wordt blootgesteld aan een grote onbekende dataset, het moet de gegevens analyseren en een model of functie ontwikkelen die de relaties in de set beschrijft. De berekening van deze functie, of kern, is een rekenintensieve taak die kubisch (tot de macht drie) in complexiteit toeneemt met de grootte van de dataset. In het tijdperk van big data en de toenemende afhankelijkheid van AI voor analyse, dit levert een echt probleem op waar kernelselectie onpraktisch tijdrovend kan worden.
Onder toezicht van Xin Gao, Lizhong Ding en zijn collega's hebben gewerkt aan methoden om de kernelselectie te versnellen met behulp van statistieken.
"De computationele complexiteit van nauwkeurige kernelselectie is meestal kubiek met het aantal monsters, ", zegt Ding. "Dit soort kubieke schaling is onbetaalbaar voor big data. In plaats daarvan hebben we een benaderingsaanpak voor kernelselectie voorgesteld, wat de efficiëntie van kernelselectie aanzienlijk verbetert zonder de voorspellende prestaties op te offeren."
De ware of nauwkeurige kernel geeft een woordelijke beschrijving van relaties in de dataset. Wat de onderzoekers ontdekten, is dat statistieken kunnen worden gebruikt om een geschatte kernel af te leiden die bijna net zo goed is als de nauwkeurige versie, maar kan vele malen sneller worden berekend, lineair schalen, in plaats van kubisch, met de grootte van de dataset.
Om de aanpak te ontwikkelen, het team moest speciaal ontworpen kernelmatrices construeren, of wiskundige arrays, dat kon snel worden berekend. Ze moesten ook de regels en theoretische grenzen vaststellen voor de selectie van de geschatte kernel die nog steeds de leerprestaties zou garanderen.
"De grootste uitdaging was dat we nieuwe algoritmen moesten ontwerpen die tegelijkertijd aan deze twee punten voldoen, ' zegt Ding.
Door een proces van foutschatting en wiskundige benadering te combineren, de onderzoekers konden bewijzen dat hun geschatte kernel consistent blijft met de nauwkeurige kernel en demonstreerden vervolgens de prestaties in echte voorbeelden.
"We hebben aangetoond dat benaderingsmethoden, zoals ons computerraamwerk, voldoende nauwkeurigheid bieden voor het oplossen van een op kernel gebaseerde leermethode, zonder de onpraktische rekenlast van nauwkeurige methoden, ", zegt Ding. "Dit biedt een effectieve en efficiënte oplossing voor problemen in datamining en bioinformatica die schaalbaarheid vereisen."

Hoofdlijnen
- Fun Biology Presentatie Onderwerpen
- Kuifduiven gebruiken veren om alarm te slaan
- Marihuanaboerderijen stellen gevlekte uilen bloot aan rattengif in Noordwest-Californië
- Getoonde chimpansees die spontaan om de beurt een cijferpuzzel oplossen
- Verschil tussen homozygoot en heterozygoot
- Kunnen eukaryoten overleven zonder mitochondria?
- Hoe doodt alcohol bacteriën?
- De effecten van temperatuur op enzymactiviteit en biologie
- Definitie van menselijke biologie
- Californië wil tegen 2045 koolstofvrij zijn. Is dat haalbaar?
- Samsung beëindigt productie van smartphonetelefoons in China

- Virtuele realiteit:toekomstige fabrieken gerund door digitale tweelingen

- Ierse Ryanair-piloten kondigen 48-uursstaking aan

- Een nieuwe benadering voor parafraseren zonder toezicht zonder vertaling

 Sterke aardbeving treft de afgelegen Aleoeten in Alaska
Sterke aardbeving treft de afgelegen Aleoeten in Alaska- Het progressieve beleid van Californië schaadt de banen niet, economie, studie vondsten
- Zeer weinig publieke steun voor versoepeling van regels en voorschriften rond fracking
- Gaat het grootste deel van uw salaris naar de huur? Dat kan schadelijk zijn voor uw gezondheid
- Afbeelding:Gigantische magnetische touwen in een halo van sterrenstelsels
- Voors en tegens van synthetische polymeren
- Sri Lanka gaat kettingzagen verbieden houtfabrieken:president
- De waterstofeconomie een zuurtest geven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
