Wetenschap
Hoe we een tool hebben gebouwd die de kracht van islamofobe haatspraak op Twitter detecteert

vinden, en het meten van islamofobie-haatspraak op sociale media. Krediet:John Gomez/Shutterstock
In een mijlpaalbeweging, een groep parlementsleden publiceerde onlangs een werkdefinitie van de term islamofobie. Ze definieerden het als "geworteld in racisme", en als "een soort racisme dat zich richt op uitingen van moslim-zijn of vermeende moslim-zijn".
In ons laatste werkdocument we wilden de prevalentie en ernst van dergelijke islamofobe haatuitingen op sociale media beter begrijpen. Dergelijke spraak schaadt gerichte slachtoffers, creëert een gevoel van angst onder moslimgemeenschappen, en in strijd is met de fundamentele beginselen van eerlijkheid. Maar we stonden voor een belangrijke uitdaging:hoewel extreem schadelijk, Islamofobe haatzaaiende uitlatingen zijn eigenlijk vrij zeldzaam.
Elke dag worden er miljarden berichten op sociale media verzonden, en slechts een heel klein aantal van hen bevat enige vorm van haat. Daarom zijn we begonnen met het maken van een classificatietool met behulp van machine learning die automatisch detecteert of tweets islamofobie bevatten.
Opsporen van islamofobe haatzaaiende uitlatingen
Er zijn enorme vooruitgang geboekt bij het gebruik van machine learning om meer algemene haatspraak robuust te classificeren, op grote schaal en tijdig. Vooral, er is veel vooruitgang geboekt bij het categoriseren van inhoud op basis van of het hatelijk is of niet.
Maar islamofobe haatzaaiende uitlatingen zijn veel genuanceerder en complexer dan dit. Het loopt uiteen van verbaal aanvallen, het misbruiken en beledigen van moslims om hen te negeren; van het benadrukken hoe ze als "anders" worden beschouwd tot het suggereren dat ze geen legitieme leden van de samenleving zijn; van agressie tot ontslag. We wilden met onze tool rekening houden met deze nuance, zodat we konden categoriseren of inhoud al dan niet islamofoob is en of de islamofobie sterk of zwak is.
We definieerden islamofobe haatzaaiende uitlatingen als "elke inhoud die wordt geproduceerd of gedeeld en die willekeurige negativiteit tegen de islam of moslims uitdrukt". Dit verschilt van, maar is goed afgestemd op de werkdefinitie van islamofobie door parlementsleden, hierboven beschreven. Volgens onze definities, sterke islamofobie omvat uitspraken als "alle moslims zijn barbaren", terwijl zwakke islamofobie subtielere uitdrukkingen omvat, zoals "Moslims eten zulk vreemd voedsel".
Het onderscheid kunnen maken tussen zwakke en sterke islamofobie zal ons niet alleen helpen om haat beter op te sporen en te verwijderen, maar ook om de dynamiek van islamofobie te begrijpen, radicaliseringsprocessen onderzoeken waarbij een persoon steeds meer islamofoob wordt, en slachtoffers beter te helpen.
Krediet:Vidgen en Yasseri
De parameters instellen
De tool die we hebben gemaakt, wordt een gesuperviseerde machine learning-classificatie genoemd. De eerste stap om er een te maken, is het maken van een trainings- of testdataset - zo leert de tool tweets toe te wijzen aan elk van de klassen:zwakke islamofobie, sterke islamofobie en geen islamofobie. Het maken van deze dataset is een moeilijk en tijdrovend proces omdat elke tweet handmatig moet worden gelabeld, dus de machine heeft een basis om van te leren. Een ander probleem is dat het detecteren van haatspraak inherent subjectief is. Wat ik als sterk islamofoob beschouw, je zou kunnen denken dat is zwak, en vice versa.
We hebben twee dingen gedaan om dit te verminderen. Eerst, we hebben veel tijd besteed aan het maken van richtlijnen voor het labelen van de tweets. Tweede, we hadden drie experts die elke tweet labelden, en gebruikte statistische tests om te controleren hoeveel ze het eens waren. We begonnen met 4 000 tweets, bemonsterd uit een dataset van 140 miljoen tweets die we hebben verzameld van maart 2016 tot augustus 2018. De meeste van de 4, 000 tweets drukten geen islamofobie uit, dus we hebben er veel verwijderd om een evenwichtige dataset te maken, bestaande uit 410 sterke, 484 zwak, en 447 geen (in totaal 1, 341 tweets).
De tweede stap was het bouwen en afstemmen van de classifier door technische functies te ontwikkelen en een algoritme te selecteren. Functies zijn wat de classifier gebruikt om elke tweet daadwerkelijk aan de juiste klasse toe te wijzen. Ons belangrijkste kenmerk was een woordinbeddingsmodel, een deep learning-model dat individuele woorden weergeeft als een vector van getallen, die vervolgens kan worden gebruikt om woordovereenkomst en woordgebruik te bestuderen. We identificeerden ook enkele andere kenmerken van de tweets, zoals de grammaticale eenheid, sentiment en het aantal vermeldingen van moskeeën.
Toen we onze classificatie eenmaal hadden gebouwd, de laatste stap was om het te evalueren, wat we deden door het toe te passen op een nieuwe dataset van volledig ongeziene tweets. We hebben 100 tweets geselecteerd die aan elk van de drie klassen zijn toegewezen, dus 300 in totaal, en lieten onze drie deskundige codeurs ze opnieuw labelen. Hiermee kunnen we de prestaties van de classifier evalueren, het vergelijken van de labels die door onze classifier zijn toegewezen met de werkelijke labels.
De belangrijkste beperking van de classifer was dat het moeite had om zwakke islamofobe tweets te identificeren, omdat deze vaak overlapten met zowel sterke als niet-islamofobe tweets. Dat gezegd hebbende, algemeen, zijn prestaties waren sterk. De nauwkeurigheid (het aantal correct geïdentificeerde tweets) was 77% en de precisie was 78%. Vanwege ons rigoureuze ontwerp- en testproces, we kunnen erop vertrouwen dat de classifier waarschijnlijk op dezelfde manier presteert wanneer deze op grote schaal "in het wild" wordt gebruikt op ongeziene Twitter-gegevens.
Onze classificatie gebruiken
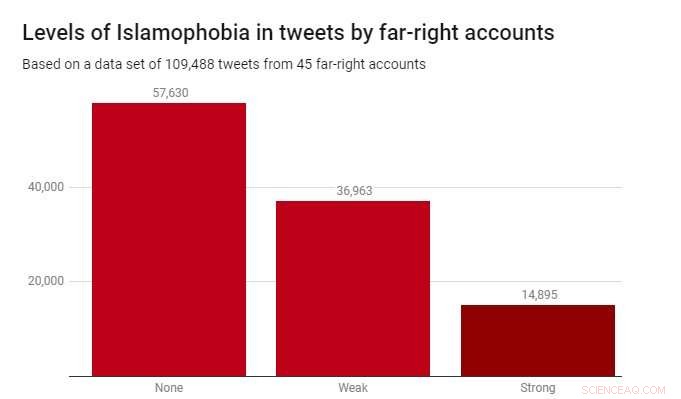
We hebben de classifier toegepast op een dataset van 109, 488 tweets geproduceerd door 45 extreemrechtse accounts in 2017. Deze werden geïdentificeerd door de liefdadigheidsinstelling Hope Not Hate in hun State of Hate-rapporten van 2015 en 2017. Onderstaande grafiek laat de resultaten zien.
Hoewel de meeste tweets – 52,6% – niet islamofoob waren, zwakke islamofobie kwam aanzienlijk vaker voor (33,8%) dan sterke islamofobie (13,6%). Dit suggereert dat de meeste islamofobie in deze extreemrechtse verslagen subtiel en indirect is, in plaats van agressief of openlijk.
Het opsporen van islamofobe haatzaaiende uitlatingen is een reële en dringende uitdaging voor regeringen, technologiebedrijven en academici. Helaas, dit is een probleem dat niet zal verdwijnen – en er zijn geen eenvoudige oplossingen. Maar als we haatdragende taal en extremisme uit online ruimtes willen verwijderen, en sociale-mediaplatforms veilig te maken voor iedereen die ze gebruikt, dan moeten we beginnen met de juiste tools. Ons werk laat zien dat het heel goed mogelijk is om deze tools te maken - om niet alleen automatisch hatelijke inhoud te detecteren, maar dit ook op een genuanceerde en fijnmazige manier te doen.
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 
 Wetenschappers stomverbaasd om planten te ontdekken onder kilometers diep Groenlands ijs
Wetenschappers stomverbaasd om planten te ontdekken onder kilometers diep Groenlands ijs- Nationaal onderzoek toont aan dat oceaan- en kustrecreatie big business is
- Palau plant zonneschermverbod om koraal te redden
- Waarom appartementsbewoners kamerplanten nodig hebben
- Bij EPA, coronavirus verstoort onderzoek en roept vragen op over impact op luchtkwaliteit
Hoofdlijnen
- Hoe zijn genen, DNA en chromosomen met elkaar verbonden?
- Hoe extremofielen werken
- Waarom lijden 600 meisjes in Mexico aan collectieve hysterie?
- Vier hoofdgroepen organische verbindingen waaruit levende organismen bestaan
- Een bijtend rapport:onderzoek toont aan dat klimaatverandering een grote bedreiging vormt voor hommels
- Glimlachende menselijke gezichten zijn aantrekkelijk voor honden - dankzij oxytocine
- DNA Extraction by Spooling Method
- Waarom is fotosynthese belangrijk voor mensen?
- De gemiddelde levensduur van skeletspiercellen
- EV-kijkers worden poëtisch over Canoo-set voor 2021

- Legeronderzoekers stellen zich een derde arm voor soldaten voor

- Politie overweegt drone neer te halen na sluiting van de luchthaven van Londen

- Kerncentrale Three Mile Island sluit op 30 september

- LeanShips:aanzienlijke brandstofbesparing voor schepen met verstelbare schroeven


 Waarom haten sommige mensen het geluid van kauwen? Wetenschappers hebben misschien het antwoord
Waarom haten sommige mensen het geluid van kauwen? Wetenschappers hebben misschien het antwoord - Plankton is de kleinste onbezongen held op aarde
- Heb je het warm en geïrriteerd? Het is ingewikkeld
- De relatie tussen vocht & temperatuur
- Afbeelding:Hubbles kosmische atlas
- Ben je dol op de sterren? Astronomen hebben een unieke suggestie voor Valentijnsdag
- Ingenieurs werken samen aan goedkope DNA-sequencing-methode
- Hoe particuliere gevangenissen het immigratiebeleid beïnvloeden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
