Wetenschap
Gedestilleerde 3D (D3D)-netwerken voor video-actieherkenning
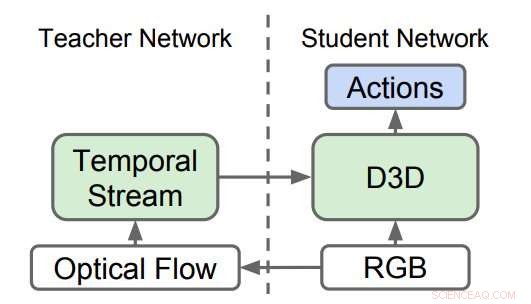
Gedistilleerde 3D-netwerken (D3D). De onderzoekers trainden een 3D CNN om acties van RGB-video te herkennen, terwijl ze kennis destilleren uit een netwerk dat acties herkent uit optische stroomsequenties. Tijdens gevolgtrekking, alleen D3D wordt gebruikt. Krediet:Stroud et al.
Een team van onderzoekers bij Google, de University of Michigan en Princeton University hebben onlangs een nieuwe methode ontwikkeld voor video-actieherkenning. Video-actieherkenning omvat het identificeren van bepaalde acties die worden uitgevoerd in videobeelden, zoals het openen van een deur, een deur sluiten, enzovoort.
Onderzoekers proberen computers al jaren te leren menselijke en niet-menselijke acties op video te herkennen. De meeste geavanceerde tools voor het herkennen van video-acties maken gebruik van een ensemble van twee neurale netwerken:de ruimtelijke stroom en de tijdelijke stroom.
Bij deze benaderingen één neuraal netwerk is getraind om acties in een stroom van reguliere beelden te herkennen op basis van uiterlijk (d.w.z. de 'spatial stream') en het tweede netwerk is getraind om acties in een stroom van bewegingsgegevens te herkennen (d.w.z. de 'temporal stream'). De resultaten die door deze twee netwerken worden bereikt, worden vervolgens gecombineerd om video-actieherkenning te bereiken.
Hoewel de empirische resultaten die zijn bereikt met behulp van 'two-stream'-benaderingen geweldig zijn, deze methoden zijn afhankelijk van twee verschillende netwerken, in plaats van een enkele. Het doel van het onderzoek van de onderzoekers van Google, de Universiteit van Michigan en Princeton moesten manieren onderzoeken om dit te verbeteren, om de twee stromen van de meeste bestaande benaderingen te vervangen door één enkel netwerk dat rechtstreeks leert van de gegevens.
In de meest recente onderzoeken zowel ruimtelijke als temporele stromen bestaan uit 3D convolutionele neurale netwerken (CNN's), die tijdsruimtelijke filters toepassen op de videoclip voordat classificatie wordt geprobeerd. theoretisch, deze toegepaste tijdelijke filters zouden de ruimtelijke stroom in staat moeten stellen bewegingsrepresentaties te leren, daarom zou de tijdelijke stroom niet nodig moeten zijn.
In praktijk, echter, de prestaties van tools voor het herkennen van video-acties verbeteren wanneer een volledig afzonderlijke tijdelijke stream wordt opgenomen. Dit suggereert dat de ruimtelijke stroom alleen niet in staat is om enkele van de signalen te detecteren die door de tijdelijke stroom worden opgevangen.
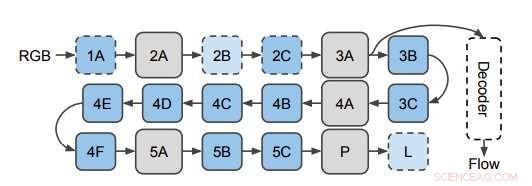
Het netwerk dat wordt gebruikt om de optische stroom van 3D CNN-functies te voorspellen. De onderzoekers passen de decoder toe op verborgen lagen in de 3D CNN (hier afgebeeld op laag 3A). Dit diagram toont de structuur van I3D/S3D-G, waarbij blauwe vakken convolutie (stippellijnen) of Inception-blokken (ononderbroken lijnen) vertegenwoordigen, en grijze vakken vertegenwoordigen pooling-blokken. Laagnamen zijn dezelfde als die in Inception worden gebruikt. Krediet:Stroud et al.
Om deze observatie verder te onderzoeken, de onderzoekers onderzochten of de ruimtelijke stroom van 3D CNN's voor video-actieherkenning inderdaad bewegingsrepresentaties mist. Vervolgens, ze toonden aan dat deze bewegingsrepresentaties kunnen worden verbeterd met behulp van distillatie, een techniek om kennis in een ensemble te comprimeren tot één model.
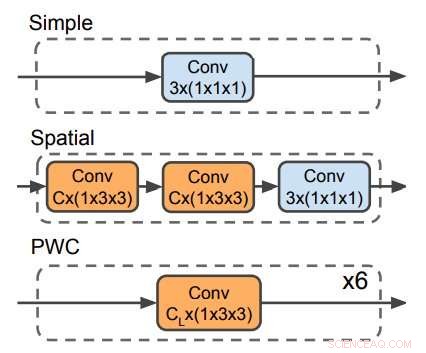
Drie decoders die worden gebruikt om de optische stroom te voorspellen. De PWC-decoder lijkt op het optische stroomvoorspellingsnetwerk van PWC-net. Geen enkele decoder maakt gebruik van tijdelijke filters. Krediet:Stroud et al.
De onderzoekers trainden een 'lerarennetwerk' om acties te herkennen op basis van de bewegingsinput. Vervolgens, ze trainden een tweede 'studenten' netwerk, die alleen wordt gevoed door de stroom van reguliere afbeeldingen, met een tweeledig doel:goed presteren in de actieherkenningstaak en de output van het lerarennetwerk nabootsen. Eigenlijk, het studentennetwerk leert herkennen op basis van zowel uiterlijk als beweging, beter is dan de leraar en net zo goed als de grotere en omslachtigere tweestroommodellen.
Onlangs, een aantal onderzoeken testte ook een alternatieve benadering voor video-actieherkenning, wat inhoudt dat je een enkel netwerk traint met twee verschillende doelen:goed presteren bij de actieherkenningstaak en het direct voorspellen van de bewegingssignalen op laag niveau (d.w.z. optische stroom) in de video. De onderzoekers ontdekten dat hun distillatiemethode beter presteerde dan deze aanpak. Dit suggereert dat het voor een netwerk minder belangrijk is om de optische stroom op laag niveau in een video effectief te herkennen dan om de kennis op hoog niveau te reproduceren die het lerarennetwerk heeft geleerd over het herkennen van acties uit beweging.
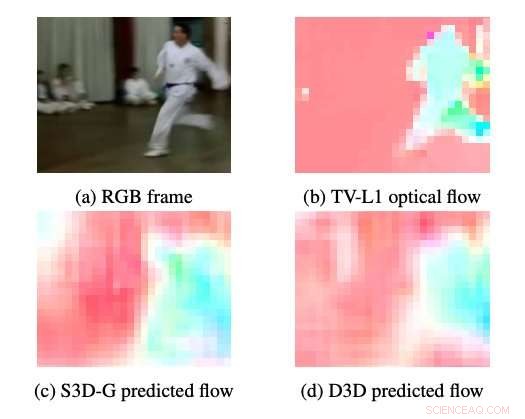
Voorbeelden van optische stroming geproduceerd door S3DG en D3D (zonder fijnafstemming) met behulp van de PWC-decoder aangebracht op laag 3A. De kleur en verzadiging van elke pixel komt overeen met de hoek en de grootte van de beweging, respectievelijk. TV-L1 optische stroom wordt weergegeven op 28 × 28px, de uitgangsresolutie van de decoder. Krediet:Stroud et al.
De onderzoekers bewezen dat het mogelijk is om een neuraal netwerk met één stroom te trainen dat even goed presteert als tweestroomsbenaderingen. Hun bevindingen suggereren dat de prestaties van de huidige state-of-the-art methoden voor video-actieherkenning kunnen worden bereikt met ongeveer 1/3 van de rekenkracht. Dit zou het gemakkelijker maken om deze modellen uit te voeren op apparaten met beperkte rekenkracht, zoals smartphones, en op grotere schaal (bijvoorbeeld om acties te identificeren, zoals 'slam dunks', in YouTube-video's).
Algemeen, deze recente studie belicht enkele van de tekortkomingen van bestaande methoden voor het herkennen van video-acties, een nieuwe aanpak voorstellen waarbij een leraar en een studentennetwerk worden opgeleid. Toekomstig onderzoek, echter, zou kunnen proberen state-of-the-art prestaties te bereiken zonder de noodzaak van een lerarennetwerk, door de trainingsgegevens rechtstreeks naar het studentennetwerk te sturen.
© 2019 Wetenschap X Netwerk
 Onderzoekers ontwikkelen flexibele materialen die op een omkeerbare manier overschakelen van nanoporeuze 3D- naar 2D-structuren
Onderzoekers ontwikkelen flexibele materialen die op een omkeerbare manier overschakelen van nanoporeuze 3D- naar 2D-structuren- De eeuwigheid modelleren in het rotslaboratorium
- Kunstmatige bladeren uit het lab de lucht in verplaatsen
- Een biosensor voor het meten van extracellulaire waterstofperoxideconcentraties
- Licht voor lithografie kan gedrukte vezels passeren
- Waarom verantwoorde inkoop van DRC-mineralen grote zwakke plekken heeft?
- Zonne-energiecentrales krijgen hulp van satellieten om bewolking te voorspellen
- Hurricane Experiments for Kids
- Lokaal en plantaardig eten:hoe steden duurzaam te voeden?
- Leven en dood van Irma:einde van 2 weken van woede en verwoesting
Hoofdlijnen
- Hightech camera helpt zeugen en biggen te beschermen
- Europarlementariërs dringen aan op onderzoek naar Monsantos heerschappij over veiligheidsstudies
- Denken dieren rationeel? Onderzoeker suggereert dat rationele besluitvorming geen taal vereist
- Er zit een diepere vis in de zee
- Nieuwe screeningstechniek stelt veredelaars in staat sneller droogteresistente rassen te ontwikkelen
- Wat is een voorbeeld van een recessief fenotype?
- Nieuwe high-throughput sequencing-technologieën onthullen een wereld van op elkaar inwerkende micro-organismen
- Ezels hebben meer bescherming nodig tegen de winter dan paarden
- Wat is de relatie tussen genetische manipulatie en DNA-technologie?
- De elektrische voertuigrevolutie zal uit China komen, niet de VS

- Waarom het bedrijfsmodel van socialemediagiganten als Facebook onverenigbaar is met mensenrechten

- BP kijkt naar ORNL, ADIOS om gegevens in toom te houden

- Luchtkwaliteit-app beïnvloedt gedrag door gezondheid te koppelen aan omgeving

- Model helpt bij het kiezen van windparklocaties, voorspelt output


 Waarom zijn mensen religieus? Een cognitief perspectief
Waarom zijn mensen religieus? Een cognitief perspectief- Mobiele telefoons helpen rampenbestrijding te transformeren
- Hoe een MPA naar KN te converteren
- SpaceXs eerste gerecyclede draak arriveert bij ruimtestation
- Wat is het verschil tussen een bijtschildpad en een geschilderde schildpad?
- Tweede crash hernieuwt bezorgdheid over de veiligheid voor Boeings gewaardeerde nieuwe jet
- Een bankanalysetool gebruiken om voorspellingen te doen over een nationale of wereldwijde financiële crisis
- Een win-winoplossing:versnipperd stro kan de bodemvruchtbaarheid verbeteren en ammoniakvervuiling verminderen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
