Wetenschap
Interpretabiliteit en prestaties:kan hetzelfde model beide bereiken?
Krediet:IBM
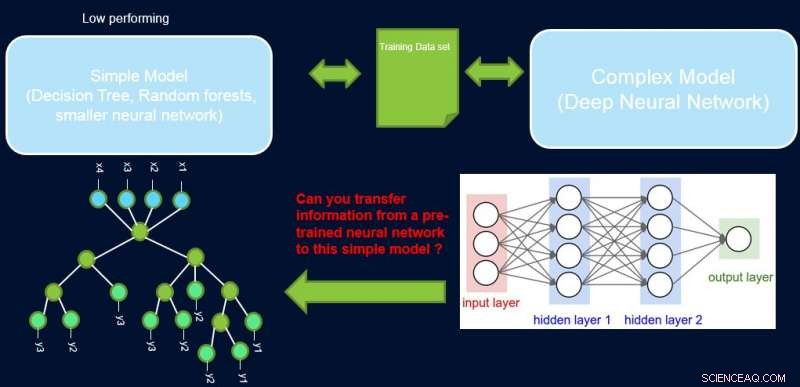
Interpretabiliteit en prestatie van een systeem staan meestal op gespannen voet met elkaar, aangezien veel van de best presterende modellen (namelijk diepe neurale netwerken) een black box-karakter hebben. In ons werk, Eenvoudige modellen verbeteren met vertrouwensprofielen, we proberen deze kloof te overbruggen door een methode voor te stellen om informatie over te dragen van een goed presterend neuraal netwerk naar een ander model dat de domeinexpert of de toepassing mogelijk nodig heeft. Bijvoorbeeld, in computationele biologie en economie, schaarse lineaire modellen hebben vaak de voorkeur, terwijl in complexe geïnstrumenteerde domeinen zoals de fabricage van halfgeleiders, de ingenieurs gebruiken misschien liever beslisbomen. Dergelijke eenvoudiger interpreteerbare modellen kunnen vertrouwen opbouwen bij de deskundige en nuttige inzichten verschaffen die leiden tot ontdekking van nieuwe en voorheen onbekende feiten. Ons doel is hieronder picturaal weergegeven, voor een specifiek geval waarin we de prestaties van een beslisboom proberen te verbeteren.
De veronderstelling is dat ons netwerk een goed presterende leraar is, en we kunnen een deel van de informatie gebruiken om de eenvoudige, interpreteerbaar, maar over het algemeen slecht presterende studentenmodel. Door steekproeven te wegen op hun moeilijkheidsgraad, kan het eenvoudige model zich concentreren op eenvoudigere steekproeven die het met succes kan modelleren tijdens het trainen, en zo betere algemene prestaties te bereiken. Onze opzet is anders dan boosten:in die benadering moeilijke voorbeelden met betrekking tot een eerdere 'zwakke' leerling worden uitgelicht voor een vervolgtraining om diversiteit te creëren. Hier, moeilijke voorbeelden zijn met betrekking tot een nauwkeurig complex model. Dit betekent dat deze labels bijna willekeurig zijn. Bovendien, als een complex model deze niet kan oplossen, er is weinig hoop voor het eenvoudige model van vaste complexiteit. Vandaar, het is belangrijk in onze opstelling om eenvoudige voorbeelden te markeren die het eenvoudige model kan oplossen.
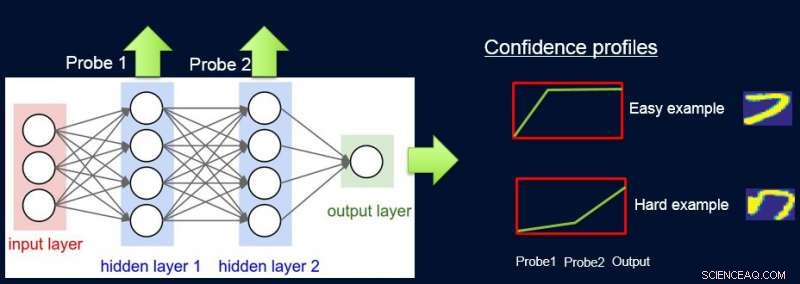
Om dit te doen, we kennen gewichten toe aan monsters volgens de moeilijkheidsgraad van het netwerk om ze te classificeren, en dat doen we door sondes te introduceren. Elke sonde haalt zijn input uit een van de verborgen lagen. Elke sonde heeft een enkele volledig verbonden laag met een softmax-laag in de grootte van de netwerkuitgang die eraan is bevestigd. De sonde in laag i dient als classifier die alleen de prefix van het netwerk tot laag i gebruikt. De veronderstelling is dat eenvoudige instanties met veel vertrouwen correct worden geclassificeerd, zelfs met eerstelaags-sondes, en dus krijgen we vertrouwensniveaus p l van alle probes voor elk van de instanties. We gebruiken alle p l om instantie moeilijkheid te berekenen w l , bijv. als het gebied onder de curve (AUC) van p l 's.
Nu kunnen we de gewichten gebruiken om het eenvoudige model opnieuw te trainen op de uiteindelijke gewogen dataset. We noemen deze pijplijn van sonderen, het verkrijgen van vertrouwensgewichten, en omscholing ProfWeight.
Krediet:IBM
We presenteren twee alternatieven voor het berekenen van gewichten voor voorbeelden in de dataset. In de hierboven genoemde AUC-benadering, we merken de validatiefout/nauwkeurigheid van het eenvoudige model op wanneer getraind op de originele trainingsset. We selecteren sondes met een nauwkeurigheid van minimaal α (> 0) groter dan het eenvoudige model. Elk voorbeeld wordt gewogen op basis van de gemiddelde betrouwbaarheidsscore voor het echte label dat wordt berekend met behulp van de individuele zachte voorspellingen van de sondes.
Een tweede alternatief is optimalisatie met behulp van een neuraal netwerk. Hier leren we optimale gewichten voor de trainingsset door het volgende doel te optimaliseren:
S*=min met wie min β E[λ(Swβ (x), j)], sub. tot. E[w]=1
waarbij w de gewichten zijn die voor elke instantie moeten worden gevonden, β geeft de parameterruimte van het eenvoudige model S aan, en λ is zijn verliesfunctie. We moeten de gewichten beperken, omdat anders de triviale oplossing van alle gewichten naar nul optimaal zal zijn voor het bovenstaande doel. We laten in het artikel zien dat onze beperking van E[w]=1 verband houdt met het vinden van de optimale belangrijkheidssteekproef.
Krediet:IBM
Meer in het algemeen kan ProfWeight worden gebruikt om over te stappen op nog eenvoudigere maar ondoorzichtige modellen zoals kleinere neurale netwerken, die nuttig kan zijn in domeinen met ernstige geheugen- en stroombeperkingen. Dergelijke beperkingen worden ervaren bij het implementeren van modellen op edge-apparaten in IoT-systemen of op mobiele apparaten of op onbemande luchtvaartuigen.
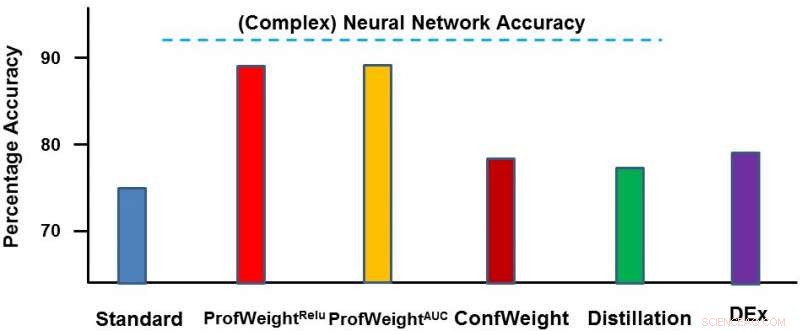
We hebben onze methode getest op twee domeinen:een openbare afbeeldingsdataset CIFAR-10 en een eigen productiedataset. Op de eerste dataset onze eenvoudige modellen waren kleinere neurale netwerken die zouden voldoen aan strikte geheugen- en stroombeperkingen en waar we 3-4 procent verbetering zagen. Op de tweede dataset ons eenvoudige model was een beslisboom en we hebben deze aanzienlijk verbeterd met ~13 procent, wat leidde tot bruikbare resultaten door de ingenieur. Hieronder geven we ProfWeight weer in vergelijking met de andere methoden op deze dataset. We constateren hier dat we de andere methoden ruimschoots overtreffen.
In de toekomst willen we graag noodzakelijke/voldoende voorwaarden vinden wanneer overdracht door onze strategie zou leiden tot verbetering van eenvoudige modellen. We willen ook meer geavanceerde methoden voor informatieoverdracht ontwikkelen dan we al hebben bereikt.
We zullen dit werk presenteren in een paper getiteld "Improving Simple Models with Confidence Profiles" op de 2018 Conference on Neural Information Processing Systems, op woensdag, 5 december tijdens de avondpostersessie van 17.00 – 19.00 uur in Zaal 210 &230 AB (#90).
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Noodmethode voor het meten van strontiumgehaltes in melk
Noodmethode voor het meten van strontiumgehaltes in melk- Hoe zouthloride af te voeren
Zoutzuur, ook bekend als zoutzuur, de op water gebaseerde oplossing van waterstofchloride, is een zeer corrosief zuur. Het wordt gebruikt om batterijen en vuurwerk te maken, gelatine te maken en suiker te verwerken, maa
- Hoe beïnvloedt het veranderen van de temperatuur de viscositeit en oppervlaktespanning van een vloeistof?
- Plastic dat de planeet redt? Nieuwe hars voor startups helpt de industrie groen te worden
- Hoe u redox-vergelijkingen in evenwicht kunt brengen
- Het stabiele temperatuurverleden van de aarde suggereert dat andere planeten ook leven kunnen ondersteunen
- Kan vrije energie maar één spoel verwijderd zijn?
- Vulkanische geo-engineering heeft mogelijk een klimaatcatastrofe veroorzaakt die de meeste diersoorten heeft gedood
- Het gebruik van kolen in China leidt tot veel voortijdige sterfgevallen, modellen geven aan:
- Wat voor soort dieren bestuderen de mariene biologen?
Hoofdlijnen
- Zeven nieuwe spinnensoorten uit Brazilië vernoemd naar zeven beroemde fictieve spinnenpersonages
- Wat zijn de twee belangrijkste functies van nucleïnezuur in levende wezens?
Nucleïnezuren zijn kleine stukjes materie met grote rollen om te spelen. Genoemd naar hun locatie - de kern - deze zuren dragen informatie die cellen helpt bij het maken va
- Ondanks de wet stijgt het aantal doden door loodvergiftiging in New Hampshire
- Meer dan 38 procent van de Neotropische papegaaienpopulatie op het Amerikaanse continent wordt bedreigd door menselijke activiteit
- Doden lindebomen bijen?
- Hebben alle cellen mitochondriën?
- Hoe ribosomen het proteoom vormen
- Eerste luxe Perigord-truffel wordt in Groot-Brittannië verbouwd
- Gebouwde zandbanken zijn niet geschikt voor nestelende plevieren
- Onderzoekers behalen hoogste gecertificeerde efficiëntie van organische zonnecellen tot nu toe

- Google aangeklaagd door Australische toezichthouders wegens locatietracking

- VS rekent acht in rekening voor hacken van effecten

- Het geheim van de doorbraak van lab-on-a-chip:matzwarte nagellak

- Hacker krijgt vijf jaar voor Russisch-gelinkte Yahoo-beveiligingsinbreuk


 3D bioprint, gevasculariseerde proximale tubuli bootsen de reabsorptiefuncties van de menselijke nieren na
3D bioprint, gevasculariseerde proximale tubuli bootsen de reabsorptiefuncties van de menselijke nieren na- Studie onthult de kwantumaard van de interactie tussen fotonen en vrije elektronen
- Difference Between Starfish & Jellyfish
- Parijs wil dieselauto's tegen 2024 uitfaseren
- Soorten gaslassen
- Atmosphere Experiments for Kids
- Afzwakkende tropische storm Xavier waargenomen door NASA
- International Space Station passeert Venus en Saturnus
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Swedish | German | Dutch | Danish | Norway | Portuguese |

-
Wetenschap © https://nl.scienceaq.com
