Wetenschap
Slechts een paar honderd trainingsvoorbeelden brengen menselijk klinkende spraak in Microsoft TTS feat
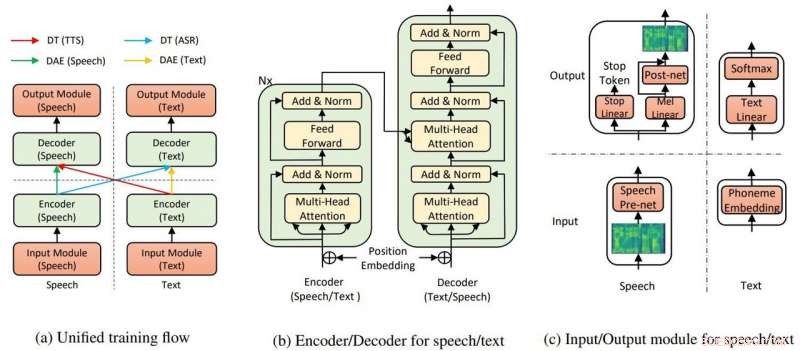
De algemene modelstructuur voor TTS en ASR. Krediet:Yi Ren, Xu Tan et al.
Microsoft Research Asia krijgt applaus voor het omzetten van tekst naar spraak waarvoor weinig training nodig is - en het laat "ongelooflijk" realistische resultaten zien.
Kyle Wiggers binnen VentureBeat zei dat tekst-naar-spraak-algoritmen niet nieuw waren en andere heel capabel, maar, nog altijd, de teaminspanning bij Microsoft heeft nog steeds een voorsprong.
Abdullah Matloob Digitale informatiewereld :"Tekst-naar-spraak-conversie wordt steeds slimmer, maar het nadeel is dat het nog steeds een buitensporige hoeveelheid trainingstijd en middelen zal vergen om een natuurlijk klinkend product te bouwen."
Op zoek naar een manier om de last van trainingstijd en middelen van je af te schudden om een natuurlijk klinkende output te creëren, Microsoft Research en Chinese onderzoekers hebben een andere manier ontdekt om tekst naar spraak om te zetten.
Fabienne Lang in Interessante techniek :Hun antwoord blijkt een AI-tekst-naar-spraak te zijn met 200 stemvoorbeelden (slechts 200) om realistisch klinkende spraak te creëren die overeenkomt met transcripties. Lang zei, "Dit betekent ongeveer 20 minuten."
Dat de vereiste slechts 200 audioclips en bijbehorende transcripties was, maakte indruk op Wiggers VentureBeat . Hij merkte ook op dat de onderzoekers een AI-systeem bedachten "dat gebruikmaakt van niet-gesuperviseerd leren - een tak van machine learning die kennis verkrijgt van niet-gelabelde, niet geclassificeerd, en ongecategoriseerde testgegevens."
Hun krant staat op arXiv. "Bijna onbewaakte tekst naar spraak en automatische spraakherkenning" is door Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie Yan Liu. Auteur affiliaties zijn Zhejiang University, Microsoft Research en Microsoft Search Technology Center (STC) Azië.
In hun krant het team zei dat de TTS AI twee belangrijke componenten gebruikt, een transformator en ruisonderdrukkende auto-encoder, om het allemaal te laten werken.
"Door de transformatoren, De tekst-naar-spraak-AI van Microsoft kon spraak of tekst herkennen als invoer of uitvoer, " zei een artikel in Gedurfd door Rechelle Fuertes.
Tyler Lee in Ubergizmo gaf een definitie van transformator:"Transformers ... zijn diepe neurale netwerken die zijn ontworpen om de neuronen in onze hersenen na te bootsen ..."
MathWorks had een definitie voor autoencoder. "Een autoencoder is een soort kunstmatig neuraal netwerk dat wordt gebruikt om op een niet-gecontroleerde manier efficiënte gegevens (coderingen) te leren. Het doel van een auto-encoder is om een representatie (codering) voor een reeks gegevens te leren, denoising autoencoders is typisch een type autoencoders dat is getraind om 'ruis' in beschadigde invoersamples te negeren."
Hebben de resultaten van hun experiment aangetoond dat hun idee het najagen waard is? "Onze methode haalt 99,84% in termen van verstaanbaarheid op woordniveau en 2,68 MOS voor TTS, en 11,7% PER voor ASR [automatische spraakherkenning] op LJSpeech-dataset, door gebruik te maken van slechts 200 gepaarde spraak- en tekstgegevens (ongeveer 20 minuten audio), samen met extra ongepaarde spraak- en tekstgegevens."
Waarom dit belangrijk is:deze benadering kan tekst-naar-spraak toegankelijker maken, aldus rapporten.
"Onderzoekers werken continu aan verbetering van het systeem, en hopen dat in de toekomst, het zal nog minder werk vergen om een levensecht discours te genereren, " zei Lang.
De paper zal worden gepresenteerd op de International Conference on Machine Learning, in Long Beach, Californië later dit jaar, en het team is van plan de code in de komende weken vrij te geven, zei Wiggers.
In de tussentijd, de onderzoekers lopen nog niet weg van hun werk in het presenteren van transformaties met weinig gepaarde gegevens.
"In dit werk, we hebben de bijna onbewaakte methode voor tekst-naar-spraak en automatische spraakherkenning voorgesteld, die slechts weinig gepaarde spraak- en tekstgegevens en extra ongepaarde gegevens gebruikt... Voor toekomstig werk, we zullen de limiet van ongecontroleerd leren bereiken door puur gebruik te maken van ongepaarde spraak- en tekstgegevens, met behulp van andere pre-trainingsmethoden."
© 2019 Wetenschap X Netwerk
 Zwitsers stemmen over klimaatdoelen in grondwet
Zwitsers stemmen over klimaatdoelen in grondwet- Verminderde afvoer van sneeuwsmelt in Sierra Nevada om de landbouw in Californië te bedreigen
- Biosphere 2 regenwoud gesloten tijdens droogte-experiment
- Klimaatverandering en verwaarlozing bedreigen Senegals Saint Louis
- Naties onder druk gezet om urgente bedreigingen aan te pakken tijdens VN-klimaatbesprekingen
Hoofdlijnen
- Wat is de structuur van stamcellen?
- Super Invader Tree treft Zuid, maar de vlooienkever kan een held zijn
- Hoe slaaplabs werken
- Trucs voor het onthouden van dierenfylum
- Wat is de meest logische volgorde van stappen voor het splitsen van vreemd DNA?
- Horror als Noorse goederentreinen meer dan 100 rendieren neermaaien
- Nieuwe genen op verslechterend Y-chromosoom
- Haaien langer in de tand dan we dachten
- Bij-nabootsende kaalvleugelmot zoemt na 130 jaar weer tot leven
- EU kondigt strikte 5G-regels aan maar geen Huawei-verbod

- Xerox nomineert 11 om HP-kaart te vervangen

- Activiteitensimulator kan robots taken leren, zoals koffie zetten of de tafel dekken

- Bedrijf uit Seattle gebruikt kunstmatige intelligentie om pizza te maken

- Waarom voertuigen zonder bestuurder geen ongecontroleerde toegang tot onze steden mogen krijgen


 NASA identificeert waarschijnlijke locaties van de diepe geheimen van de vroege gesmolten manen
NASA identificeert waarschijnlijke locaties van de diepe geheimen van de vroege gesmolten manen- Wat is een groep atomen die zich verenigen en die als één eenheid werken?
- Gelijkaardige richels op Mars hebben verschillende oorsprongen
- Nieuwe lijm en thermisch stabiele epoxyharsen
- NASA-test van mega-maanraketmotoren afgebroken
- Negen dingen waar je van houdt die worden verwoest door klimaatverandering
- Hoe wiskundige hulpmiddelen met vermenigvuldiging te maken met behulp van ijslollystokjes
- Hoe levende machines te zien
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Swedish | German | Dutch | Danish | Norway | Portuguese |

-
Wetenschap © https://nl.scienceaq.com
