Wetenschap
Hoe kunstmatige intelligentie haar beslissingen kan verklaren
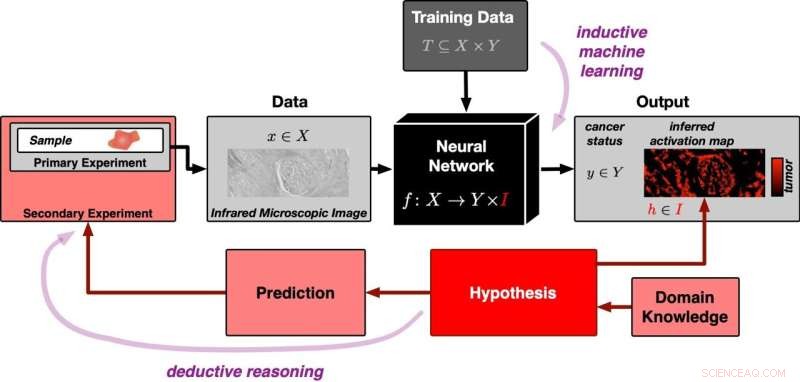
Een neuraal netwerk wordt in eerste instantie getraind met veel datasets om tumorbevattende van tumorvrije weefselbeelden te kunnen onderscheiden (invoer van bovenaf in het diagram). Het wordt vervolgens gepresenteerd met een nieuw weefselbeeld van een experiment (invoer van links). Via inductief redeneren genereert het neurale netwerk de classificatie "tumorbevattend" of "tumorvrij" voor het betreffende beeld. Tegelijkertijd creëert het een activatiekaart van het weefselbeeld. De activatiekaart is voortgekomen uit het inductieve leerproces en staat in eerste instantie los van de werkelijkheid. De correlatie wordt vastgesteld door de falsifieerbare hypothese dat gebieden met een hoge activatie exact overeenkomen met de tumorgebieden in het monster. Deze hypothese kan worden getest met verdere experimenten. Dit betekent dat de benadering deductieve logica volgt. Tegoed:PRODI
Kunstmatige intelligentie (AI) kan worden getraind om te herkennen of een weefselafbeelding een tumor bevat. Hoe het zijn beslissing precies neemt, is tot nu toe echter een mysterie gebleven. Een team van het Research Center for Protein Diagnostics (PRODI) van de Ruhr-Universität Bochum ontwikkelt een nieuwe aanpak die de beslissing van een AI transparant en dus betrouwbaar maakt. De onderzoekers onder leiding van professor Axel Mosig beschrijven de aanpak in het tijdschrift Medical Image Analysis .
Voor de studie werkte bio-informaticawetenschapper Axel Mosig samen met professor Andrea Tannapfel, hoofd van het Institute of Pathology, oncoloog professor Anke Reinacher-Schick van het Ruhr-Universität St. Josef Hospital, en biofysicus en PRODI-oprichter professor Klaus Gerwert. De groep ontwikkelde een neuraal netwerk, oftewel een AI, dat kan classificeren of een weefselmonster tumor bevat of niet. Daartoe voerden ze de AI een groot aantal microscopische weefselbeelden, waarvan sommige tumoren bevatten, terwijl andere tumorvrij waren.
"Neurale netwerken zijn in eerste instantie een black box:het is onduidelijk welke identificerende kenmerken een netwerk leert van de trainingsgegevens", legt Axel Mosig uit. In tegenstelling tot menselijke experts missen ze het vermogen om hun beslissingen uit te leggen. "Vooral voor medische toepassingen is het echter belangrijk dat de AI kan verklaren en dus betrouwbaar is", voegt bio-informaticus David Schuhmacher toe, die meewerkte aan het onderzoek.
AI is gebaseerd op falsifieerbare hypothesen
De verklaarbare AI van het Bochum-team is daarom gebaseerd op de enige betekenisvolle uitspraken die de wetenschap kent:op falsifieerbare hypothesen. Als een hypothese onjuist is, moet dit feit door een experiment worden aangetoond. Kunstmatige intelligentie volgt meestal het principe van inductief redeneren:met behulp van concrete observaties, d.w.z. de trainingsgegevens, creëert de AI een algemeen model op basis waarvan het alle verdere observaties evalueert.
Het onderliggende probleem werd 250 jaar geleden beschreven door filosoof David Hume en kan gemakkelijk worden geïllustreerd:hoeveel witte zwanen we ook waarnemen, we zouden uit deze gegevens nooit kunnen concluderen dat alle zwanen wit zijn en dat er helemaal geen zwarte zwanen bestaan. De wetenschap maakt daarom gebruik van zogenaamde deductieve logica. In deze benadering is een algemene hypothese het uitgangspunt. De hypothese dat alle zwanen wit zijn, wordt bijvoorbeeld vervalst wanneer een zwarte zwaan wordt gespot.
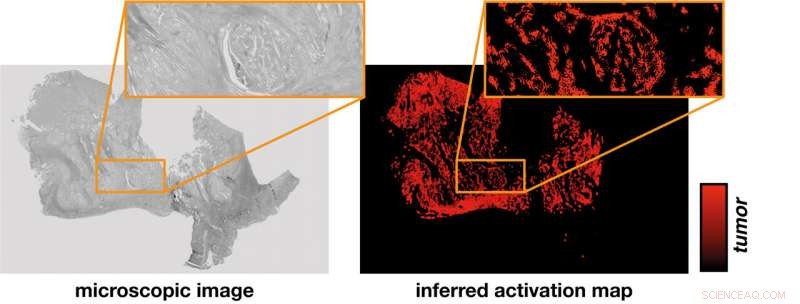
Het neurale netwerk leidt een activatiekaart (rechts) af van de microscopische opname van een weefselmonster (links). Een hypothese stelt de correlatie vast tussen de intensiteit van activering die uitsluitend door berekening werd bepaald en de identificatie van tumorgebieden die in experimenten kunnen worden geverifieerd. Tegoed:PRODI
Activeringskaart laat zien waar de tumor is gedetecteerd
"Op het eerste gezicht lijken inductieve AI en de deductieve wetenschappelijke methode bijna onverenigbaar", zegt Stephanie Schörner, een natuurkundige die eveneens aan het onderzoek heeft bijgedragen. Maar de onderzoekers vonden een manier. Hun nieuwe neurale netwerk geeft niet alleen een classificatie of een weefselmonster een tumor bevat of tumorvrij is, het genereert ook een activatiekaart van het microscopische weefselbeeld.
De activatiekaart is gebaseerd op een falsifieerbare hypothese, namelijk dat de activatie afgeleid van het neurale netwerk exact overeenkomt met de tumorgebieden in het monster. Plaatsspecifieke moleculaire methoden kunnen worden gebruikt om deze hypothese te testen.
"Dankzij de interdisciplinaire structuren bij PRODI hebben we de beste voorwaarden om de hypothesegebaseerde benadering in de toekomst te integreren in de ontwikkeling van betrouwbare biomarker AI, bijvoorbeeld om onderscheid te kunnen maken tussen bepaalde therapierelevante tumorsubtypes", besluit Axel. Mosig. + Verder verkennen
Kunstmatige intelligentie classificeert colorectale kanker met behulp van infraroodbeeldvorming
 Omkeerbare chemie maakt pad vrij voor veiligere batterijen
Omkeerbare chemie maakt pad vrij voor veiligere batterijen- Instrumenten voor het meten van temperatuur
- Ingenieurs gebruiken warmtevrije technologie voor flexibele elektronica, print metaal op bloemen, gelatine
- Chemie Nobel voor het gebruik van evolutie om nieuwe eiwitten te maken
- Waarom gaat elektriciteit naar de grond?
- Voedselverspilling kost velen niet smakelijk
- Extreme eco-tent getest op Antarctica
- Oude volkeren hebben het Amazone-regenwoud gevormd
- NASA vindt windschering die tropische cycloon Flamboyan . treft
- Model suggereert dat goed ontworpen subsidies boeren kunnen helpen en consumenten betere voedselkeuzes kunnen geven
Hoofdlijnen
- 5 manieren om optimistisch te blijven in een neergaande economie
- Evolutie:de begunstigden van massale uitsterving
- Wat gebeurt er met een cel als deze geen DNA-chromosomen kopieert voordat deze zich deelt?
- Hoe BRCA-genen werken
- Hoe zal de aarde er over 50 uitzien,
- CRISPR-octrooioorlogen benadrukken het probleem van het verlenen van brede intellectuele eigendomsrechten voor technologie die publieke voordelen biedt
- Wetenschappers ontdekken een genetisch mechanisme dat het opbrengstpotentieel van graangewassen zou kunnen verbeteren
- Zwemmers jeuk:wat veroorzaakt deze verwaarloosde door slakken overgedragen ziekte?
- Taxonomie (biologie): definitie, classificatie en voorbeelden
- Miljardair Bezos koopt landgoed voor $ 165 miljoen:rapport

- Amazon negeert aanvallen van Trump terwijl het een zakenimperium vormt

- Fox News benoemt veteraan executive Suzanne Scott als CEO

- Russisch begint berichten-app Telegram te blokkeren

- Idaho lab beschermt Amerikaanse infrastructuur tegen cyberaanvallen


 Save Lake Tsjaad bijeenkomst geopend in Nigeria
Save Lake Tsjaad bijeenkomst geopend in Nigeria- Hoe drukpotentiaal te berekenen
- Tesla wil raad van bestuur terugbrengen van 11 bestuurders naar 7
- Hoe champagne werkt
- Hongkong hitterecord september twee keer gebroken
- Gliale cellen (Glia): definitie, functie, typen
- Wetenschappers ontwikkelen nieuwe techniek voor het polijsten van oppervlakken op nanoschaal
- Hoe olietankers werken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
