Wetenschap
Computerwetenschappers ontwerpen een tool om de bron van fouten te identificeren die worden veroorzaakt door software-updates
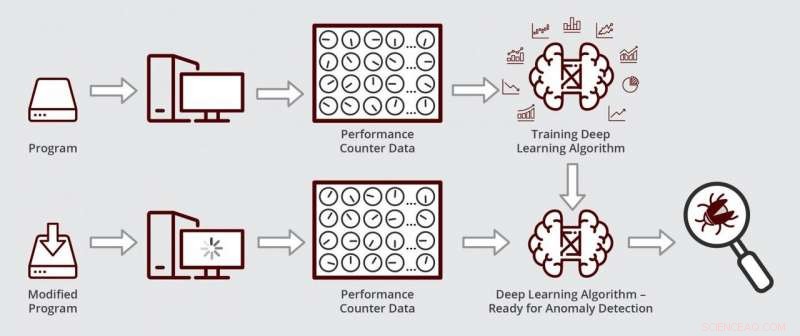
Schematische weergave van hoe het deep learning-algoritme van Muzahid werkt. Het algoritme is klaar voor anomaliedetectie nadat het eerst is getraind op prestatietellergegevens van een bugvrije versie van een programma. Krediet:Texas A&M Engineering
We hebben allemaal de frustratie gedeeld:software-updates die bedoeld zijn om onze applicaties sneller te laten werken, doen uiteindelijk precies het tegenovergestelde. Deze fouten, in de informatica genoemd als prestatieregressies, zijn tijdrovend om te herstellen, aangezien het lokaliseren van softwarefouten normaal gesproken substantiële menselijke tussenkomst vereist.
Om dit obstakel te overwinnen, onderzoekers van de Texas A&M University, in samenwerking met computerwetenschappers van Intel Labs, hebben nu een volledig geautomatiseerde manier ontwikkeld om de bron van fouten veroorzaakt door software-updates te identificeren. Hun algoritme, gebaseerd op een gespecialiseerde vorm van machine learning, deep learning genaamd, is niet alleen kant-en-klaar, maar ook snel het vinden van prestatiefouten in een kwestie van een paar uur in plaats van dagen.
"Het updaten van software kan je soms tegenstaan als er fouten binnensluipen en vertragingen veroorzaken. Dit probleem is nog groter voor bedrijven die grootschalige softwaresystemen gebruiken die voortdurend evolueren, " zei Dr. Abdullah Muzahid, assistent-professor bij de afdeling Computer Science and Engineering. "We hebben een handige tool ontworpen voor het diagnosticeren van prestatieregressies die compatibel is met een hele reeks software- en programmeertalen, het uitbreiden van het nut enorm."
De onderzoekers beschreven hun bevindingen in de 32e editie van Advances in Neural Information Processing Systems van de werkzaamheden van de Neural Information Processing Systems-conferentie in december.
Om de bron van fouten in software aan te wijzen, debuggers controleren vaak de status van prestatiemeteritems binnen de centrale verwerkingseenheid. Deze tellers zijn regels code die controleren hoe het programma wordt uitgevoerd op de hardware van de computer in het geheugen, bijvoorbeeld. Dus, wanneer de software draait, tellers houden bij hoe vaak het bepaalde geheugenlocaties benadert, de tijd dat het daar blijft en wanneer het weggaat, onder andere. Vandaar, wanneer het gedrag van de software misgaat, tellers worden weer gebruikt voor diagnostiek.
"Prestatietellers geven een idee van de uitvoeringsstatus van het programma, "zei Muzahid. "Dus, als een programma niet werkt zoals het hoort, deze tellers hebben meestal het veelbetekenende teken van abnormaal gedrag."
Echter, nieuwere desktops en servers hebben honderden prestatiemeters, waardoor het vrijwel onmogelijk is om al hun statussen handmatig bij te houden en vervolgens te zoeken naar afwijkende patronen die wijzen op een prestatiefout. Dat is waar de machine learning van Muzahid om de hoek komt kijken.
Door gebruik te maken van deep learning, de onderzoekers waren in staat om gegevens afkomstig van een groot aantal tellers tegelijkertijd te controleren door de gegevens te verkleinen, wat vergelijkbaar is met het comprimeren van een afbeelding met hoge resolutie tot een fractie van de oorspronkelijke grootte door het formaat te wijzigen. In de lagere dimensionale gegevens, hun algoritme zou dan patronen kunnen zoeken die afwijken van normaal.
Toen hun algoritme klaar was, de onderzoekers testten of het een prestatiefout kon vinden en diagnosticeren in commercieel beschikbare software voor gegevensbeheer die door bedrijven wordt gebruikt om hun cijfers en cijfers bij te houden. Eerst, ze hebben hun algoritme getraind om normale tellergegevens te herkennen door een oudere, glitch-free versie van de data management software. Volgende, ze hebben hun algoritme uitgevoerd op een bijgewerkte versie van de software met de prestatieregressie. Ze ontdekten dat hun algoritme de bug binnen een paar uur had gevonden en gediagnosticeerd. Muzahid zei dat dit type analyse een aanzienlijke hoeveelheid tijd kan kosten als het handmatig wordt gedaan.
Naast het diagnosticeren van prestatieregressies in software, Muzahid merkte op dat hun deep learning-algoritme ook potentieel kan worden gebruikt in andere onderzoeksgebieden, zoals het ontwikkelen van de technologie die nodig is voor autonoom rijden.
"Het basisidee is weer hetzelfde, dat is in staat zijn om een afwijkend patroon te detecteren, " zei Muzahid. "Zelfrijdende auto's moeten kunnen detecteren of er een auto of een mens voor staat en daarnaar handelen. Dus, het is opnieuw een vorm van anomaliedetectie en het goede nieuws is dat ons algoritme daar al voor is ontworpen."
Andere bijdragen aan het onderzoek zijn onder meer Dr. Mejbah Alam, Dr. Justin Gottschlich, Dr. Nesime Tatbul, Dr. Javier Turek en Dr. Timothy Mattson van Intel Labs.
 Onderzoekers ontdekken dat traditionele waarnemingen van vloeistofstromen het grote geheel kunnen missen
Onderzoekers ontdekken dat traditionele waarnemingen van vloeistofstromen het grote geheel kunnen missen- COVID-19-antilichaamtesten:hoe betrouwbaar zijn ze?
- Onderzoekers maken theoretische voorspelling van 2-D halfgeleider tindioxide
- Lijst van recycleerbare aluminium blikjes
- Organische afstandhouders verbeteren de LED-prestaties
- Mauna Loa Feiten voor kinderen
- Kunnen nieuwe technologieën Europa helpen om insecten te proeven?
- Indonesië zegt kust nabij vulkaan te vermijden, bang voor nieuwe tsunami
- Wat heeft de kern van de aarde gemeen met saladedressing? Misschien dit
- Internationaal internationaal onderzoek onderzoekt het vermogen van riffen om te herstellen van abrupte veranderingen in het milieu gedurende millennia
Hoofdlijnen
- Hoe kan een mutatie in DNA invloed hebben op eiwitsynthese?
- Vissen en schepen:het scheepvaartverkeer verkleint het communicatiebereik voor Atlantische kabeljauw, Schelvis
- Great Basin zaadstudie-experiment richt zich op herstel van weidegronden
- Nieuwe Peruaanse vogelsoorten ontdekt door zijn gezang
- Wat zit er in je tarwe? Wetenschappers voegen het genoom van de meest voorkomende broodtarwe samen
- Wat is vergelijkende biochemie?
Vergelijkende biochemie kan een vaag begrip zijn met meerdere betekenissen, alhoewel het boeiende interacties tussen organismen en hun biologieën kan onthullen. Op zijn minst noemen wetenschappers het een interdiscip
- Drie mechanismen van genetische recombinatie in prokaryoten
- Zangvogelpopulaties kunnen wijzen op problemen in noordwestelijke bossen
- Het gebruik van kwallenbloei als oplossing voor het maken van nieuwe producten
- Voor Trump, de lange geschiedenis van nepnieuws

- Facebook lanceert een nieuwssectie - en zal uitgevers betalen

- Nestle betaalt $ 7,15 miljard om Starbucks-producten te verkopen

- Musk vertelt krant dat hij barst onder de stress van Tesla-baan

- Drie vrouwen zijn het brein achter de persoonlijkheid van Google Assistenten


 Maatschappelijke kosten van koolstof:wat is het, en waarom moeten we het berekenen?
Maatschappelijke kosten van koolstof:wat is het, en waarom moeten we het berekenen?- Wat organisaties verkeerd doen over onderbrekingen op het werk
- NASA-NOAA's Suomi NPP Satellite krijgt twee blikken op orkaan Maria
- In Californië, gigantische Stratolaunch-jet vliegt voor de eerste keer
- Optisch actieve defecten verbeteren koolstofnanobuisjes
- Identificatie van ratelslangen
- De noemer rationaliseren
- Nucleaire technieken ontsluiten de structuur van een zeldzaam type supergeleidende intermetallische legering
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
