Wetenschap
Handschoen vol sensoren leert handtekeningen van de menselijke greep

MIT-onderzoekers hebben een goedkope, handschoen vol sensoren die druksignalen opvangt wanneer mensen met objecten omgaan. De handschoen kan worden gebruikt om tactiele datasets met hoge resolutie te creëren die robots kunnen gebruiken om beter te identificeren, wegen, en objecten manipuleren. Krediet:Massachusetts Institute of Technology
Het dragen van een handschoen vol sensoren bij het hanteren van een verscheidenheid aan objecten, MIT-onderzoekers hebben een enorme dataset samengesteld waarmee een AI-systeem objecten kan herkennen door alleen aanraking. De informatie kan worden gebruikt om robots te helpen objecten te identificeren en te manipuleren, en kan helpen bij het ontwerpen van protheses.
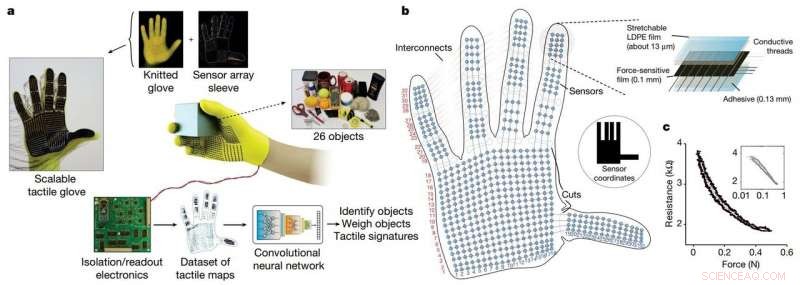
De onderzoekers ontwikkelden een goedkope gebreide handschoen, genaamd "schaalbare tactiele handschoen" (STAG), uitgerust met ongeveer 550 kleine sensoren over bijna de hele hand. Elke sensor vangt druksignalen op wanneer mensen op verschillende manieren met objecten omgaan. Een neuraal netwerk verwerkt de signalen om een dataset van druksignaalpatronen met betrekking tot specifieke objecten te "leren". Vervolgens, het systeem gebruikt die dataset om de objecten te classificeren en hun gewicht te voorspellen door alleen te voelen, zonder dat er visuele input nodig is.
In een paper gepubliceerd in Natuur , de onderzoekers beschrijven een dataset die ze met STAG hebben samengesteld voor 26 veelvoorkomende objecten, waaronder een blikje frisdrank, schaar, Tennisbal, lepel, pen, en mok. Met behulp van de dataset, het systeem voorspelde de identiteit van de objecten met een nauwkeurigheid tot 76 procent. Het systeem kan ook de juiste gewichten van de meeste objecten binnen ongeveer 60 gram voorspellen.
Vergelijkbare op sensoren gebaseerde handschoenen die tegenwoordig worden gebruikt, kosten duizenden dollars en bevatten vaak slechts ongeveer 50 sensoren die minder informatie vastleggen. Hoewel STAG gegevens met een zeer hoge resolutie produceert, het is gemaakt van in de handel verkrijgbare materialen voor in totaal ongeveer $ 10.
Het tactiele detectiesysteem kan worden gebruikt in combinatie met traditionele computervisie en op afbeeldingen gebaseerde datasets om robots een meer mensachtig begrip te geven van interactie met objecten.
"Mensen kunnen objecten goed identificeren en hanteren omdat we tactiele feedback hebben. Als we objecten aanraken, we voelen om ons heen en beseffen wat ze zijn. Robots hebben niet die rijke feedback, " zegt Subramanian Sundaram Ph.D. '18, een voormalig afgestudeerde student in het Computer Science and Artificial Intelligence Laboratory (CSAIL). "We hebben altijd gewild dat robots zouden doen wat mensen kunnen, zoals het doen van de afwas of andere klusjes. Als je wilt dat robots deze dingen doen, ze moeten objecten heel goed kunnen manipuleren."
De onderzoekers gebruikten de dataset ook om de samenwerking tussen regio's van de hand tijdens objectinteracties te meten. Bijvoorbeeld, wanneer iemand het middelste gewricht van zijn wijsvinger gebruikt, ze gebruiken zelden hun duim. Maar de toppen van de wijs- en middelvinger komen altijd overeen met het duimgebruik. "We laten meetbaar zien, Voor de eerste keer, Dat, als ik een deel van mijn hand gebruik, hoe groot de kans is dat ik een ander deel van mijn hand gebruik, " hij zegt.
Prothetische fabrikanten kunnen informatie mogelijk gebruiken om, zeggen, kies optimale plekken voor het plaatsen van druksensoren en help protheses aan te passen aan de taken en objecten waarmee mensen regelmatig omgaan.
Deelnemen aan Sundaram op het papier zijn:CSAIL-postdocs Petr Kellnhofer en Jun-Yan Zhu; CSAIL afgestudeerde student Yunzhu Li; Antonio Torralba, een professor in EECS en directeur van het MIT-IBM Watson AI Lab; en Wojciech Matusik, een universitair hoofddocent in elektrotechniek en informatica en hoofd van de Computational Fabrication-groep.
De STAG als platform om te leren van de menselijke greep. Credit: Natuur (2019). DOI:10.1038/s41586-019-1234-z
STAG is gelamineerd met een elektrisch geleidend polymeer dat de weerstand tegen uitgeoefende druk verandert. De onderzoekers naaiden geleidende draden door gaten in de geleidende polymeerfilm, van de vingertoppen tot aan de basis van de handpalm. De draden overlappen elkaar op een manier die ze in druksensoren verandert. Wanneer iemand die de handschoen draagt voelt, liften, houdt, en laat een voorwerp vallen, de sensoren registreren de druk op elk punt.
De draden verbinden van de handschoen met een extern circuit dat de drukgegevens vertaalt in "tactiele kaarten, " wat in wezen korte video's zijn van stippen die groeien en krimpen over een afbeelding van een hand. De stippen vertegenwoordigen de locatie van drukpunten, en hun grootte vertegenwoordigt de kracht - hoe groter de stip, hoe groter de druk.
Van die kaarten de onderzoekers verzamelden een dataset van ongeveer 135, 000 videoframes van interacties met 26 objecten. Die frames kunnen door een neuraal netwerk worden gebruikt om de identiteit en het gewicht van objecten te voorspellen, en inzichten verschaffen over de menselijke greep.
Om objecten te identificeren, de onderzoekers ontwierpen een convolutioneel neuraal netwerk (CNN), die meestal wordt gebruikt om afbeeldingen te classificeren, om specifieke drukpatronen te associëren met specifieke objecten. Maar de truc was om frames uit verschillende soorten grepen te kiezen om een volledig beeld van het object te krijgen.
Het idee was om de manier na te bootsen waarop mensen een object op een paar verschillende manieren kunnen vasthouden om het te herkennen, zonder hun gezichtsvermogen te gebruiken. evenzo, CNN van de onderzoekers kiest maximaal acht semi-willekeurige frames uit de video die de meest ongelijke grepen vertegenwoordigen, bijvoorbeeld, een mok van de bodem vasthoudend, bovenkant, en handvat.
Maar de CNN kan niet zomaar willekeurige frames kiezen uit de duizenden in elke video, of het zal waarschijnlijk geen verschillende grepen kiezen. In plaats daarvan, het groepeert soortgelijke frames bij elkaar, resulterend in verschillende clusters die overeenkomen met unieke grepen. Vervolgens, het trekt één frame uit elk van die clusters, ervoor te zorgen dat het een representatieve steekproef heeft. Vervolgens gebruikt het CNN de contactpatronen die het tijdens de training heeft geleerd om een objectclassificatie uit de gekozen frames te voorspellen.
"We willen de variatie tussen de frames maximaliseren om de best mogelijke input aan ons netwerk te geven, " zegt Kellnhofer. "Alle frames binnen een enkele cluster moeten een vergelijkbare handtekening hebben die de vergelijkbare manieren voorstelt om het object vast te pakken. Sampling van meerdere clusters simuleert een mens die interactief verschillende grepen probeert te vinden tijdens het verkennen van een object."
Voor gewichtsschatting, de onderzoekers bouwden een aparte dataset van ongeveer 11, 600 frames van tactiele kaarten van objecten die met vinger en duim worden opgepakt, gehouden, en viel. Opmerkelijk, de CNN is niet getraind op frames waarop het is getest, wat betekent dat het niet kon leren om alleen gewicht te associëren met een object. Bij het testen, een enkel frame werd ingevoerd in de CNN. Eigenlijk, de CNN pikt de druk rond de hand op die wordt veroorzaakt door het gewicht van het object, en negeert druk veroorzaakt door andere factoren, zoals handpositionering om te voorkomen dat het object wegglijdt. Vervolgens berekent het het gewicht op basis van de juiste drukken.
Het systeem kan worden gecombineerd met de sensoren die al op robotgewrichten zitten die koppel en kracht meten, zodat ze het gewicht van objecten beter kunnen voorspellen. "Gewrichten zijn belangrijk voor het voorspellen van het gewicht, maar er zijn ook belangrijke componenten van het gewicht van de vingertoppen en de handpalm die we vastleggen, ' zegt Sundaram.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Er is meer dan één manier om decarbonisatie te versnellen
Er is meer dan één manier om decarbonisatie te versnellen- NASA ziet tropische depressie Man-yi, waarschuwingen geactiveerd
- Atmosphere Experiments for Kids
- China's invoerverbod voor afval zet de wereldwijde recyclingindustrie op zijn kop
- Klimaatonderzoeker:Nu actie ondernemen tegen klimaatverandering is onze beste kans op een aanvaardbare toekomst
Hoofdlijnen
- VS keuren herstelplan voor Mexicaanse wolven goed
- Waarom mensen schreeuwen,
- Chloroplast: definitie, structuur en functie (met diagram)
- Amerikaans sage hoenbeleid keert terug naar af
- Wat is Herschikking in Meiose?
- Knoflook kan chronische infecties bestrijden
- Maak een lijst van de 3 stappen die optreden tijdens de interfase
- Nieuwe studie toont aan dat cannabis het geheugen van oudere muizen verhoogt
- Bioprocessing-ingenieurs winnen glucosinolaat uit oliezaadmeel






 Materialen die infrarode stralen absorberen
Materialen die infrarode stralen absorberen - Astronomen lossen mysterie van massa van witte dwergen op
- Landbeweging in Duitsland in kaart gebracht
- Hoe beïnvloedt Weathering monumenten?
- Wanneer sterrenstelsels botsen:Hubble toont zes prachtige fusies van sterrenstelsels
- Agaten snijden
- Franse rechtbank steunt Uber-chauffeur in belangrijke zaak over gig-economie (update)
- Betere RNA-interferentie, geïnspireerd door de natuur:nieuwe nanodeeltjes bieden de beste genuitschakeling ooit
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | Dutch | Danish | Norway | French | German |

-
Wetenschap © https://nl.scienceaq.com
