Wetenschap
Nvidia werkt snel proces uit om 3D-modellen te maken van 2D-afbeeldingen
Krediet:Nvidia
Het doel:2D-beelden omzetten in 3D-modellen met behulp van een speciale encoder-decoderarchitectuur. De acteurs:Nvidia. De lof:een slim gebruik van machine learning met nuttige toepassingen uit de echte wereld.
Paul Lilly in Hete hardware was een van de tech-watchers die opmerkte dat de manier waarop ze van 2D naar 3D gingen nieuws was. Het is geen grote verrassing wanneer het pad omgekeerd is - 3D in 2D - maar "om een 3D-model te maken zonder een systeem met 3D-gegevens in te voeren, is een veel grotere uitdaging."
Lilly citeerde Jun Gao, een van de onderzoeksteams die aan de rendering-aanpak hebben gewerkt. "Dit is in wezen de eerste keer dat je zo ongeveer elke 2D-afbeelding kunt maken en relevante 3D-eigenschappen kunt voorspellen."
Hun magische saus bij het produceren van een 3D-object uit 2D-beelden is een "differentieerbare op interpolatie gebaseerde renderer, " of DIB-R. De onderzoekers van Nvidia trainden hun model op datasets met afbeeldingen van vogels. Na de training, DIB-R had de mogelijkheid om een vogelafbeelding te maken en een 3D-afbeelding te leveren, met de juiste vorm en textuur van een 3D-vogel.
Nvidia beschreef verder input getransformeerd in een feature map of vector die wordt gebruikt om specifieke informatie zoals vorm, kleur, textuur en verlichting van een afbeelding.
Waarom dit belangrijk is: Gizmodo 's kop vatte het samen. "Nvidia leerde een AI om direct volledig getextureerde 3D-modellen te genereren van platte 2D-afbeeldingen." Dat woord "onmiddellijk" is belangrijk.
DIB-R kan in minder dan 100 milliseconden een 3D-object van een 2D-beeld maken, zei Lauren Finkle van Nvidia. "Het doet dit door een polygoonbol te veranderen - het traditionele sjabloon dat een 3D-vorm vertegenwoordigt. DIB-R verandert het zodat het overeenkomt met de echte objectvorm die wordt weergegeven in de 2D-afbeeldingen."
Andrew Liszewski in Gizmodo markeerde dit tijdselement van 100 milliseconden. "Die indrukwekkende verwerkingssnelheid maakt deze tool bijzonder interessant omdat het de potentie heeft om de manier waarop machines zoals robots, of zelfrijdende auto's, zie de wereld, en begrijpen wat voor hen ligt."
Wat betreft zelfrijdende auto's, Liszewski zei, "Stilstaande beelden uit een live videostream van een camera kunnen onmiddellijk worden omgezet in 3D-modellen die een autonome auto mogelijk maken, bijvoorbeeld, om nauwkeurig de grootte van een grote vrachtwagen te meten die hij moet vermijden."

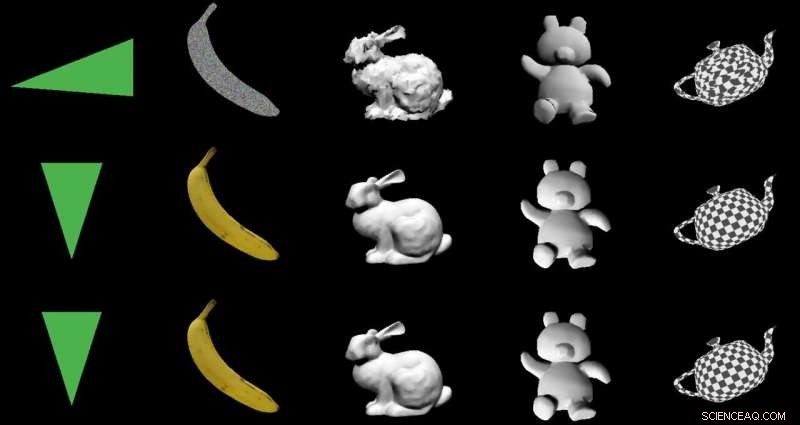
Het team testte DIB-R op vier 2D-afbeeldingen van vogels (uiterst links). Het eerste experiment gebruikte een afbeelding van een gele grasmus (linksboven) en produceerde een 3D-object (bovenste twee rijen). Krediet:Nvidia
Een model dat een 3D-object zou kunnen afleiden uit een 2D-beeld zou in staat zijn om objecten beter te volgen, en Lilly ging nadenken over het gebruik ervan in robotica. "Door 2D-beelden te verwerken tot 3D-modellen, een autonome robot zou beter in staat zijn om veiliger en efficiënter met zijn omgeving om te gaan, " hij zei.
Nvidia merkte op dat autonome robots, om dat te kunnen doen, "moet de omgeving kunnen voelen en begrijpen. DIB-R zou die mogelijkheden voor dieptewaarneming mogelijk kunnen verbeteren."
Gizmodo 's Liszewski, In de tussentijd, vermeld wat de Nvidia-aanpak zou kunnen doen voor de veiligheid. "DIB-R zou zelfs de prestaties kunnen verbeteren van beveiligingscamera's die zijn belast met het identificeren en volgen van mensen, omdat een direct gegenereerd 3D-model het gemakkelijker zou maken om beeldovereenkomsten uit te voeren terwijl een persoon door zijn gezichtsveld beweegt."
Nvidia-onderzoekers zouden deze maand hun model presenteren op de jaarlijkse Conference on Neural Information Processing Systems (NeurIPS), in Vancouver.
Degenen die meer willen weten over hun onderzoek, kunnen hun paper bekijken op arXiv, "Leren om 3D-objecten te voorspellen met een op interpolatie gebaseerde differentieerbare renderer." De auteurs zijn Wenzheng Chen, juni Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson en Sanja Fidler.
Ze stelden "een volledig op rasters gebaseerde differentieerbare renderer voor waarvoor gradiënten analytisch kunnen worden berekend." Wanneer gewikkeld rond een neuraal netwerk, hun raamwerk leerde vorm te voorspellen, textuur, en licht van afzonderlijke beelden, ze zeiden, en ze toonden hun raamwerk "om een generator van 3D-gestructureerde vormen te leren."
In hun samenvatting merkten de auteurs op dat "veel modellen voor machine learning op afbeeldingen werken, maar negeer het feit dat afbeeldingen 2D-projecties zijn die worden gevormd door 3D-geometrie die in wisselwerking staat met licht, in een proces dat renderen wordt genoemd. Het inschakelen van ML-modellen om beeldvorming te begrijpen, kan de sleutel zijn voor generalisatie."
Ze presenteerden DIB-R als een raamwerk waarmee gradiënten analytisch kunnen worden berekend voor alle pixels in een afbeelding.
Ze zeiden dat de sleutel tot hun aanpak was om "voorgrondrasterisatie te zien als een gewogen interpolatie van lokale eigenschappen en achtergrondrasterisatie als een op afstand gebaseerde aggregatie van globale geometrie. Onze aanpak zorgt voor nauwkeurige optimalisatie over vertexposities, kleuren, normalen, lichtrichtingen en textuurcoördinaten door een verscheidenheid aan verlichtingsmodellen."
© 2019 Wetenschap X Netwerk
 NASA-NOAA-satelliet vindt windschering die op het centrum van Tropical Storm Isaacs duwt
NASA-NOAA-satelliet vindt windschering die op het centrum van Tropical Storm Isaacs duwt- De magnetische noordpool van de aarde is de afgelopen 40 jaar snel verschoven
- Wat is het verschil tussen hagedissen en gekko's?
- Zee van plastic:Med-vervuiling in de schijnwerpers tijdens Conservation Meet
- Onderzoek naar verbanden tussen drie aardbevingen in Nieuw-Zeeland
Hoofdlijnen
- Hoeveel tijd kost het om een DNA-molecuul te repliceren?
- Onderzoekers leggen uit hoe slangen in een rechte lijn kunnen kruipen
- Difference Between Triglycerides & Phospholipids
- Is het ethisch om stamcellen te gebruiken?
- Wat zijn de functies van longblaasjes in de longen?
- Colombia - een megadivers paradijs dat nog ontdekt moet worden
- Hoe vogelgriep werkt
- Hoe de verschillende soorten alveolaire cellen te identificeren
- De relatie tussen leeftijd en plasticiteit
- Wind natuurlijk effectiever dan koude lucht in koelruimtes

- Website beoordeelt beveiliging van apparaten met internetverbinding

- Sociale media, interactieve AI-tool kan helpen bij het redden van levens tijdens rampen, Spoedgevallen

- UPS volgt de verzending van rundvlees van boerderij naar tafel met nieuwe technologie

- Zuckerberg voert gesprekken in Washington over toekomstige regelgeving


 Snelle screening op potentiële nieuwe katalysatoren
Snelle screening op potentiële nieuwe katalysatoren- Nano-hashtags kunnen de sleutel zijn tot het genereren van het zeer gewilde Majorana-quasideeltje
- Nieuwe opstelling voor elektrische metingen met hoge doorvoer van kwantummaterialen en apparaten
- Mars-orbiter zoekt toekomstige landingsplaatsen
- Everglades heeft meer zoet water nodig om het binnendringen van zout water te bestrijden
- Solo Russische klimmer sterft op vierde hoogste berg
- Natuurlijke pesticide op basis van silica beschermt gewassen in opslag en kan giftige fosfine elimineren
- Gigantische antennes in New Mexico zoeken naar kosmische ontdekkingen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
