Wetenschap
Op condensatoren gebaseerde architectuur voor AI-hardwareversnellers
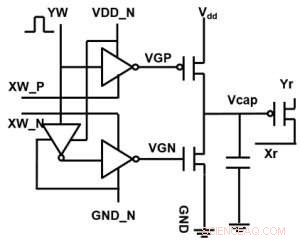
Figuur 1. Eenheidscelschema van een op condensatoren gebaseerde kruispuntarray. Krediet:IBM
IBM reikt verder dan digitale technologieën met een op condensatoren gebaseerde cross-point-array voor analoge neurale netwerken, het vertonen van potentiële ordes van grootte verbeteringen in deep learning berekeningen. Analoge computerarchitecturen maken gebruik van de opslagcapaciteit en fysieke kenmerken van bepaalde geheugenapparaten, niet alleen om informatie op te slaan, maar ook om berekeningen uit te voeren. Dit heeft het potentieel om de tijd en energie die computers nodig hebben aanzienlijk te verminderen, omdat gegevens niet tussen het geheugen en de processor hoeven te worden gependeld. Het nadeel kan een vermindering van de rekennauwkeurigheid zijn, maar voor systemen die geen hoge nauwkeurigheid vereisen, het is de juiste afweging.
In analoge neurale netwerken (NN), niet-vluchtig geheugen (NVM) gebaseerde cross-point arrays hebben veelbelovende resultaten opgeleverd voor inferentietaken. Echter, het trainen van NN's tot hoge nauwkeurigheid is moeilijk voor NVM-apparaten, aangezien een succesvolle training afhangt van het klein houden van de incrementele veranderingen in het NN-gewicht (ongeveer 1 000 updatestatussen) en symmetrisch (zodat positieve en negatieve updates gemiddeld in evenwicht zijn). Dergelijke problemen kunnen worden verholpen door condensatoren te gebruiken. Omdat lading continu kan worden toegevoegd of afgetrokken als het aantal elektronen hoog is, analoge en symmetrische gewichtsupdate kan worden bereikt. We presenteerden een op condensatoren gebaseerde cross-point-array voor analoge neurale netwerken op het VLSI Technology Symposium van 2018. De nieuwe architectuur bereikte recordsymmetrie en lineariteit voor gewichtsupdate.
Figuur 1 toont het eenheidscelschema van een op condensatoren gebaseerde kruispuntarray. Het belangrijkste onderdeel is de condensator die is aangesloten op een uitleesveldeffecttransistor (FET). De lading op de condensator vertegenwoordigt het synaptische gewicht en de condensator wordt geladen en ontladen met twee stroombron-FET's. Figuur 2 toont de gemeten verandering in de conductantie van de uitlees-FET van een enkele cel, en overeenkomstige condensatorspanning respectievelijk, door tien cycli van 400 positieve updates toe te passen, gevolgd door 400 negatieve updates. Figuur 3 vergelijkt de experimentele niet-lineariteitsupdate-factoren voor onze op condensatoren gebaseerde analoge synaps met andere NVM-technologieën. De op condensatoren gebaseerde eenheidscel biedt de beste symmetrie en lineariteit die tot nu toe is aangetoond. Figuur 4 toont parallelle gewichtsupdate op een 2×2 array.
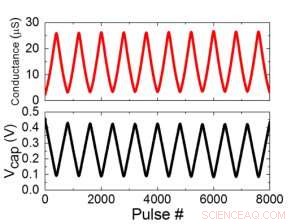
Figuur 2. (a) Experimentele resultaten voor het bijwerken van eencellige met 8000 pulsen. (b) Overeenkomstige condensatorspanningsverandering. Pulsbreedte 50 ns, periode:500 ns. Krediet:IBM
Hoewel condensatoren vluchtig zijn, de lekkage kon worden gecompenseerd tijdens het bijwerken van het gewicht. Omdat de training herhaaldelijk naar voren gaat, achterwaartse en gewichtsupdatecycli, gewichten na verval in de vorige cyclus worden gebruikt bij de training voor de volgende cyclus en worden bijgewerkt. Daarom, er zijn geen opzettelijke verversingscycli nodig. We hebben het effect van retentietijd op training getest, gebruikmakend van een volledig verbonden netwerk. Het heeft één invoerlaag, twee verborgen lagen, en één uitvoerlaag (Figuur 5) en werd getraind op de MNIST-gegevensset door stochastische gradiëntafdaling en terugpropagatie. Ervan uitgaande dat de lengte van de trainingscyclus per laag (vooruit+achteruit+update) 200 ns is en het synaptisch gewicht afneemt met RC-tijdconstante τ, we ontdekten dat de boete in trainingsnauwkeurigheid als gevolg van verlies van condensatorlading verwaarloosbaar wordt wanneer τ> 106 × de lengte van de trainingscyclus (Figuur 6). We hebben ook de retentietijdvereiste voor een convolutienetwerk getest. Ons testnetwerk heeft twee convolutionele lagen met twee pooling-lagen en twee volledig verbonden lagen (Figuur 7). Door de gewichtsverdeling (hergebruik) in convolutionele lagen, de retentievereisten voor een convolutief neuraal netwerk (CNN) zijn ongeveer 600 groter (Figuur 8).
We schatten de schaalbaarheid van deze op condensatoren gebaseerde array als een functie van lekkage voor zowel volledig verbonden als convolutionele neurale netwerken (Figuur 9). Cirkelgegevenspunten laten zien dat de condensator lineair schaalt met doorlaattransistorlekkage. Vierkante datapunten laten zien dat wanneer de lekkage groot is, het celgebied wordt gedomineerd door de condensatoren; wanneer de lekstroom klein is, het gebied zal worden gedomineerd door FET's in de cel. Voor DRAM-technologie met lekkage van 1 fA/cel is een condensator vereist <1fF/cel voor volledig verbonden neuraal netwerk en ~ 100 fF/cel voor CNN. De schaalbaarheid naar grotere invoer en meer lagen moet verder worden onderzocht. Ook al heeft het misschien een grotere condensator nodig als de ingang groter wordt, onze voorlopige resultaten (te publiceren) laten zien dat netwerk-/algoritme-optimalisatie de condensatorbehoefte zou kunnen verminderen.
IBM werkt nu aan een nieuw ideaal geheugen met geoptimaliseerd analoog gedrag. Met deze condensatoren kan de analoge AI-kern versneld worden geïmplementeerd, aangezien de technologie en het proces beschikbaar zijn.
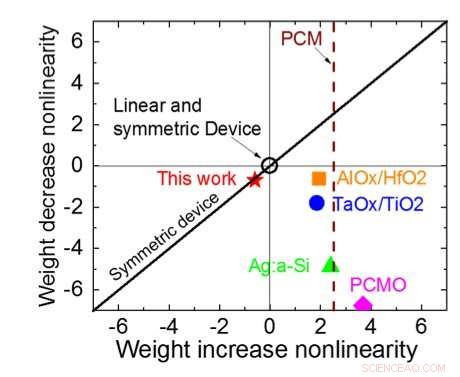
Figuur 3. Geleiding non-lineariteit van dit werk in vergelijking met andere NVM-technologieën. Krediet:IBM
Naast onze condensatorbenadering, IBM onderzoekt andere nieuwe elementen voor analoog geheugen en berekening, zoals phase change memory (PCM) en resistive RAM (RRAM). Deze elementen variëren in celgebieden, behoud, symmetrie, en volwassenheid. Analoge versnellers zijn een onderdeel van IBM Research AI's pijplijn van AI-hardwareversnellers. De pijplijn begint met het optimaal benutten van bestaande GPU-versnellers, gevolgd door innovatieve digitale AI-kernen die gebruik maken van benaderende computing.
-
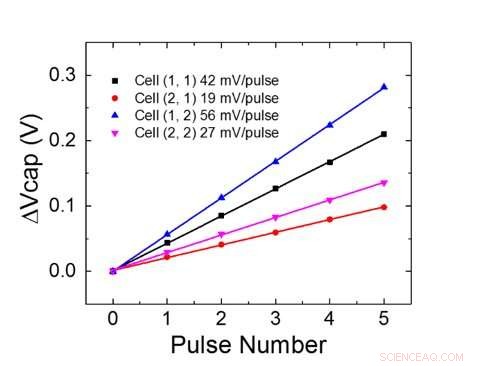
Figuur 4. Parallelle gewichtsupdate op een 2×2 array. Krediet:IBM
-
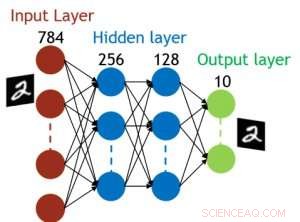
Figuur 5. Gesimuleerde structuur voor volledig verbonden neuraal netwerk. Krediet:IBM
-
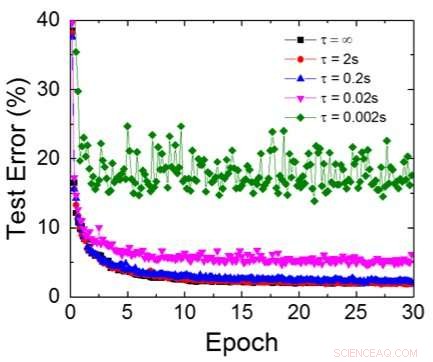
Figuur 6. Gesimuleerde testfout van MNIST-dataset, ervan uitgaande dat gewichten continu afnemen met verschillende RC-tijdconstanten τ, Lengte van de trainingscyclus van 200ns. Krediet:IBM
-
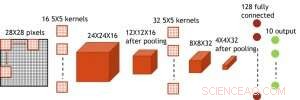
Figuur 7. Gesimuleerde structuur voor convolutief neuraal netwerk. Krediet:IBM
-
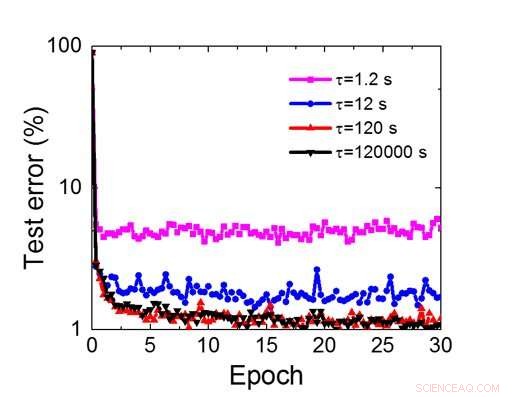
Figuur 8. Gesimuleerde retentietijdvereiste voor deze op condensatoren gebaseerde array om convolutioneel neuraal netwerk te trainen. Krediet:IBM
-
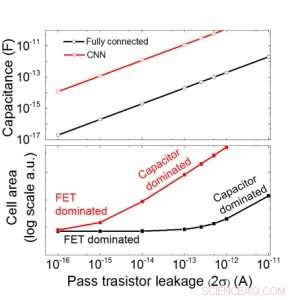
Afbeelding 9. Schaalbaarheid van deze op condensatoren gebaseerde array als functie van lekkage voor zowel volledig verbonden als convolutionele neurale netwerken. Krediet:IBM
 Hoe de PKA te berekenen in titratie
Hoe de PKA te berekenen in titratie - Zwaar metaalbindend domein in een cysteïnerijk eiwit kan de aanpassing van de zeeslak aan metaalstress zijn
- Een nieuw magnetisch materiaal en opnameproces om de datacapaciteit enorm te vergroten
- Studie:structuur van biokatalysatoren hangt af van of ze zich in cellen of in de reageerbuis bevinden
- Berekeningen voor microdruppels per minuut oefenen
Hoofdlijnen
- Zonder te ruimen, Victoria's plan voor wilde paarden lijkt te mislukken
- Resultaten van Landmark NASA DNA Twin Study zijn binnen
- Hoe creëren de hersenen een ononderbroken kijk op de wereld?
- Wat is een zuivere eigenschap en een hybride eigenschap?
- Wat is het oudste levende wezen op aarde?
- Trilaminaire structuur van het celmembraan
- Amerikaanse biologische klok-genetici winnen Nobelprijs voor Geneeskunde 2017
- Subtiele signalen kunnen het lot van stamcellen dicteren
- Wetenschappers bundelen hun krachten om Puerto Ricos Monkey Island te redden






 De herinnering aan gletsjers bewaren
De herinnering aan gletsjers bewaren- Drijvende magnetische microrobots voor vezelfunctionalisatie
- Chinese astronomen ontdekken 591 hogesnelheidssterren met LAMOST en Gaia
- Meelkracht:hoe shoppers kiezen welk brood ze kopen
- Dringende noodzaak om het imago van de landbouw te hervormen om rampzalige arbeidstekorten te voorkomen
- NASA telt de regen van Albertos op in het zuidoosten van de VS en Tennessee Valley
- Mannelijke wetenschappers gebruiken vaker taal die hun onderzoeksresultaten als veelbelovend omkadert, roman, uniek
- De thermische geschiedenis van de komeet verkennen:uitgebrande komeet bedekt met talkpoeder
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Norway | Swedish |

-
Wetenschap © https://nl.scienceaq.com
