Wetenschap
Open-sourcesoftware voor gegevens uit de hoge-energiefysica

Voorgestelde filamenten van donkere materie rond Jupiter zouden deel kunnen uitmaken van de mysterieuze 95 procent van de massa-energie van het universum. Krediet:NASA/JPL-Caltech
Het grootste deel van het universum is donker, met donkere materie en donkere energie die meer dan 95 procent van zijn massa-energie uitmaken. Toch weten we weinig over donkere materie en energie. Om antwoorden te vinden, wetenschappers voeren enorme natuurkundige experimenten uit met hoge energie. Het analyseren van de resultaten vereist high-performance computing - soms in evenwicht met industriële trends.
Na vier jaar computergebruik voor het Large Hadron Collider CMS-experiment op CERN bij Genève, Zwitserland - onderdeel van het werk dat het Higgs-deeltje onthulde - Oliver Gutsche, een wetenschapper bij het Fermi National Accelerator Laboratory van het Department of Energy (DOE), wendde zich tot de zoektocht naar donkere materie. "Het Higgs-deeltje was voorspeld, en we wisten ongeveer waar we moesten kijken, "zegt hij. "Met donkere materie, we weten niet wat we zoeken."
Om meer te weten te komen over donkere materie, Gutsche heeft meer gegevens nodig. Zodra die informatie beschikbaar is, natuurkundigen moeten het ontginnen. Ze onderzoeken rekentools voor het werk, inclusief Apache Spark open source software.
Bij het zoeken naar donkere materie, natuurkundigen bestuderen resultaten van botsende deeltjes. "Dit is triviaal om te parallelliseren, " de taak in stukken breken om sneller antwoorden te krijgen, Gutsche legt uit. "Twee pc's kunnen elk een botsing verwerken, " wat betekent dat onderzoekers een computerraster kunnen gebruiken om gegevens te analyseren.
Veel van het werk in de hoge-energiefysica, Hoewel, hangt af van de software die de wetenschappers ontwikkelen. "Als onze afgestudeerde studenten en postdocs alleen onze eigen tools kennen, dan krijgen ze problemen als ze naar de industrie gaan, " waar dergelijke software niet beschikbaar is, Gutsche notities. 'Dus ik begon Spark te onderzoeken.'
Spark is een tool voor gegevensreductie die is gemaakt voor ongestructureerde tekstbestanden. Dat zorgt voor een uitdaging:toegang krijgen tot de gegevens van de hoge-energiefysica, die in een objectgeoriënteerd formaat zijn. Fermilab computerwetenschappers Saba Sehrish en Jim Kowalkowski pakken de taak aan.
Spark beloofde vanaf het begin, met enkele bijzonder interessante functies, zegt Sehrish. "Een was in het geheugen, grootschalige gedistribueerde verwerking" via interfaces op hoog niveau, waardoor het gemakkelijk te gebruiken is. "Je wilt niet dat wetenschappers zich zorgen maken over het verspreiden van gegevens en het schrijven van parallelle code, ' zegt ze. Spark regelt dat.
Een ander aantrekkelijk kenmerk:Spark is een ondersteund onderzoeksplatform bij het National Energy Research Scientific Computing Center (NERSC), een DOE Office of Science gebruikersfaciliteit in het Lawrence Berkeley National Laboratory van de DOE. "Dit geeft ons een ondersteuningsteam dat het kan afstemmen, " zegt Kowalkowski. Computerwetenschappers zoals Sehrish en Kowalkowski kunnen mogelijkheden toevoegen, maar om de onderliggende code zo efficiënt mogelijk te laten werken, zijn Spark-specialisten nodig, sommigen van hen werken bij NERSC.
Kowalkowski vat de gewenste functies van Spark samen als "automatisch schalen, geautomatiseerd parallellisme en een redelijk programmeermodel."
Kortom, hij en Sehrish willen een systeem bouwen waarmee onderzoekers een analyse kunnen uitvoeren die buitengewoon goed presteert op grootschalige machines, zonder complicaties en via een eenvoudige gebruikersinterface.
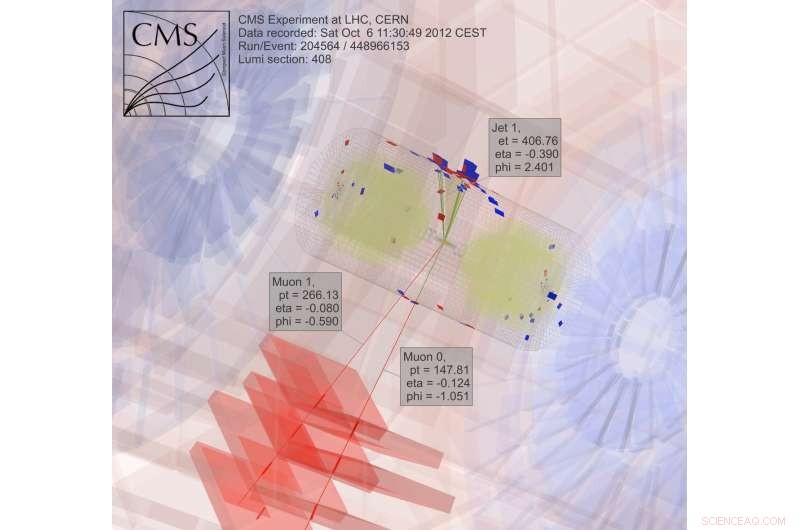
Om donkere materie te zoeken, wetenschappers verzamelen en analyseren resultaten van botsende deeltjes, een extreem rekenintensief proces. Krediet:CMS CERN
Gewoon gemakkelijk te gebruiken, Hoewel, is niet voldoende als het gaat om gegevens uit de hoge-energiefysica. Spark lijkt tot op zekere hoogte te voldoen aan zowel gebruiksgemak als prestatiedoelen. Onderzoekers onderzoeken nog steeds enkele aspecten van de prestaties voor toepassingen in de fysica met hoge energie, maar computerwetenschappers kunnen niet alles hebben. "Er is een compromis, "Sehrish stelt. "Als je op zoek bent naar meer prestaties, je krijgt geen gebruiksgemak."
De wetenschappers van Fermilab selecteerden Spark als een eerste keuze voor het verkennen van big data-wetenschap, en donkere materie is slechts de eerste toepassing die wordt getest. "We hebben verschillende real-use cases nodig om de haalbaarheid te begrijpen van het gebruik van Spark voor een analysetaak, " zegt Sehrish. Met wetenschappers als Gutsche van Fermilab, donkere materie was een goede plek om te beginnen. Sehrish en Kowalkowski willen het leven vereenvoudigen van wetenschappers die de analyse uitvoeren. "We werken met wetenschappers om hun gegevens te begrijpen en werken met hun analyse, ', zegt Sehrish. 'Dan kunnen we ze helpen datasets beter te organiseren, analysetaken beter organiseren."
Als eerste stap in dat proces is Sehrish en Kowalkowski moeten gegevens van hoge-energie-fysica-experimenten in Spark krijgen. Opmerkingen Kowalkowski, "Je hebt petabytes aan data in specifieke experimentele formaten die je moet omzetten in iets bruikbaars voor een ander platform."
De startgegevens voor de dark-materie-implementatie zijn geformatteerd voor high-throughput computerplatforms, maar Spark kan die configuratie niet aan. Dus software moet het originele gegevensformaat lezen en converteren naar iets dat goed werkt met Spark.
Door dit te doen, Sehrish legt uit, "je moet elke beslissing bij elke stap overwegen, want hoe je de data structureert, hoe je het in het geheugen leest en bewerkingen ontwerpt en implementeert voor hoge prestaties is allemaal met elkaar verbonden."
Elk van deze stappen voor gegevensverwerking heeft invloed op de prestaties van Spark. Hoewel het nog te vroeg is om te zeggen hoeveel prestaties er uit Spark kunnen worden gehaald bij het analyseren van gegevens over donkere materie, Sehrish en Kowalkowski zien dat Spark gebruiksvriendelijke code kan leveren waarmee hoogenergetische fysica-onderzoekers een taak op honderdduizenden kernen kunnen lanceren. "Spark is in dat opzicht goed, " zegt Sehrish. "We hebben ook een goede schaling gezien - geen verspilling van computerbronnen omdat we de datasetgrootte en het aantal knooppunten vergroten."
Niemand weet of dit een haalbare aanpak zal zijn totdat de topprestaties van Spark voor deze toepassingen zijn bepaald. "De belangrijkste sleutel, "Kowalkowski zegt, "is dat we er nog niet van overtuigd zijn dat dit de technologie is om vooruit te gaan."
In feite, Spark zelf verandert. Het uitgebreide gebruik van open source zorgt voor een constante en snelle ontwikkelingscyclus. Dus Sehrish en Kowalkowski moeten hun code bijhouden met de nieuwe mogelijkheden van Spark.
"De constante groeicyclus met Spark zijn de kosten van het werken met geavanceerde technologie en iets met veel ontwikkelingsbelangen, ' zegt Sehrish.
Het kan een paar jaar duren voordat Sehrish en Kowalkowski een beslissing nemen over Spark. Het omzetten van software die is gemaakt voor high-throughput computing in goede krachtige computertools die gemakkelijk te gebruiken zijn, vereist fijnafstemming en teamwerk tussen experimentele en computationele wetenschappers. Of, je zou kunnen zeggen, er is meer nodig dan een schot in het donker.
 Palmolie decimerende dieren in het wild, oplossingen ongrijpbaar:rapport
Palmolie decimerende dieren in het wild, oplossingen ongrijpbaar:rapport- Onderzoekers vinden antibioticaresistente genen die veel voorkomen in grondwater
- Plastic in oceanen stapelt zich op, maar bewijs over schade is verrassend zwak
- Welke soorten schimmels groeien in de oceaan?
- Inheems vuurbeheer bevordert de wereldwijde biodiversiteit
Hoofdlijnen
- Meer dan 38 procent van de Neotropische papegaaienpopulatie op het Amerikaanse continent wordt bedreigd door menselijke activiteit
- De kans op gemengd fokken tussen twee zangvogelsoorten neemt af met warmere bronnen
- Een parasiet volgen die vissen verwoest
- UVB-straling beïnvloedt het gedrag van stekelbaarzen
- Herziening van historische voorraadroutes kan zeldzame stukken inheemse planten en dieren in gevaar brengen
- Neanderthalers hadden grotere hersenen dan moderne mensen - waarom zijn we slimmer?
- De vier eigenschappen van spiercellen
- Nieuwe inzichten in de belangrijkste oorzaak van een miskraam, geboorteafwijkingen ontdekt
- Wat zit er in je tarwe? Wetenschappers voegen het genoom van de meest voorkomende broodtarwe samen
- Snelheid berekenen op basis van kracht en afstand

- Nieuwe uitdaging voor eeuwenoude theorieën over Romeins glas

- Orkaan van donkere materie biedt kans om axions te detecteren

- ATLAS publiceert nieuwe resultaten in zoektocht naar zwak-interagerende supersymmetrische deeltjes
- Zonlichttrechter verzamelt licht uit alle richtingen

 Studie zet vraagtekens bij de perceptie van het Europees Parlement als voorvechter van gendergelijkheid
Studie zet vraagtekens bij de perceptie van het Europees Parlement als voorvechter van gendergelijkheid- Vernietigt donkere materie sneller in de Melkweg?
- De afvalverzamelende fietsers die de aandacht van de VN trokken
- Trends in orkaangedrag tonen sterker, langzamere en verder reikende stormen
- Wat gebeurt er tijdens de G1-fase?
- Wetenschappers gebruiken lipide-nanodeeltjes om genbewerking precies op de lever te richten
- Een slangenrobot die wordt bestuurd door biomimetische CPG's
- Chemische techniek is warp-drive voor het maken van betere synthetische moleculen voor medicijnen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
