Wetenschap
Richtlijnen voor een gestandaardiseerd gegevensformaat voor gebruik in taaloverschrijdende studies
Een wereldkaart met datapunten, waarvoor de onderzoekers van plan zijn om uniforme gegevens te verzamelen (bijv. gegevens die direct vergelijkbaar zijn) met behulp van de richtlijnen in de paper. Krediet:OpenStreetMap. Forkel et al. 2018. Cross-linguïstische gegevensformaten, het bevorderen van het delen en hergebruiken van gegevens in vergelijkende taalkunde. Wetenschappelijke gegevens .
Een internationaal team van onderzoekers, leden van het Cross-Linguistic Data Formats Initiative (CLDF) onder leiding van het Max Planck Institute for the Science of Human History, heeft nieuwe richtlijnen voor taaloverschrijdende gegevensformaten voorgesteld om het delen en vergelijken van gegevens tussen het groeiende aantal grote taalkundige databases wereldwijd te vergemakkelijken. Dit formaat biedt een softwarepakket, een basisontologie en gebruiksvoorbeelden.
Er is een toenemend aantal taalkundige databases wereldwijd, het vergroten van de mogelijkheid van een uitgebreid netwerk voor potentiële vergelijkende studies. Echter, deze databases worden over het algemeen onafhankelijk van elkaar gemaakt, en hebben vaak een unieke en smalle focus. Dit betekent dat de formaten die worden gebruikt voor het coderen van de gegevens vaak verschillen, problemen veroorzaken bij het vergelijken van gegevens tussen databases.
Het Cross-Linguistic Data Formats Initiative (CLDF) is een poging om deze problemen op te lossen. In een paper gepubliceerd in Wetenschappelijke gegevens , de CLDF bevat voorgestelde richtlijnen voor een gestandaardiseerd formaat voor taalkundige databases, en levert tevens een softwarepakket, een basisontologie en gebruiksvoorbeelden van best practices. Het doel van deze inspanning is om het delen en hergebruiken van gegevens in de vergelijkende taalkunde te vergemakkelijken.
De CLDF biedt een gegevensmodel dat ten grondslag ligt aan zijn aanbevelingen dat eenvoudig, maar toch expressief, en is gebaseerd op het datamodel dat eerder is ontwikkeld voor het Cross-Linguistic Data-project. Dit model heeft vier hoofdentiteiten:(a) talen; (b) parameters; (c) waarden; en (d) bronnen. In het model, elke waarde is gerelateerd aan een parameter en een taal, en kan gebaseerd zijn op meerdere bronnen. Daarnaast zijn er verwijzingen naar bronnen, en referenties kunnen ook contexten hebben (die, bijvoorbeeld, voor gedrukte referenties zouden paginanummers zijn).
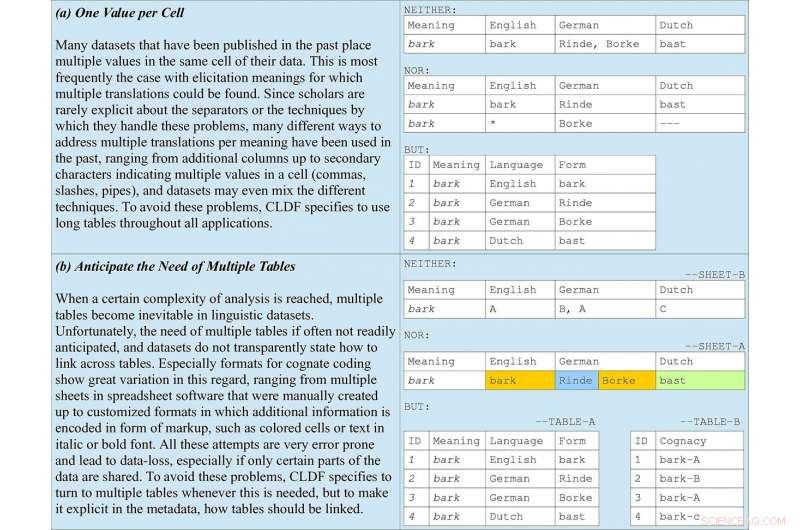
Basisregels voor datacodering opgenomen in de richtlijnen, het nemen van verwante codering in woordenlijsten als voorbeeld. (a) illustreert waarom lange tabellen de voorkeur moeten krijgen in alle toepassingen. (b) onderstreept het belang van het anticiperen op meerdere tabellen, samen met metagegevens die aangeven hoe ze moeten worden gekoppeld. Krediet:Forkel et al. 2018. Cross-linguïstische gegevensformaten, het bevorderen van het delen en hergebruiken van gegevens in vergelijkende taalkunde. Wetenschappelijke gegevens .
Het CLDF-gegevensmodel is een pakketindeling waarin een gegevensset zou bestaan uit een set gegevensbestanden met tabellen, en een beschrijvend bestand dat de relaties tussen de tabellen definieert. Elk linguïstisch gegevenstype zou een CLDF-module en aanvullende componenten hebben, dat zijn de aspecten van de gegevens in de module die terugkeren in meerdere gegevenstypen. De CLDF-modules zouden ook termen uit de CLDF-ontologie bevatten. De ontologie is een lijst van woordenschat die objecten en eigenschappen vertegenwoordigt met bekende semantiek in vergelijkende taalkunde. Dit maakt het voor gebruikers mogelijk om op een uniforme manier naar deze termen te verwijzen.
Een softwarepakket om validatie en manipulatie mogelijk te maken
De CLDF-specificaties gebruiken veelvoorkomende bestandsindelingen, zoals CSV, JSON en BibTeX—die breed worden ondersteund, met als doel dat deze bestanden gemakkelijk kunnen worden gelezen en geschreven op veel platforms. Nog belangrijker, het gestandaardiseerde formaat stelt onderzoekers zonder programmeervaardigheden in staat om toegang te krijgen tot de gegevens en deze te manipuleren met reeds bestaande tools, om te voorkomen dat het pakket alleen wordt beperkt tot onderzoekers met voldoende programmeervaardigheden om hun eigen tools te maken. Om dit te vergemakkelijken, de CLDF heeft een "kookboek"-opslagplaats gemaakt voor scripts voor gebruik met de CLDF-specificaties.
"We willen toegang tot deze gegevens bieden en de mogelijkheid bieden om ze te vergelijken met zoveel mogelijk onderzoekers, " zegt Johann-Mattis List van het Max Planck Institute for the Science of Human History. Robert Forkel, een van de drijvende krachten achter het CLDF-initiatief, merkt ook op dat het CLDF-formaat niet beperkt is tot alleen taalkundige gegevens, maar kan ook databases met culturele en geografische gegevens bevatten, bijvoorbeeld. "CLDF kan het testen van vragen over de interactie tussen taalkundige, cultureel, en omgevingsfactoren in taalkundige en culturele evolutie."
 Het regenseizoen begint meestal eerder in Noord-Centraal-Azië
Het regenseizoen begint meestal eerder in Noord-Centraal-Azië- Welk soort weer komt een afgezonderd front met zich mee?
- Het verband tussen fracking en aardbevingen begrijpen
- NASA ziet Ex-Tropical Cyclone 03S lijken op een frontaal systeem
- Trumps plannen voor offshore olieboringen negeren de lessen van BP Deepwater Horizon
Hoofdlijnen
- Doorbraak in genetisch onderzoek om gerstproductie te stimuleren
- Difference Between Mutation & Genetic Drift
- De juiste manier om DNA te repareren
- Slangenmans gifgewoonte houdt hoop op nieuw tegengif
- Nieuw apparaat zoomt in op microbengedrag op de juiste schaal
- Is geluk besmettelijk?
- Hoe beïnvloedt de temperatuur het metabolisme?
- Valse oogvlekken intimideren roofdieren, onderzoekers vinden
- Onvolledige dominantie: definitie, uitleg en voorbeeld
- Waarom onze hersenen kansen missen om te verbeteren door middel van aftrekken

- Mensen van kleur steunen klimaatactie, maar weinigen krijgen er de eer voor

- Eigendom van het strand is afhankelijk van de staatswet en getijdenlijnen

- Was landbouw de grootste blunder in de menselijke geschiedenis?

- Analyse van Trumps tweets onthult systematische omleiding van de media


 Hoe maak je nep sneeuw met bakken Soda
Hoe maak je nep sneeuw met bakken Soda- Hoe een waterbarometer te lezen
- Hoe kPa te converteren naar kN /m
- Ruimtelijke vaardigheden hoger bij degenen die in de kindertijd met constructiespeelgoed en videogames speelden:studie
- Zandduinen maken voor een schoolproject
- Kubieke voet van een cilinder berekenen
- Giftige mannelijkheid is onveilig... voor mannen
- Onverwacht snelle geleidingselektronen in Na3Bi
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
