Wetenschap
Onderzoek onthult gebreken in populaire genetische methode
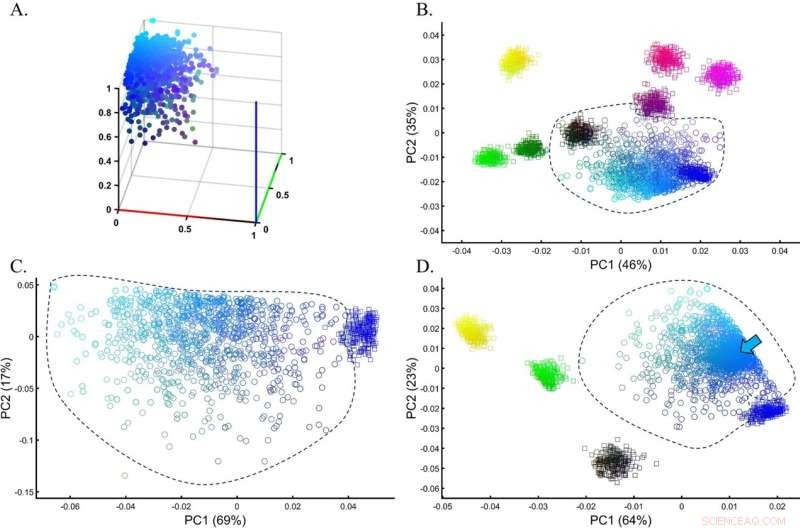
Evaluatie van de nauwkeurigheid van PCA-clustering voor een heterogene testpopulatie in een simulatie van een GWAS-setting. (A) De werkelijke verdeling van de test-cyaanpopulatie (n = 1000). (B) PCA van de testpopulatie met acht even grote (n = 250) monsters van referentiepopulaties. (C) PCA van de testpopulatie met Blue uit de vorige analyse vertoont een minimale overlap tussen de cohorten. (D) PCA van de testpopulatie met vijf even grote (n = 250) monsters van referentiepopulaties, inclusief cyaan (gemarkeerd met een pijl). Kleuren (B) van boven naar beneden en van links naar rechts zijn:Geel [1,1,0], lichtrood [1,0,0.5], Paars [1,0,1], Donkerpaars [0.5,0,0.5 ], Zwart [0,0,0], donkergroen [0,0.5,0], Groen [0,1,0] en Blauw [1,0,0]. Krediet:Wetenschappelijke rapporten (2022). DOI:10.1038/s41598-022-14395-4
Volgens een nieuwe studie van de Universiteit van Lund in Zweden is de meest gebruikte analytische methode binnen de populatiegenetica zeer gebrekkig. Dit kan hebben geleid tot onjuiste resultaten en misvattingen over etniciteit en genetische relaties. De methode is in honderdduizenden onderzoeken gebruikt, wat gevolgen heeft gehad voor de resultaten binnen de medische genetica en zelfs voor commerciële afstammingstests. De studie is gepubliceerd in Scientific Reports .
De snelheid waarmee wetenschappelijke gegevens kunnen worden verzameld, neemt exponentieel toe, wat leidt tot enorme en zeer complexe datasets, de 'Big Data-revolutie' genoemd. Om deze gegevens beter beheersbaar te maken, gebruiken onderzoekers statistische methoden die tot doel hebben de gegevens te comprimeren en te vereenvoudigen, terwijl de meeste belangrijke informatie behouden blijft. Misschien wel de meest gebruikte methode is PCA (principal component analysis). Zie PCA naar analogie als een oven met bloem, suiker en eieren als gegevensinvoer. De oven kan altijd hetzelfde doen, maar het resultaat, een cake, hangt in grote mate af van de verhoudingen van de ingrediënten en hoe ze worden gecombineerd.
"Er wordt verwacht dat deze methode correcte resultaten zal opleveren omdat deze zo vaak wordt gebruikt. Maar het is geen garantie voor betrouwbaarheid en levert ook geen statistisch robuuste conclusies op", zegt Dr. Eran Elhaik, universitair hoofddocent moleculaire celbiologie aan de Universiteit van Lund.
Volgens Elhaik hielp de methode oude percepties over ras en etniciteit te creëren. Het speelt een rol bij het maken van historische verhalen over wie en waar mensen vandaan komen, niet alleen door de wetenschappelijke gemeenschap, maar ook door commerciële voorouderlijke bedrijven. Een beroemd voorbeeld is wanneer een prominente Amerikaanse politicus vóór de presidentiële campagne van 2020 een afkomsttest deed om hun voorouderlijke beweringen te ondersteunen. Een ander voorbeeld is de misvatting van Asjkenazische joden als een ras of een geïsoleerde groep gedreven door PCA-resultaten.
"Deze studie toont aan dat die resultaten onbetrouwbaar waren", zegt Eran Elhaik.
PCA wordt op veel wetenschappelijke gebieden gebruikt, maar het onderzoek van Elhaik richt zich op het gebruik ervan in populatiegenetica, waar de explosie in datasetgroottes bijzonder acuut is, wat wordt veroorzaakt door de lagere kosten van DNA-sequencing.
Het gebied van paleonomica, waar we willen leren over oude volkeren en individuen zoals Europeanen uit het kopertijdperk, is sterk afhankelijk van PCA. PCA wordt gebruikt om een genetische kaart te maken die het onbekende monster naast bekende referentiemonsters plaatst. Tot nu toe is aangenomen dat de onbekende steekproeven gerelateerd zijn aan de referentiepopulatie die ze overlappen of het dichtst bij op de kaart liggen.
Elhaik ontdekte echter dat de onbekende steekproef zo dicht mogelijk bij vrijwel elke referentiepopulatie kon liggen, gewoon door de aantallen en typen van de referentiemonsters te veranderen, waardoor praktisch eindeloze historische versies werden gegenereerd, allemaal wiskundig "correct", maar slechts één kan biologisch correct zijn .
In de studie heeft Elhaik de twaalf meest voorkomende populatiegenetische toepassingen van PCA onderzocht. Hij heeft zowel gesimuleerde als echte genetische gegevens gebruikt om te laten zien hoe flexibel PCA-resultaten kunnen zijn. Volgens Elhaik betekent deze flexibiliteit dat conclusies op basis van PCA niet kunnen worden vertrouwd, aangezien elke wijziging aan de referentie- of testmonsters andere resultaten zal opleveren.
Alleen al in de genetica tussen 32.000 en 216.000 wetenschappelijke artikelen hebben PCA gebruikt voor het onderzoeken en visualiseren van overeenkomsten en verschillen tussen individuen en populaties en hun conclusies op deze resultaten gebaseerd.
"Ik geloof dat deze resultaten opnieuw moeten worden geëvalueerd", zegt Elhaik.
Hij hoopt dat de nieuwe studie een betere benadering zal ontwikkelen om resultaten in twijfel te trekken en zo de wetenschap betrouwbaarder te maken. Hij besteedde een aanzienlijk deel van het afgelopen decennium aan het pionieren van dergelijke methoden, zoals de geografische populatiestructuur (GPS), voor het voorspellen van biogeografie op basis van DNA, en de Pairwise Matcher, die case-control-matches verbetert die worden gebruikt in genetische tests en medicijnproeven.
"Technieken die zo'n flexibiliteit bieden, moedigen slechte wetenschap aan en zijn bijzonder gevaarlijk in een wereld waar er een intense druk is om te publiceren. Als een onderzoeker PCA meerdere keren uitvoert, zal de verleiding altijd zijn om de output te selecteren die het beste verhaal maakt", voegt prof. William Amos, van de Universiteit van Cambridge, die niet betrokken was bij het onderzoek. + Verder verkennen
Onderzoekers ontwikkelen de eerste op AI gebaseerde methode om archeologische overblijfselen te dateren
 Nieuwe SERS-sensor helpt bij het detecteren van aldehydegassen
Nieuwe SERS-sensor helpt bij het detecteren van aldehydegassen- Startup schaalt koolstof nanobuismembranen op om koolstofvrije brandstoffen te maken voor minder dan fossiele brandstoffen
- Nieuw materiaal levert zacht, elastische voorwerpen die aanvoelen als menselijk weefsel
- Wat zijn de eigenschappen en kenmerken van statische elektriciteit?
- Wat gebeurt er met piepschuim in een magnetron?
- Kan geo-engineering op zonne-energie zowel klimaatverandering als inkomensongelijkheid verminderen?
- Soorten gekko's in Arizona
- Virussen kunnen moeilijker te doden zijn na aanpassing aan warme omgevingen
- NASA krijgt een infraroodbeeld van de intensivering van de tropische storm Ileana
- Hoe u zanddollars op het strand kunt vinden
Hoofdlijnen
- Moet het houden van reptielen en amfibieën als huisdier worden beperkt?
- Eens in de eeuw bloeien en zaaien van dwergbamboe verhoogt de muizenpopulaties
- Wat zijn de rollen van chlorofyl A & B?
- Planten evolueren geuren en kleuren om dieren aan te trekken voor zaadverspreiding
- Uit onderzoek blijkt dat wassen effectief lood verwijdert uit groenten die in stedelijke grond worden verbouwd
- Hoe een cellenvorm zijn functie beïnvloedt
- Wetenschap verklaart de kleur van je kerst
- Genmutatie: definitie, oorzaken, typen, voorbeelden
- Nieuwe technologie verlicht microben die niet in een laboratorium kunnen worden gekweekt
- Scheepslawaai beïnvloedt het vermogen van mariene soorten om te communiceren

- Duizenden pinguïnkuikens verhongeren op Antarctica

- Onderzoekers ontwikkelen een gel voor het kweken van grote hoeveelheden neurale stamcellen
- Turkije bevrijdt 7, 500 illegaal opgejaagde kikkers de rivier in

- Scheepsreus verandert koers om walvissen in Sri Lanka te redden


 Afbeelding:Hubbles merkwaardig geval van een calciumrijke supernova
Afbeelding:Hubbles merkwaardig geval van een calciumrijke supernova- Een spreidingsgrafiek interpreteren
- Hoe vogels in zwermen vliegen
- Verduidelijking van plasma-oscillatie door hoogenergetische deeltjes
- VN bevestigt 18,3C recordhitte op Antarctica
- De magnetische eigenschappen van multifunctionele ijzeren nanodraden afstemmen
- Metamateriaal absorbers voor infrarood inspectietechnologieën
- Solar Orbiter bereidt zich voor op feestelijke Venus-flyby
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
