Wetenschap
Een modelvrije, diepgaande leeraanpak om neurale controleproblemen aan te pakken
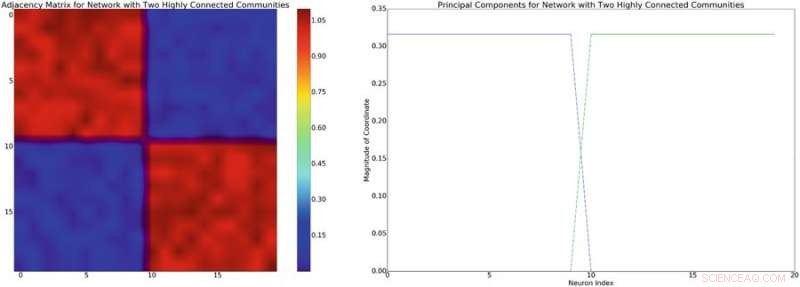
Links:voorbeeld van een aangrenzende matrix met een benaderde blokdiagonale structuur. Uitgaande van een lineair mengselmodel van neuronale interacties, deze netwerkstructuur zal een diagonale covariantie van ongeveer blok met een vergelijkbare structuur induceren. Rechts:de belangrijkste componenten die zijn gekoppeld aan de aangrenzende matrix aan de linkerkant. Krediet:Mitchell &Petzold
Brian Mitchell en Linda Petzold, twee onderzoekers van de Universiteit van Californië, hebben onlangs modelvrij diep versterkend leren toegepast op modellen van neurale dynamiek, het behalen van zeer veelbelovende resultaten.
Reinforcement learning is een gebied van machine learning, geïnspireerd door gedragspsychologie, dat algoritmen traint om bepaalde taken effectief uit te voeren, met behulp van een systeem gebaseerd op beloning en straf. Een prominente mijlpaal op dit gebied is de ontwikkeling van het Deep-Q-Network (DQN), die aanvankelijk werd gebruikt om een computer te trainen om Atari-spellen te spelen.
Modelvrij versterkend leren is toegepast op een verscheidenheid aan problemen, maar DQN wordt over het algemeen niet gebruikt. De voornaamste reden hiervoor is dat DQN een beperkt aantal acties kan voorstellen, terwijl fysieke problemen over het algemeen een methode vereisen die een continuüm van acties kan voorstellen.
Bij het lezen van bestaande literatuur over neurale controle, Mitchell en Petzold merkten het wijdverbreide gebruik van een klassiek paradigma op voor het oplossen van neurale controleproblemen met machine learning-strategieën. Eerst, de ingenieur en experimentator zijn het eens over het doel en de opzet van hun onderzoek. Vervolgens, de laatste voert het experiment uit en verzamelt gegevens, die later door de ingenieur zal worden geanalyseerd en gebruikt om een model van het betreffende systeem te bouwen. Eindelijk, de ingenieur ontwikkelt een controller voor het model en het apparaat implementeert deze controller.
Resultaten van het experiment dat oscillatie regelt in de faseruimte gedefinieerd door een enkele hoofdcomponent. De eerste grafiek van boven is een grafiek van de invoer in de geactiveerde cel in de tijd; de tweede plot van boven is een plot van de pieken van het hele netwerk, waar verschillende kleuren overeenkomen met verschillende cellen; de derde grafiek van boven komt overeen met de membraanpotentiaal van elke cel in de tijd; de vierde van de bovenste grafiek toont de doeloscillatie; de onderste grafiek toont de waargenomen oscillatie. Het beleid, ondanks het leveren van input aan slechts een enkele cel, is in staat om de doeloscillatie in de waargenomen faseruimte bij benadering te induceren. Krediet:Mitchell &Petzold 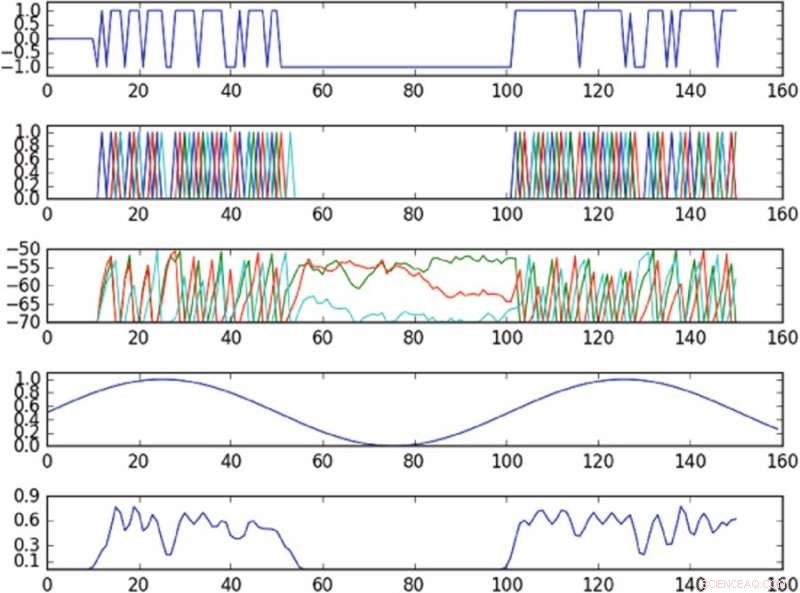
De onderzoekers pasten een modelvrije leermethode voor versterking aan, genaamd "diepe deterministische beleidsgradiënten" (DDPG) en pasten deze toe op modellen van neurale dynamiek op laag en hoog niveau. Ze kozen specifiek voor DDPG omdat het een zeer flexibel kader biedt, waarbij de gebruiker de systeemdynamiek niet hoeft te modelleren.
Recent onderzoek heeft uitgewezen dat modelvrije methoden over het algemeen te veel experimenten met de omgeving vergen, waardoor het moeilijker wordt om ze toe te passen op meer praktische problemen. Niettemin, de onderzoekers ontdekten dat hun modelvrije benadering beter presteerde dan de huidige modelgebaseerde methoden en in staat was om moeilijkere neurale dynamische problemen op te lossen, zoals de controle van trajecten door een latente faseruimte van een onderbekrachtigd netwerk van neuronen.
"Voor de problemen die we in dit artikel hebben besproken, modelvrije benaderingen waren behoorlijk efficiënt en vereisten helemaal niet veel experimenten, wat suggereert dat voor neurale problemen, state-of-the-art controllers zijn praktischer bruikbaar dan mensen misschien dachten, ' zei Mitchel.
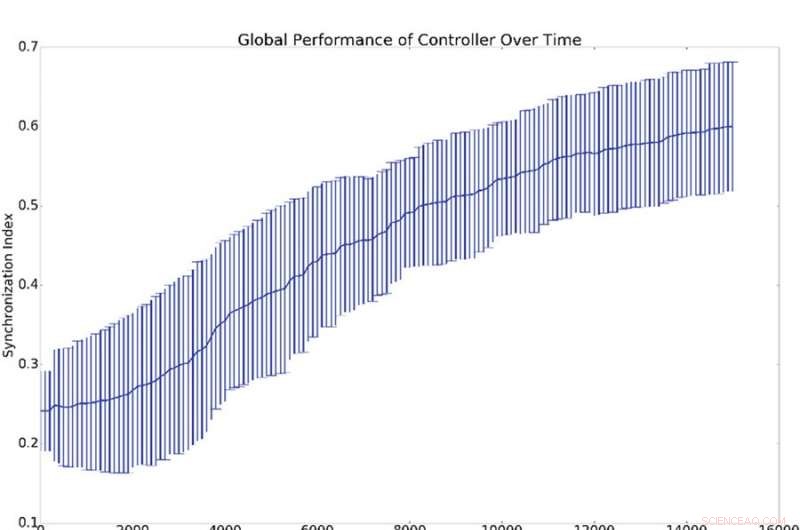
Samenvattende resultaten van 10 synchronisatie-experimenten. (a) Geeft het gemiddelde en de standaarddeviatie van de globale synchronisatie weer, (d.w.z. q uit vergelijking 16), ten opzichte van het aantal opleidingsperioden van de verantwoordelijke. (b) Toont histogrammen die het synchronisatieniveau aantonen van alle netwerkoscillatoren met de referentieoscillator (d.w.z. qi uit vergelijking 16). Dat is, een punt op de blauwe of groene curve toont de waarschijnlijkheid van het hebben van een bepaalde waarde voor qi. Het blauwe histogram toont de tellingen vóór de training, terwijl het groene histogram de tellingen na de training toont. De gemiddelde synchronisatie met de referentie, qi, is veel hoger dan globale synchronisatie, Q, wat wordt verklaard door het feit dat synchronisatie met de referentie gemakkelijker te induceren is dan globale synchronisatie. Krediet:Mitchell &Petzold
Mitchell en Petzold voerden hun onderzoek uit als een simulatie, daarom moeten belangrijke praktische en veiligheidsaspecten in overweging worden genomen voordat hun methode in klinische omgevingen kan worden geïntroduceerd. Verder onderzoek dat modellen in modelvrije benaderingen opneemt, of dat grenzen stelt aan modelvrije controllers, zou kunnen helpen om de veiligheid te verbeteren voordat deze methoden klinische instellingen binnenkomen.
In de toekomst, de onderzoekers zijn ook van plan te onderzoeken hoe neurale systemen zich aanpassen aan controle. Menselijke hersenen zijn zeer dynamische organen die zich aanpassen aan hun omgeving en veranderen als reactie op externe stimulatie. Dit kan een competitie tussen de hersenen en de controller veroorzaken, vooral wanneer hun doelstellingen niet op elkaar zijn afgestemd.
"Vaak, we willen dat de controller wint en het ontwerp van controllers die altijd winnen is een belangrijk en interessant probleem, "zei Mitchell. "Bijvoorbeeld, in het geval dat het te controleren weefsel een ziek hersengebied is, deze regio kan een bepaalde progressie hebben die de controller probeert te corrigeren. Bij veel ziekten deze progressie kan behandeling weerstaan (bijv. een tumor die zich aanpast om chemotherapie te verdrijven is een canoniek voorbeeld), maar de huidige modelvrije benaderingen passen zich niet goed aan dit soort veranderingen aan. Het verbeteren van modelvrije controllers om de aanpassing van de hersenen beter aan te kunnen, is een interessante richting die we onderzoeken."
Het onderzoek is gepubliceerd in Wetenschappelijke rapporten .
© 2018 Tech Xplore

Hoofdlijnen
- Hoe MRNA van een cel te isoleren
- Orgelsystemen betrokken bij homeostase
- Nieuwe mutaties in iPS-cellen zijn voornamelijk geconcentreerd in niet-transcriptionele regio's
- Macht overdragen aan staten zal de bescherming van bedreigde diersoorten niet verbeteren
- Poema's zijn socialer dan eerder werd gedacht
- Op bewijs gebaseerde tips om uw geheugen te verbeteren
- Overeenkomsten van mitose en meiose
- Stamboom van Homo Sapiens blijft evolueren
- Cellulaire ademhaling: definitie, vergelijking en stappen
- Bytedance:het Chinese bedrijf achter de wereldwijde TikTok-rage

- Patches om het Sudo-hulpprogramma minder kwetsbaar te maken voor misbruik
- Ex-Nissan-chef Ghosn ontkent beschuldigingen:media

- Disney lanceert streaming met verminderde bandbreedte in 7 Europese landen

- Twitter scherpt EU-regels voor politieke advertenties aan voorafgaand aan verkiezingen


 Doorbraak in directe activering van CO2 en CH4 tot vloeibare brandstoffen en chemicaliën
Doorbraak in directe activering van CO2 en CH4 tot vloeibare brandstoffen en chemicaliën- De meridionale wind op Venus werd voor het eerst op beide hemisferen gedetecteerd
- Noord-Amerikaanse autofabrikanten roepen op tot hervatting van NAFTA-gesprekken
- Out of the blue:Middeleeuwse fragmenten leveren verrassingen op
- Hoe spraakherkenningstechnieken het gedrag van vulkanen helpen voorspellen
- Onderzoekers stellen een nieuwe methode voor om het bestaan van Majorana-fermionen te verifiëren
- DNA is gecondenseerd in welke fasen?
- Optogenetica - neuronen aansturen met licht - kan leiden tot genezing van PTSS, Alzheimer
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
