Wetenschap
Nieuw AI-systeem bootst na hoe mensen objecten visualiseren en identificeren

Een "computer vision"-systeem ontwikkeld aan de UCLA kan objecten identificeren op basis van slechts gedeeltelijke glimpen, zoals door deze fotofragmenten van een motorfiets te gebruiken. Krediet:Universiteit van Californië, Los Angeles
Ingenieurs van de UCLA en Stanford University hebben een computersysteem gedemonstreerd dat de echte objecten die het 'ziet' kan ontdekken en identificeren op basis van dezelfde methode van visueel leren die mensen gebruiken.
Het systeem is een vooruitgang in een soort technologie genaamd "computer vision, " waarmee computers visuele beelden kunnen lezen en identificeren. Het zou een belangrijke stap kunnen zijn in de richting van algemene kunstmatige-intelligentiesystemen - computers die zelfstandig leren, zijn intuïtief, beslissingen nemen op basis van redenering en op een veel menselijkere manier met mensen omgaan. Hoewel de huidige AI-computervisiesystemen steeds krachtiger en capabeler worden, ze zijn taakspecifiek, wat betekent dat hun vermogen om te identificeren wat ze zien wordt beperkt door hoeveel ze zijn getraind en geprogrammeerd door mensen.
Zelfs de beste computervisiesystemen van tegenwoordig kunnen geen volledig beeld van een object creëren nadat ze slechts bepaalde delen ervan hebben gezien - en de systemen kunnen voor de gek gehouden worden door het object in een onbekende omgeving te bekijken. Ingenieurs streven ernaar computersystemen met die capaciteiten te maken - net zoals mensen kunnen begrijpen dat ze naar een hond kijken, zelfs als het dier zich achter een stoel verstopt en alleen de poten en staart zichtbaar zijn. mensen, natuurlijk, kan ook gemakkelijk aanvoelen waar het hoofd van de hond en de rest van zijn lichaam zijn, maar dat vermogen ontgaat de meeste kunstmatige-intelligentiesystemen nog steeds.
De huidige computervisiesystemen zijn niet ontworpen om zelfstandig te leren. Ze moeten precies worden getraind in wat ze moeten leren, meestal door duizenden afbeeldingen te bekijken waarin de objecten die ze proberen te identificeren voor hen zijn gelabeld. Computers, natuurlijk, kunnen ook niet hun redenering verklaren om te bepalen wat het object op een foto vertegenwoordigt:op AI gebaseerde systemen bouwen geen intern beeld of een gezond verstandsmodel van geleerde objecten zoals mensen dat doen.
De nieuwe methode van de ingenieurs, beschreven in de Proceedings van de National Academy of Sciences , geeft een manier om die tekortkomingen te omzeilen.
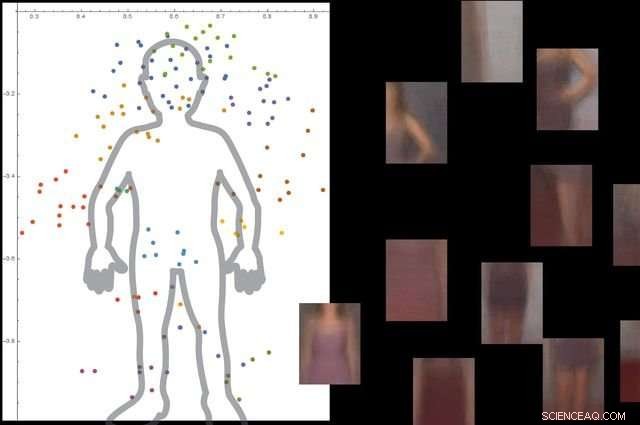
Het systeem begrijpt wat een menselijk lichaam is door naar duizenden afbeeldingen te kijken met mensen erop, en vervolgens niet-essentiële achtergrondobjecten negeren. Krediet:Universiteit van Californië, Los Angeles
De aanpak bestaat uit drie brede stappen. Eerst, het systeem verdeelt een afbeelding in kleine stukjes, die de onderzoekers 'viewlets' noemen. Tweede, de computer leert hoe die viewlets in elkaar passen om het object in kwestie te vormen. En tenslotte, het kijkt naar andere objecten in de omgeving, en of informatie over die objecten al dan niet relevant is voor het beschrijven en identificeren van het primaire object.
Om het nieuwe systeem te helpen meer te "leren" als mensen, de ingenieurs besloten om het onder te dompelen in een internetreplica van de omgeving waarin mensen leven.
"Gelukkig, het internet biedt twee dingen die een door de hersenen geïnspireerd computervisiesysteem helpen om op dezelfde manier te leren als mensen, " zei Vwani Roychowdhury, een UCLA-professor in elektrische en computertechniek en de hoofdonderzoeker van de studie. "Een daarvan is een schat aan afbeeldingen en video's die dezelfde soorten objecten weergeven. De tweede is dat die objecten vanuit vele perspectieven worden getoond - verduisterd, vogelperspectief, van dichtbij - en ze worden in allerlei verschillende omgevingen geplaatst."
Om het kader te ontwikkelen, de onderzoekers haalden inzichten uit de cognitieve psychologie en de neurowetenschappen.
"Begin als baby's, we leren wat iets is omdat we er veel voorbeelden van zien, in veel contexten, Roychowdhury zei. "Dat contextueel leren is een belangrijk kenmerk van onze hersenen, en het helpt ons robuuste modellen van objecten te bouwen die deel uitmaken van een geïntegreerd wereldbeeld waarin alles functioneel met elkaar verbonden is."
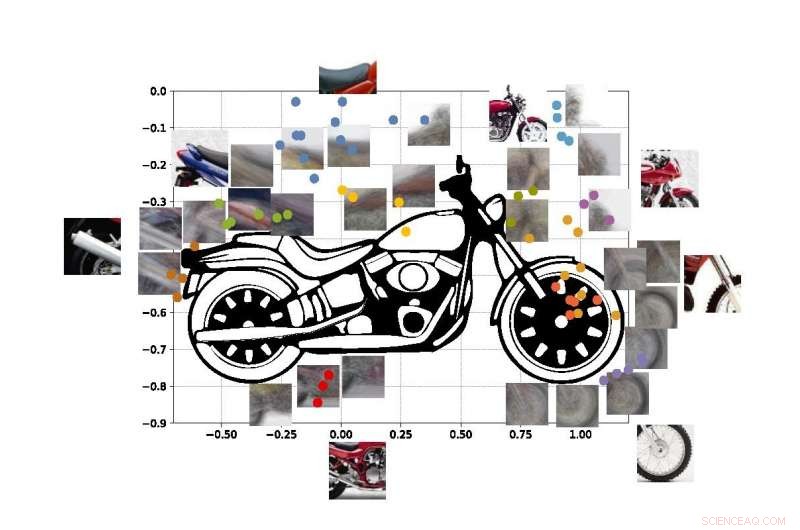
De gekleurde stippen in de afbeelding tonen geschatte coördinaten van de middelpunten van enkele van de viewlets in onze motorfiets SUVM. Elke weergave van een viewlet is een samenstelling van voorbeeldweergaven/patches die er ongeveer hetzelfde uitzien. Krediet:Lichao Chen, Tianyi Wang, en Vwani Roychowdhury (Universiteit van Californië, Los Angeles).
De onderzoekers testten het systeem met ongeveer 9 000 afbeeldingen, elk met mensen en andere objecten. Het platform was in staat om een gedetailleerd model van het menselijk lichaam te bouwen zonder externe begeleiding en zonder dat de afbeeldingen werden gelabeld.
De ingenieurs voerden soortgelijke tests uit met afbeeldingen van motorfietsen, auto's en vliegtuigen. In alle gevallen, hun systeem presteerde beter of minstens even goed als traditionele computer vision-systemen die zijn ontwikkeld met jarenlange training.
De co-senior auteur van de studie is Thomas Kailath, emeritus hoogleraar elektrotechniek aan Stanford, die in de jaren tachtig de doctoraatsadviseur van Roychowdhury was. Andere auteurs zijn voormalige UCLA-doctoraatsstudenten Lichao Chen (nu onderzoeksingenieur bij Google) en Sudhir Singh (die een bedrijf oprichtte dat robotische leergenoten voor kinderen bouwt).
Singh, Roychowdhury en Kailath werkten eerder samen om een van de eerste geautomatiseerde visuele zoekmachines voor mode te ontwikkelen, de nu gesloten StileEye, die aanleiding gaven tot enkele van de basisideeën achter het nieuwe onderzoek.
 Ontketenen van perovskietenpotentieel voor zonnecellen
Ontketenen van perovskietenpotentieel voor zonnecellen- Machine learning-benadering kan helpen bij het ontwerpen van industriële processen voor de productie van geneesmiddelen
- Polymeer maakt sterkere recyclebare thermoplasten mogelijk
- Ingenieurs 3D printen zeer sterk aluminium, los eeuwenoud lasprobleem op met nanodeeltjes
- Hoe subatomaire deeltjes te berekenen
- Birds That Sound Like Owls
- Hoe beïnvloeden grote waterlagen het klimaat van de kustgebieden?
- Uitbreiding van mangroves en klimaatopwarming kunnen ecosystemen helpen gelijke tred te houden met de zeespiegelstijging
- Stadslandbouw biedt slechts kleine milieuvoordelen in het noordoosten van de VS
- in Alaska, iedereen worstelt met klimaatverandering
Hoofdlijnen
- Top tien feiten over de menselijke blaas
- Wetenschappers onthullen eiwitstructuur die cruciaal is voor genexpressie
- Dood door duizend sneden? Niet voor kleine populaties
- Muggendarmbacteriën kunnen aanwijzingen bieden voor malariabestrijding
- Waarom zijn er geen zeeslangen in de Atlantische Oceaan?
- Ongebreidelde consumptie van nijlpaardentanden in combinatie met onvolledige handelsrecords brengen bedreigde nijlpaarden in gevaar
- Science Fair-projecten op handversmettingsmiddelen of vloeibare zeep voor het doden van bacteriën
- Wilgenroosje:de roze pionier
- Dierentuin Praag viert gezondheid zeldzame Maleise tijgerwelpen






 Wetenschappers verkrijgen met succes een synthetische groeifactor die compatibel is met het inheemse eiwit
Wetenschappers verkrijgen met succes een synthetische groeifactor die compatibel is met het inheemse eiwit- Waar komt water vandaan?
- Softbank verlaagt investering in WeWork tot $ 2 miljard
- Ideeën voor een CO2 Car Project
- Onderzoekers tonen aan dat microscopisch kleine houten nanokristallen beton sterker maken
- Sorry, Heren, vuilblindheid bestaat niet - je moet gewoon meer huishoudelijk werk doen
- Vertrouwen opbouwen in kunstmatige intelligentie
- Vernederende sollicitatiegesprekken en pestende bazen komen nog veel te vaak voor
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Norway | Swedish | Danish |

-
Wetenschap © https://nl.scienceaq.com
