Wetenschap
Robots trainen om objectplaatsingen te identificeren door hallucinerende scènes

Oier Mees laat zien hoe de nieuwe aanpak werkt. Krediet:Mees et al.
Nu meer robots hun weg vinden naar een aantal instellingen, onderzoekers proberen hun interacties met mensen zo soepel en natuurlijk mogelijk te maken. Robots trainen om direct te reageren op gesproken instructies, zoals "pak het glas, verplaats het naar rechts, " enzovoort., zou in veel situaties ideaal zijn, omdat het uiteindelijk meer directe en intuïtieve interacties tussen mens en robot mogelijk zou maken. Echter, dit is niet altijd gemakkelijk, omdat het vereist dat de robot de instructies van een gebruiker begrijpt, maar ook om te weten hoe objecten te verplaatsen in overeenstemming met specifieke ruimtelijke relaties.
Onderzoekers van de Universiteit van Freiburg in Duitsland hebben onlangs een nieuwe aanpak ontwikkeld om robots te leren hoe ze objecten moeten verplaatsen volgens de instructies van menselijke gebruikers. die werkt door "gehallucineerde" scènerepresentaties te classificeren. hun papier, voorgepubliceerd op arXiv, zal worden gepresenteerd op de IEEE International Conference on Robotics and Automation (ICRA) in Parijs, deze juni.
"In ons werk we concentreren ons op relationele instructies voor het plaatsen van objecten, zoals 'plaats de mok rechts van de doos' of 'zet het gele speeltje bovenop de doos, '" Oier Mees, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Om dat te doen, de robot moet nadenken over waar de mok moet worden geplaatst ten opzichte van de doos of een ander referentieobject om de ruimtelijke relatie te reproduceren die door een gebruiker wordt beschreven."
Het kan erg moeilijk zijn om robots te trainen om ruimtelijke relaties te begrijpen en objecten dienovereenkomstig te verplaatsen. omdat de instructies van een gebruiker doorgaans geen specifieke locatie afbakenen binnen een grotere scène die door de robot wordt waargenomen. Met andere woorden, als een menselijke gebruiker zegt "plaats de mok aan de linkerkant van het horloge, " hoe ver links van het horloge moet de robot de mok plaatsen en waar is de exacte grens tussen verschillende richtingen (bijv. Rechtsaf, links, voor je, achter, enzovoort.)?
"Vanwege deze inherente ambiguïteit, er is ook geen grondwaarheid of 'juiste' gegevens die kunnen worden gebruikt om ruimtelijke relaties te leren modelleren, Mees zei. "We pakken het probleem van de onbeschikbaarheid van grond-waarheid pixelgewijze annotaties van ruimtelijke relaties aan vanuit het perspectief van hulpleren."
Het belangrijkste idee achter de aanpak van Mees en zijn collega's is dat wanneer twee objecten worden gegeven en een afbeelding die de context weergeeft waarin ze worden gevonden, het is gemakkelijker om de ruimtelijke relatie daartussen te bepalen. Hierdoor kunnen de robots detecteren of het ene object zich links van het andere bevindt, daar bovenop, voor, enzovoort.
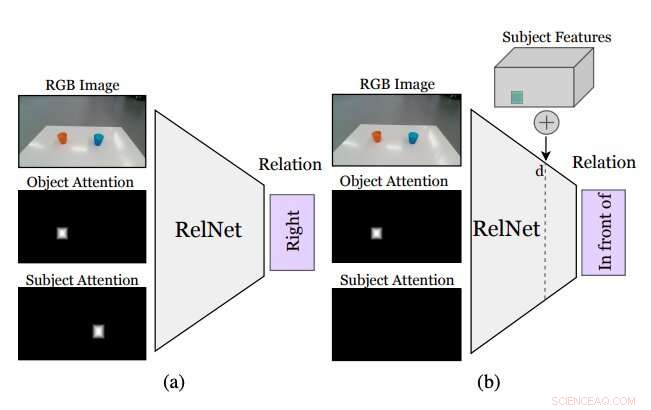
Figuur die samenvat hoe de door de onderzoekers bedachte aanpak werkt. Een hulp CNN, genaamd RelNet, is getraind om ruimtelijke relaties te voorspellen op basis van het invoerbeeld en twee aandachtsmaskers die verwijzen naar twee objecten die een relatie vormen. (a) na de opleiding, het netwerk kan worden 'bedrogen' om gehallucineerde scènes te classificeren door (b) hoogwaardige kenmerken van items op verschillende ruimtelijke locaties te implementeren. Krediet:Mees et al.
Hoewel het identificeren van een ruimtelijke relatie tussen twee objecten niet aangeeft waar de objecten moeten zijn om die relatie te reproduceren, door andere objecten in de scène in te voegen, kan de robot een verdeling over verschillende ruimtelijke relaties afleiden. Het toevoegen van deze niet-bestaande (d.w.z. gehallucineerde) objecten naar wat de robot ziet, moet hem in staat stellen te evalueren hoe de scène eruit zou zien als hij een bepaalde actie zou uitvoeren (d.w.z. het plaatsen van een van de objecten op een specifieke locatie op de tafel of het oppervlak ervoor).
"Meestal, Het realistisch 'plakken' van objecten in een afbeelding vereist ofwel toegang tot 3D-modellen en silhouetten of het zorgvuldig ontwerpen van de optimalisatieprocedure van generatieve adversariële netwerken (GAN's), "Zei Mees. "Bovendien, Het naïef "plakken" van objectmaskers in afbeeldingen creëert subtiele pixelartefacten die leiden tot merkbaar verschillende functies en tot de training die zich ten onrechte op deze discrepanties concentreert. We nemen een andere benadering en implanteren kenmerken van objecten op hoog niveau in kenmerkende kaarten van de scène die worden gegenereerd door een convolutioneel neuraal netwerk om scènerepresentaties te hallucineren, die vervolgens worden geclassificeerd als een hulptaak om het leersignaal te krijgen."
Voordat we een convolutioneel neuraal netwerk (CNN) trainen om ruimtelijke relaties te leren op basis van gehallucineerde objecten, de onderzoekers moesten ervoor zorgen dat het in staat was om relaties tussen individuele paren objecten te classificeren op basis van een enkel beeld. Vervolgens, ze "bedrogen" hun netwerk, genaamd RelNet, in het classificeren van "gehallucineerde" scènes door hoogwaardige kenmerken van items op verschillende ruimtelijke locaties te implanteren.
"Onze aanpak stelt een robot in staat om plaatsingsinstructies in natuurlijke taal te volgen die worden gegeven door menselijke gebruikers met minimale gegevensverzameling of heuristieken, Mees zei. "Iedereen zou graag een servicerobot in huis hebben die taken kan uitvoeren door instructies in natuurlijke taal te begrijpen. Dit is een eerste stap om een robot in staat te stellen de betekenis van veelgebruikte ruimtelijke voorzetsels beter te begrijpen."
De meeste bestaande methoden voor het trainen van robots om objecten te verplaatsen, gebruiken informatie met betrekking tot de objecten "3-D-vormen om paarsgewijze ruimtelijke relaties te modelleren. Een belangrijke beperking van deze technieken is dat ze vaak aanvullende technologische componenten vereisen, zoals volgsystemen die de bewegingen van verschillende objecten kunnen volgen. De aanpak van Mees en zijn collega's, anderzijds, vereist geen extra gereedschap, omdat het niet gebaseerd is op 3D-visietechnieken.
De onderzoekers evalueerden hun methode in een reeks experimenten met echte menselijke gebruikers en robots. De resultaten van deze tests waren veelbelovend, omdat hun methode robots in staat stelde om effectief de beste strategieën te identificeren om objecten op een tafel te plaatsen in overeenstemming met de ruimtelijke relaties die worden geschetst door de gesproken instructies van een menselijke gebruiker.
"Onze nieuwe benadering van hallucinerende scènerepresentaties kan ook meerdere toepassingen hebben in de robotica- en computervisiegemeenschappen, omdat robots vaak moeten kunnen inschatten hoe goed een toekomstige staat zou kunnen zijn om te redeneren over de acties die ze moeten ondernemen, Mees zei. "Het kan ook worden gebruikt om de prestaties van veel neurale netwerken te verbeteren, zoals objectdetectienetwerken, door gehallucineerde scènerepresentaties te gebruiken als een vorm van gegevensvergroting."
Mees en zijn collega's zijn we in staat om een set ruimtelijke voorzetsels in natuurlijke taal te modelleren (bijv. links, bovenop, etc.) betrouwbaar en zonder gebruik te maken van 3D vision-tools. In de toekomst, de benadering die in hun onderzoek wordt gepresenteerd, kan worden gebruikt om de mogelijkheden van bestaande robots te verbeteren, waardoor ze eenvoudige taken voor het verplaatsen van objecten effectiever kunnen uitvoeren terwijl ze de gesproken instructies van een menselijke gebruiker volgen.
In de tussentijd, hun paper zou de ontwikkeling van vergelijkbare technieken kunnen informeren om de interactie tussen mensen en robots tijdens andere objectmanipulatietaken te verbeteren. Indien gekoppeld aan ondersteunende leermethoden, de door Mees en zijn collega's ontwikkelde aanpak kan ook de kosten en inspanningen verminderen die gepaard gaan met het samenstellen van datasets voor robotica-onderzoek, omdat het de voorspelling van pixelgewijze waarschijnlijkheden mogelijk maakt zonder dat er grote geannoteerde datasets nodig zijn.
"We zijn van mening dat dit een veelbelovende eerste stap is om een gedeeld begrip tussen mensen en robots mogelijk te maken, Mees concludeerde. "In de toekomst, we willen onze aanpak uitbreiden om een begrip van verwijzende uitdrukkingen op te nemen, om een pick-and-place-systeem te ontwikkelen dat de instructies in natuurlijke taal volgt."
© 2020 Wetenschap X Netwerk
 Broze scheurgedrag begrijpen om sterkere materialen te ontwerpen
Broze scheurgedrag begrijpen om sterkere materialen te ontwerpen- Legeronderzoek kijkt naar parels voor aanwijzingen voor het verbeteren van lichtgewicht bepantsering voor soldaten
- De oorzaak van capaciteitsverlies vinden in een metaaloxide batterijmateriaal
- Structurele en dynamische verschillen tussen selectieve en niet-selectieve ionkanalen
- 3D-experimenten werpen nieuw licht op legeringen met vormgeheugen
- Van permafrostmicroben tot overlevende zangvogels, onderzoeksprojecten zijn ook slachtoffer van pandemie
- Wat zijn de vijf biotische factoren van een aquatisch ecosysteem?
- NASA kijkt naar de regenval van tropische cycloon Funanis
- Storm verlaat Californië met de helft van de gebruikelijke sneeuw voor een jaar
- Koolstofvoetafdrukken zijn moeilijk te begrijpen - dit is wat u moet weten
Hoofdlijnen
- Zelfverdediging voor planten
- Een nieuwe strategie die door Helicobacter pylori wordt gebruikt om mitochondriën aan te pakken
- Staan we aan het begin van het einde van de westerse beschaving?
- Inspanningen om zeeschildpadden te redden zijn een wereldwijd succesverhaal op het gebied van natuurbehoud:wetenschappers
- Wetenschappers presenteren een nieuwe methode om elk eiwit in elk soort cel direct en snel te vernietigen
- Voorbeelden van genetische diversiteit
- Zelfs wilde zoogdieren hebben regionale dialecten
- Animatie ontmoet biologie - werpt nieuw licht op het gedrag van dieren
- Duiven kunnen zowel ruimte als tijd onderscheiden
- Computers helpen de gaten tussen videoframes op te vullen

- Apple verontschuldigt zich en geeft bugfix voor veel langzamer dan MacBook Pro's zou moeten zijn

- CEO's in de gezondheidszorg lopen voorop in beloning
- China voert bedreiging op om VS zeldzame aardmetalen te ontnemen

- Amerikaanse rechtbank behandelt minachtingzaak tegen Teslas Musk


 Natste zomer in vijf jaar, maar komt er een einde aan La Nina?
Natste zomer in vijf jaar, maar komt er een einde aan La Nina?- Grafeen verbetert veel materialen, maar laat ze bevochtigbaar
- Ongrijpbaar 19e-eeuws fort in Alaska, gelokaliseerd met behulp van radartechnologie
- Ruimte tuinieren
- Langzame aardbevingen in Cascadia zijn voorspelbaar
- Uitgelijnde koolstof nanobuis / grafeen sandwiches
- Hoe het complement van een hoek te vinden
- E-bike gemopper echo in de Beierse Alpen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Norway | Italian | Danish |

-
Wetenschap © https://nl.scienceaq.com
