Wetenschap
Een methode voor zelfgestuurd robotleren waarbij haalbare doelen worden gesteld

De robot verzamelt willekeurige interactiegegevens om te gebruiken voor het trainen van een representatie en als off-policy data voor RL. Krediet:Nair et al.
Reinforcement learning (RL) is tot nu toe een effectieve techniek gebleken voor het trainen van kunstmatige agenten op individuele taken. Echter, als het gaat om het trainen van multifunctionele robots, die in staat moet zijn om een verscheidenheid aan taken uit te voeren die verschillende vaardigheden vereisen, de meeste bestaande RL-benaderingen zijn verre van ideaal.
Met dit in gedachten, een team van onderzoekers van UC Berkeley heeft onlangs een nieuwe RL-aanpak ontwikkeld die kan worden gebruikt om robots te leren hun gedrag aan te passen op basis van de taak die ze krijgen. Deze aanpak, geschetst in een paper dat vooraf is gepubliceerd op arXiv en gepresenteerd op de conferentie over robotleren van dit jaar, stelt robots in staat om automatisch met gedrag te komen en dit in de loop van de tijd te oefenen, leren welke in een bepaalde omgeving kunnen worden uitgevoerd. De robots kunnen de opgedane kennis vervolgens hergebruiken en toepassen op nieuwe taken die menselijke gebruikers hen vragen te voltooien.
"We zijn ervan overtuigd dat gegevens essentieel zijn voor robotmanipulatie en om voldoende gegevens te verkrijgen om manipulatie op een algemene manier op te lossen, robots zullen zelf data moeten verzamelen, "Ashvin Nair, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Dit is wat we zelfgestuurd robotleren noemen:een robot die actief coherente verkenningsgegevens kan verzamelen en zelf kan begrijpen of hij al dan niet is geslaagd in taken om nieuwe vaardigheden te leren."
De nieuwe aanpak die door Nair en zijn collega's is ontwikkeld, is gebaseerd op een doelgericht RL-raamwerk dat in hun eerdere werk werd gepresenteerd. In dit eerdere onderzoek de onderzoekers introduceerden het stellen van doelen in een latente ruimte als een techniek om robots te trainen in vaardigheden zoals het duwen van objecten of het openen van deuren rechtstreeks vanuit pixels, zonder de noodzaak van een externe beloningsfunctie of schatting van de staat.
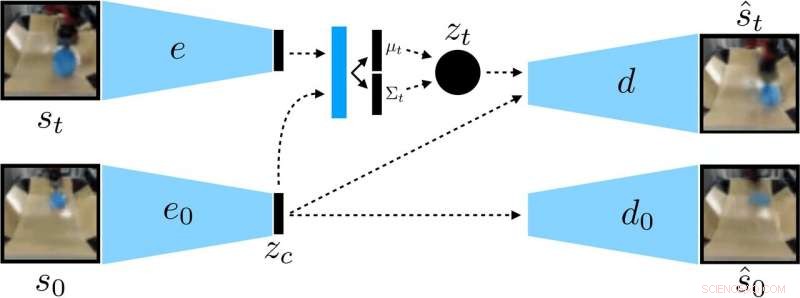
De onderzoekers trainden een context-geconditioneerde VAE op de data, die context ontwart die constant blijft tijdens een uitrol. Krediet:Nair et al.
"In ons nieuwe werk we richten ons op generalisatie:hoe kunnen we zelf-gesuperviseerd leren om niet alleen een enkele vaardigheid te leren, maar ook in staat zijn om te generaliseren naar visuele diversiteit tijdens het uitvoeren van die vaardigheid? "Zei Nair. "Wij geloven dat het vermogen om te generaliseren naar nieuwe situaties de sleutel zal zijn voor betere robotmanipulatie."
In plaats van een robot individueel op veel vaardigheden te trainen, het door Nair en zijn collega's voorgestelde voorwaardelijke doelenmodel is ontworpen om specifieke doelen te stellen die haalbaar zijn voor de robot en zijn afgestemd op de huidige staat. Eigenlijk, het algoritme dat ze ontwikkelden leert een specifiek type representatie dat dingen scheidt die de robot kan besturen van de dingen die hij niet kan besturen.
Bij het gebruik van hun zelf-gesuperviseerde leermethode, de robot verzamelt in eerste instantie gegevens (d.w.z. een reeks afbeeldingen en acties) door willekeurig te interageren met zijn omgeving. Vervolgens, het traint een gecomprimeerde representatie van deze gegevens die afbeeldingen omzet in laagdimensionale vectoren die impliciet informatie bevatten zoals de positie van objecten. In plaats van expliciet verteld te worden wat te leren, deze representatie begrijpt automatisch concepten via zijn compressiedoelstelling.
"Met behulp van de geleerde representatie, de robot oefent om verschillende doelen te bereiken en traint een beleid met behulp van versterkend leren, " legde Nair uit. "De gecomprimeerde weergave is de sleutel voor deze oefenfase:het wordt gebruikt om te meten hoe dicht twee afbeeldingen zijn, zodat de robot weet wanneer het is gelukt of mislukt, en het wordt gebruikt om doelen voor de robot te oefenen. Op testtijd, het kan dan overeenkomen met een door een mens gespecificeerd doelbeeld door het aangeleerde beleid uit te voeren."
De onderzoekers evalueerden de effectiviteit van hun aanpak in een reeks experimenten waarin een kunstmatige agent voorheen onzichtbare objecten manipuleerde in een omgeving die was gemaakt met behulp van het MuJuCo-simulatieplatform. interessant, Dankzij hun trainingsmethode kon de robotagent automatisch vaardigheden verwerven die hij vervolgens in nieuwe situaties kon toepassen. Specifieker, de robot was in staat om een verscheidenheid aan objecten te manipuleren, het generaliseren van manipulatiestrategieën die het eerder had verworven naar nieuwe objecten die het tijdens de training niet was tegengekomen.
"We zijn het meest enthousiast over twee resultaten van dit werk, ' zei Nair. 'Eerst, we ontdekten dat we een beleid kunnen trainen om objecten in de echte wereld op ongeveer 20 objecten te duwen, maar het geleerde beleid kan ook andere objecten pushen. Dit type generalisatie is de belangrijkste belofte van methoden voor diep leren, en we hopen dat dit het begin is van veel indrukwekkendere vormen van generalisatie die zullen volgen."
Opmerkelijk, in hun experimenten, Nair en zijn collega's waren in staat om een beleid te trainen vanuit een vaste dataset van interacties zonder een grote hoeveelheid data online te hoeven verzamelen. Dit is een belangrijke prestatie, aangezien het verzamelen van gegevens voor robotica-onderzoek over het algemeen erg duur is, en het kunnen leren van vaardigheden uit vaste datasets maakt hun aanpak veel praktischer.
In de toekomst, het door de onderzoekers ontwikkelde model voor zelf-gesuperviseerd leren zou kunnen helpen bij de ontwikkeling van robots die een grotere verscheidenheid aan taken kunnen aanpakken zonder individueel op een groot aantal vaardigheden te hoeven trainen. Ondertussen, Nair en zijn collega's zijn van plan om hun aanpak te blijven testen in gesimuleerde omgevingen, terwijl ook wordt onderzocht hoe deze verder kan worden verbeterd.
"We zijn nu bezig met een paar verschillende onderzoekslijnen, inclusief het oplossen van taken met een veel grotere hoeveelheid visuele diversiteit, evenals het gelijktijdig oplossen van een groot aantal taken en kijken of we de oplossing voor de ene taak kunnen gebruiken om het oplossen van de volgende taak te versnellen, ' zei Nair.
© 2019 Wetenschap X Netwerk
 Wetenschappers ontdekken fijne kneepjes van serotoninereceptor die cruciaal zijn voor betere therapieën
Wetenschappers ontdekken fijne kneepjes van serotoninereceptor die cruciaal zijn voor betere therapieën- Zelfherstellende vloeistof brengt nieuw leven in batterijalternatief
- Een op rhodium gebaseerde katalysator voor het maken van organosilicium met minder edelmetaal
- Wetenschappers observeren de rol van cavitatie bij het breken van glas
- Hoge thermo-elektrische prestaties in goedkope SnS0.91Se0.09-kristallen
Hoofdlijnen
- Kun je later in je leven ambidexter worden? Het hangt er van af
- Nieuwe studie verandert kijk op vliegende insecten
- The Differences in Fraternal & Paternal Twins
- Binaire splijting: definitie & proces
- Is er een psychologische reden waarom mensen gemeen zijn op internet?
- Poema's zijn socialer dan eerder werd gedacht
- Alles wat je nooit wilde weten over bedwantsen, en meer
- Welk proces voeren Ribosomes uit?
- De primaire primaire productiviteit berekenen
- SoftBank, Saoedi-Arabië kondigt grootschalig zonne-energieproject aan

- Vragen over privacy bij het beoordelen van gebruikersaudio op Facebook

- Baanbrekende turbine zet nieuwe maatstaf voor hernieuwbare getijdenenergie

- China stelt financiële sector open voor meer buitenlandse investeringen

- Lineair vergelijkingssysteem herstelt verminderde handbeweging

 Wetenschappers zien hoe diamant verandert in grafiet
Wetenschappers zien hoe diamant verandert in grafiet- Onderzoekers herberekenen efficiëntieparadigma voor dunnefilmzonnepanelen
- Stresstest:uit nieuwe studie blijkt dat zeehonden gestrest zijn door haaien
- Green Propellant Infusion Mission-ruimtevaartuig om groene stuwstof in een baan om de aarde te testen
- Beresheet:Eerste particulier gefinancierde missie stort neer op de maan, maar de betekenis ervan is enorm
- Ex-Googler op zoek naar kantoor dringt aan op regulering van technologiebedrijf
- Onderzoekers observeren moiré-trions in H-gestapelde overgangsmetaal dichalcogenide dubbellagen
- VS blijft achter bij 79 andere landen bij het voorkomen van detentie van immigratie van kinderen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
