Wetenschap
Op weg naar taalinferentie in de geneeskunde

Prompt getoond aan clinici voor annotaties. Krediet:IBM
De afgelopen tijd is er aanzienlijke vooruitgang geboekt in het begrijpen van natuurlijke taal door AI, zoals machinevertaling en het beantwoorden van vragen. Een belangrijke reden achter deze ontwikkelingen is het creëren van datasets, die machine learning-modellen gebruiken om een specifieke taak te leren en uit te voeren. De opbouw van dergelijke datasets in het open domein bestaat vaak uit tekst afkomstig uit nieuwsartikelen. Dit wordt meestal gevolgd door het verzamelen van menselijke annotaties van crowdsourcingplatforms zoals Crowdflower, of Amazon Mechanical Turk.
Echter, taal die wordt gebruikt in gespecialiseerde domeinen zoals geneeskunde is heel anders. Het vocabulaire dat door een arts wordt gebruikt bij het schrijven van een klinische notitie is heel anders dan de woorden in een nieuwsartikel. Dus, taaltaken in deze kennisintensieve domeinen kunnen niet gecrowdsourcet worden, aangezien dergelijke annotaties domeinexpertise vereisen. Echter, het verzamelen van annotaties van domeinexperts is ook erg duur. Bovendien, klinische gegevens zijn privacygevoelig en kunnen daarom niet gemakkelijk worden gedeeld. Deze hindernissen hebben de bijdrage van taaldatasets in het medische domein geremd. Door deze uitdagingen validatie van goed presterende algoritmen uit het open domein op klinische gegevens blijft niet onderzocht.
Om deze lacunes aan te pakken, we werkten samen met het Massachusetts Institute of Technology om MedNLI te bouwen, een dataset geannoteerd door artsen, het uitvoeren van een natuurlijke taalinferentietaak (NLI) en gebaseerd op de medische geschiedenis van patiënten. Het belangrijkste is, we maken het openbaar beschikbaar voor onderzoekers om de verwerking van natuurlijke taal in de geneeskunde te bevorderen.
We werkten samen met de onderzoekslaboratoria van MIT Critical Data om een dataset voor natuurlijke taalinferentie in de geneeskunde te construeren. We gebruikten klinische aantekeningen uit hun "Medical Information Mart for Intensive Care" (MIMIC) database, dat is misschien wel de grootste openbaar beschikbare database met patiëntendossiers. De clinici in ons team suggereerden dat de medische geschiedenis van een patiënt essentiële informatie bevat waaruit bruikbare conclusies kunnen worden getrokken. Daarom, we haalden de medische geschiedenis uit het verleden uit klinische aantekeningen in MIMIC en presenteerden een zin uit deze geschiedenis als uitgangspunt aan een clinicus. Vervolgens werd hen gevraagd om hun medische expertise te gebruiken en drie zinnen te genereren:een zin die absoluut waar was over de patiënt, gezien het uitgangspunt; een zin die absoluut onwaar was, en tot slot een zin die mogelijk waar zou kunnen zijn.
Over een paar maanden, we hebben willekeurig 4 monsters genomen, 683 van dergelijke gebouwen en werkte samen met vier clinici om MedNLI te bouwen, een dataset van 14, 049 premisse-hypothese paren. In het open domein, andere voorbeelden van op dezelfde manier gebouwde datasets zijn de Stanford Natural Language Inference-dataset, die is samengesteld met de hulp van 2, 500 werknemers op Amazon Mechanical Turk en bestaat uit 0,5 miljoen premisse-hypotheseparen waarbij premissezinnen werden getrokken uit bijschriften van Flickr-foto's. MultiNLI is een andere en bestaat uit premissetekst uit specifieke genres zoals fictie, blogs, telefoongesprekken, enzovoort.
Dr. Leo Anthony Celi (Principal Scientist voor MIMIC) en Dr. Alistair Johnson (Research Scientist) van MIT Critical Data hebben met ons samengewerkt om MedNLI openbaar beschikbaar te maken. Ze creëerden de MIMIC Derived Data-repository, waaraan MedNLI optrad als de eerste bijdrage aan de natuurlijke taalverwerkingsdataset. Elke onderzoeker met toegang tot MIMIC kan MedNLI ook downloaden van deze repository.
Hoewel van bescheiden omvang in vergelijking met de open domein datasets, MedNLI is groot genoeg om onderzoekers te informeren bij het ontwikkelen van nieuwe machinale leermodellen voor taalinferentie in de geneeskunde. Het belangrijkste is, het biedt interessante uitdagingen die om innovatieve ideeën vragen. Overweeg een paar voorbeelden uit MedNLI:
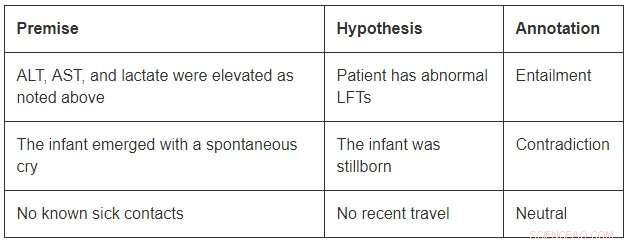
Om gevolgtrekking in het eerste voorbeeld af te sluiten, men zou de afkortingen ALT moeten kunnen uitbreiden, AST, en LFT's; begrijpen dat ze verwant zijn; en verder concluderen dat een verhoogde meting abnormaal is. Het tweede voorbeeld toont een subtiele gevolgtrekking van de conclusie dat het verschijnen van een baby een beschrijving is van zijn geboorte. Eindelijk, het laatste voorbeeld laat zien hoe algemene wereldkennis wordt gebruikt om gevolgtrekkingen af te leiden.
State-of-the-art deep learning-algoritmen kunnen zeer goed presteren op taaltaken, omdat ze het potentieel hebben om zeer goed te worden in het leren van een nauwkeurige mapping van input naar output. Dus, training op een grote dataset geannoteerd met behulp van crowd-sourced annotaties is vaak het recept voor succes. Echter, ze hebben nog steeds geen generalisatievermogen in omstandigheden die verschillen van die tijdens de training. Dit is nog uitdagender in gespecialiseerde en kennisintensieve domeinen zoals geneeskunde, waar trainingsgegevens beperkt zijn en taal veel genuanceerder is.
Eindelijk, hoewel er grote vooruitgang is geboekt bij het end-to-end leren van een taaltaak, er is nog steeds behoefte aan aanvullende technieken die door experts samengestelde kennisbanken in deze modellen kunnen opnemen. Bijvoorbeeld, SNOMED-CT is een door experts samengestelde medische terminologie met meer dan 300K concepten en relaties tussen de termen in zijn dataset. Binnen MedNLI, we hebben eenvoudige wijzigingen aangebracht in bestaande diepe neurale netwerkarchitecturen om kennis uit kennisbanken zoals SNOMED-CT te infuseren. Echter, een grote hoeveelheid kennis blijft nog onaangeboord.
We hopen dat MedNLI nieuwe onderzoeksrichtingen opent in de gemeenschap van natuurlijke taalverwerking.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Wat eet de kardinaal?
Wat eet de kardinaal? - 10, 000 geëvacueerd bij overstromingen in Canada terwijl reddingswerkers zoeken naar huisdieren
- Wat is de Overeenkomst van Parijs?
- Voor het behoud van koraalriffen zijn nieuwe technologieën nodig
- Duiken in het binnenste van de aarde helpt wetenschappers de geheimen van diamantvorming te ontrafelen
Hoofdlijnen
- Wetenschappers onderzoeken de gevolgen voor de nationale veiligheid van genbewerking
- Een fokprogramma voor natuurbehoud opzetten om de laatste saola te redden
- Computersimulaties onthullen wortels van resistentie tegen geneesmiddelen
- Studie belicht botanische vooroordelen
- Nieuwe studie verifieert meer manieren om te overleven voor bedreigde Chinook-zalm in de winter
- Krachten van spinnengif onderzocht in VR-game
- Kan graszaad net zo goed groeien op een lavasteen als op aarde?
- Deskundigen adviseren om benchmarking te gebruiken om bedrijven met een hoog antibioticagebruik te identificeren
- Hoe zal de aarde er over 50 uitzien,
- Autonoom systeem verbetert milieubemonstering op zee
- Volkswagen zegt gezien bestuurswisselingen, kan nieuwe CEO benoemen

- AI-aangedreven avatar op technische show aangeprezen als kunstmatige mens

- Zacht, sociale robot brengt gezelligheid in huis robotica

- Uit enquête blijkt dat het vertrouwen van het publiek in Facebook is gedaald na Cambridge Analytical-schandaal


 Fossielenjagen in Oklahoma
Fossielenjagen in Oklahoma - Hoe concentratie te berekenen in PPM
- Innovatieve technologieën en beleid kunnen de landbouw ecologisch duurzaam maken
- Landsat-satellietgegevens waarschuwen voor schadelijke algenbloei
- Wat doet de temporale kwab?
- Hoeveel is een mossel waard voor een kustgemeenschap?
- Waarom oceaanvervuiling een duidelijk gevaar is voor de menselijke gezondheid
- Nieuw sphenisciform fossiel lost verder bauplan van uitgestorven reuzenpinguïns op
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | Italian |

-
Wetenschap © https://nl.scienceaq.com
