Wetenschap
Onderzoekers gebruiken machine learning-techniek om nieuwe overgangsmetaalverbindingen snel te evalueren
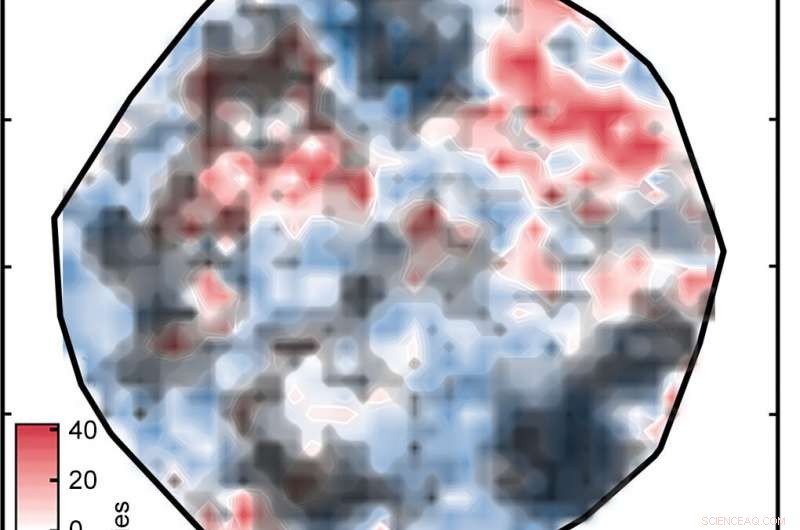
Resultaten van een kunstmatige neurale netwerkanalyse (ANN) zijn mogelijk niet betrouwbaar voor moleculen die te veel verschillen van die waarop de ANN is getraind. De hier getoonde zwarte wolken bedekken overgangsmetaalcomplexen in de dataset waarvan de numerieke representaties te ver verwijderd zijn van die van de trainingscomplexen om als betrouwbaar te worden beschouwd. Krediet:Massachusetts Institute of Technology
In recente jaren, machine learning is een waardevol hulpmiddel gebleken voor het identificeren van nieuwe materialen met eigenschappen die zijn geoptimaliseerd voor specifieke toepassingen. Werken met grote, goed gedefinieerde datasets, computers leren een analytische taak uit te voeren om een juist antwoord te genereren en gebruiken vervolgens dezelfde techniek op een onbekende dataset.
Hoewel die benadering de ontwikkeling van waardevolle nieuwe materialen heeft geleid, het waren voornamelijk organische verbindingen, opmerkingen Heather Kulik Ph.D. '09, een assistent-professor chemische technologie. Kulik richt zich in plaats daarvan op anorganische verbindingen, in het bijzonder die op basis van overgangsmetalen, een familie van elementen (inclusief ijzer en koper) die unieke en nuttige eigenschappen hebben. In die verbindingen - bekend als overgangsmetaalcomplexen - komt het metaalatoom in het midden voor met chemisch gebonden armen, of liganden, gemaakt van koolstof, waterstof, stikstof, of zuurstofatomen die naar buiten stralen.
Overgangsmetaalcomplexen spelen al een belangrijke rol in gebieden variërend van energieopslag tot katalyse voor de productie van fijnchemicaliën, bijvoorbeeld, voor geneesmiddelen. Maar Kulik denkt dat machine learning het gebruik ervan verder zou kunnen uitbreiden. Inderdaad, haar groep heeft niet alleen gewerkt aan het toepassen van machine learning op anorganische stoffen - een nieuwe en uitdagende onderneming - maar ook aan het gebruik van de techniek om nieuwe gebieden te verkennen. "We waren geïnteresseerd in hoe ver we onze modellen konden pushen om ontdekkingen te doen - om voorspellingen te doen over verbindingen die nog niet eerder zijn gezien, ' zegt Kulik.
Sensoren en computers
De afgelopen vier jaar heeft Kulik en Jon Paul Janet, een afgestudeerde student chemische technologie, hebben zich gericht op overgangsmetaalcomplexen met "spin" - een kwantummechanische eigenschap van elektronen. Gebruikelijk, elektronen komen in paren voor, één met spin-up en de andere met spin-down, dus ze heffen elkaar op en er is geen netto spin. Maar in een overgangsmetaal, elektronen kunnen ongepaard zijn, en de resulterende netto spin is de eigenschap die anorganische complexen interessant maakt, zegt Kulik. "Door af te stemmen op hoe ongepaard de elektronen zijn, hebben we een unieke knop voor het afstemmen van eigenschappen."
Een bepaald complex heeft een voorkeursspintoestand. Maar voeg wat energie toe - zeg, van licht of warmte - en het kan omslaan naar de andere staat. In het proces, het kan veranderingen vertonen in macroschaaleigenschappen zoals grootte of kleur. Wanneer de energie die nodig is om de omslag te veroorzaken - de spin-splitsende energie genoemd - bijna nul is, het complex is een goede kandidaat voor gebruik als sensor, of misschien als een fundamenteel onderdeel in een kwantumcomputer.
Chemici kennen veel metaal-ligandcombinaties met spinsplitsende energieën van bijna nul, waardoor ze potentiële "spin-crossover" (SCO) -complexen zijn voor dergelijke praktische toepassingen. Maar het volledige scala aan mogelijkheden is enorm. De spin-splitsingsenergie van een overgangsmetaalcomplex wordt bepaald door welke liganden worden gecombineerd met een bepaald metaal, en er zijn bijna eindeloze liganden om uit te kiezen. De uitdaging is om nieuwe combinaties te vinden met de gewenste eigenschap om SCO's te worden - zonder toevlucht te nemen tot miljoenen trial-and-error-tests in een laboratorium.
Moleculen in getallen vertalen
De standaardmanier om de elektronische structuur van moleculen te analyseren, is met behulp van een computationele modelleringsmethode genaamd dichtheidsfunctionaaltheorie, of DFT. De resultaten van een DFT-berekening zijn redelijk nauwkeurig, vooral voor organische systemen, maar het uitvoeren van een berekening voor een enkele verbinding kan uren duren, of zelfs dagen. In tegenstelling tot, een machine learning-tool genaamd een artificieel neuraal netwerk (ANN) kan worden getraind om dezelfde analyse uit te voeren en dit vervolgens in slechts enkele seconden te doen. Als resultaat, ANN's zijn veel praktischer voor het zoeken naar mogelijke SCO's in de enorme ruimte van haalbare complexen.

Deze afbeelding vertegenwoordigt een voorbeeld van een overgangsmetaalcomplex. Een overgangsmetaalcomplex bestaat uit een centraal overgangsmetaalatoom (oranje) omgeven door een reeks chemisch gebonden organische moleculen in structuren die bekend staan als liganden. Krediet:Massachusetts Institute of Technology
Omdat een ANN een numerieke invoer nodig heeft om te werken, de eerste uitdaging van de onderzoekers was om een manier te vinden om een bepaald overgangsmetaalcomplex weer te geven als een reeks getallen, die elk een geselecteerde eigenschap beschrijven. Er zijn regels voor het definiëren van representaties voor organische moleculen, waar de fysieke structuur van een molecuul veel vertelt over zijn eigenschappen en gedrag. Maar toen de onderzoekers die regels voor overgangsmetaalcomplexen volgden, het werkte niet. "De metaal-organische binding is erg lastig om goed te krijgen, " zegt Kulik. "Er zijn unieke eigenschappen van de binding die meer variabel zijn. Er zijn veel meer manieren waarop de elektronen kunnen kiezen om een binding te vormen." Dus moesten de onderzoekers nieuwe regels bedenken voor het definiëren van een representatie die voorspellend zou zijn in de anorganische chemie.
Met behulp van machinaal leren, ze onderzochten verschillende manieren om een overgangsmetaalcomplex weer te geven voor het analyseren van spin-splitsende energie. De resultaten waren het beste wanneer de weergave de meeste nadruk legde op de eigenschappen van het metaalcentrum en de metaal-ligandverbinding en minder nadruk op de eigenschappen van verder weg gelegen liganden. interessant, hun studies toonden aan dat representaties die meer gelijke nadruk legden in het algemeen het beste werkten als het doel was om andere eigenschappen te voorspellen, zoals de lengte van de ligand-metaalbinding of de neiging om elektronen te accepteren.
De ANN . testen
Als een test van hun aanpak, Kulik en Janet - bijgestaan door Lydia Chan, een zomerstagiair van Troy High School in Fullerton, Californië - definieerde een reeks overgangsmetaalcomplexen op basis van vier overgangsmetalen:chroom, mangaan, ijzer, en kobalt - in twee oxidatietoestanden met 16 liganden (elk molecuul kan er maximaal twee hebben). Door die bouwstenen te combineren, ze creëerden een "zoekruimte" van 5, 600 complexen, waarvan sommige bekend en goed bestudeerd, en sommige zijn totaal onbekend.
In eerder werk, de onderzoekers hadden een ANN getraind op duizenden verbindingen die bekend waren in de overgangsmetaalchemie. Om het vermogen van de getrainde ANN te testen om een nieuwe chemische ruimte te verkennen om verbindingen met de beoogde eigenschappen te vinden, ze probeerden het toe te passen op de pool van 5, 600 complexen, 113 waarvan het in de vorige studie had gezien.
Het resultaat was de plot met het label "Figuur 1" in de diavoorstelling hierboven, die de complexen sorteert op een oppervlak zoals bepaald door de ANN. De witte gebieden geven complexen aan met spin-splitsende energieën binnen 5 kilocalorieën per mol nul, wat betekent dat ze potentieel goede SCO-kandidaten zijn. De rode en blauwe gebieden vertegenwoordigen complexen met spin-splitsende energieën die te groot zijn om bruikbaar te zijn. De groene diamanten die in de inzet verschijnen, tonen complexen met ijzercentra en soortgelijke liganden, met andere woorden, verwante verbindingen waarvan de spin-crossover-energieën vergelijkbaar moeten zijn. Hun verschijning in dezelfde regio van het perceel is het bewijs van de goede overeenkomst tussen de vertegenwoordiging van de onderzoekers en de belangrijkste eigenschappen van het complex.
Maar er is één addertje onder het gras:niet alle spin-splitsingsvoorspellingen zijn nauwkeurig. Als een complex heel anders is dan dat waarop het netwerk is getraind, de ANN-analyse is mogelijk niet betrouwbaar - een standaardprobleem bij het toepassen van machinale leermodellen op ontdekkingen in materiaalkunde of scheikunde, merkt Kulik op. Met behulp van een aanpak die in hun vorige werk succesvol leek, de onderzoekers vergeleken de numerieke representaties voor de trainings- en testcomplexen en sloten alle testcomplexen uit waar het verschil te groot was.
Focussen op de beste opties
Het uitvoeren van de ANN-analyse van alle 5, 600 complexen duurden slechts een uur. Maar in de echte wereld, het aantal te onderzoeken complexen zou duizenden keren groter kunnen zijn - en voor veelbelovende kandidaten zou een volledige DFT-berekening nodig zijn. De onderzoekers hadden daarom een methode nodig om een big data-set te evalueren om onaanvaardbare kandidaten te identificeren, zelfs vóór de ANN-analyse. Daartoe, ze ontwikkelden een genetisch algoritme - een benadering geïnspireerd door natuurlijke selectie - om individuele complexen te scoren en degenen die als ongeschikt worden beschouwd te verwijderen.
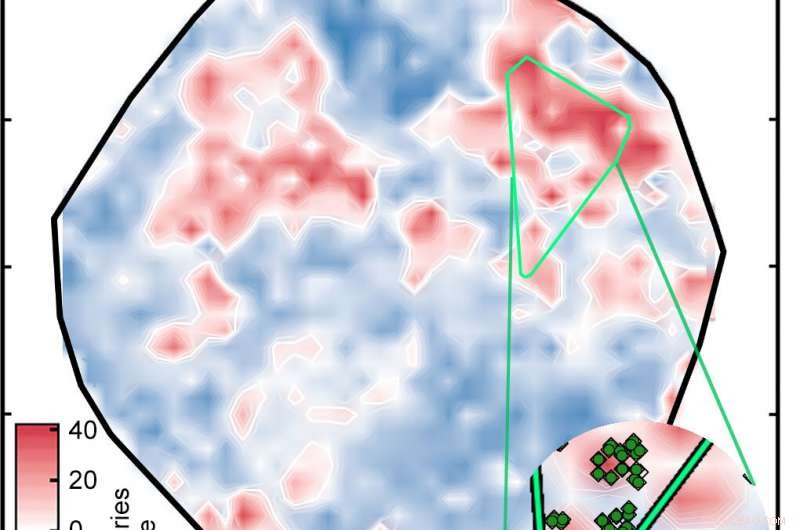
Een kunstmatig neuraal netwerk dat eerder was getraind op bekende verbindingen, analyseerde 5, 600 overgangsmetaalcomplexen om potentiële spin-crossover-complexen te identificeren. Het resultaat was dit perceel, waarin complexen worden gekleurd op basis van hun spin-splitsingsenergie in kilocalorieën per mol (kcal/mol). Bij veelbelovende kandidaten die energie ligt binnen 5 kcal/mol van nul. De felgroene diamanten in de inzet zijn verwante complexen. Krediet:Massachusetts Institute of Technology
Om een dataset vooraf te screenen, het genetische algoritme selecteert eerst willekeurig 20 monsters uit de volledige set complexen. Het wijst vervolgens een "fitness" -score toe aan elk monster op basis van drie metingen. Eerst, is zijn spin-crossover-energie laag genoeg om een goede SCO te zijn? Er achter komen, het neurale netwerk evalueert elk van de 20 complexen. Tweede, is het complex te ver verwijderd van de trainingsgegevens? Als, de spin-crossover-energie van de ANN kan onnauwkeurig zijn. En tenslotte, staat het complex te dicht bij de trainingsgegevens? Als, de onderzoekers hebben al een DFT-berekening uitgevoerd op een vergelijkbaar molecuul, dus de kandidaat is niet geïnteresseerd in de zoektocht naar nieuwe opties.
Op basis van de driedelige evaluatie van de eerste 20 kandidaten, het genetische algoritme gooit ongeschikte opties weg en bewaart de sterkste voor de volgende ronde. Om de diversiteit van de opgeslagen verbindingen te waarborgen, het algoritme roept op dat sommigen van hen een beetje muteren. Eén complex kan een nieuw, willekeurig gekozen ligand, of twee veelbelovende complexen kunnen liganden verwisselen. Ten slotte, als een complex er goed uitziet, dan zou iets vergelijkbaars zelfs nog beter kunnen zijn - en het doel hier is om nieuwe kandidaten te vinden. Het genetische algoritme voegt dan wat nieuwe, willekeurig gekozen complexen om de tweede groep van 20 in te vullen en de volgende analyse uit te voeren. Door dit proces in totaal 21 keer te herhalen, het produceert 21 generaties opties. Het gaat dus door de zoekruimte, zodat de sterkste kandidaten kunnen overleven en zich voortplanten, en de ongeschikten om uit te sterven.
Het uitvoeren van de 21-generatieanalyse op de volledige 5, 600-complexe dataset vereist iets meer dan vijf minuten op een standaard desktopcomputer, en het leverde 372 leads op met een goede combinatie van hoge diversiteit en acceptabel vertrouwen. De onderzoekers gebruikten vervolgens DFT om 56 willekeurig gekozen complexen uit die leads te onderzoeken, en de resultaten bevestigden dat tweederde van hen goede SCO's zou kunnen zijn.
Hoewel een slagingspercentage van tweederde misschien niet geweldig klinkt, de onderzoekers maken twee punten. Eerst, hun definitie van wat een goede SCO zou kunnen zijn, was zeer beperkend:voor een complex om te overleven, zijn spin-splitsende energie moest extreem klein zijn. En ten tweede, gegeven een spatie van 5, 600 complexen en niets om door te gaan, hoeveel DFT-analyses zijn er nodig om 37 leads te vinden? Zoals Janet opmerkt, "Het maakt niet uit hoeveel we met het neurale netwerk hebben geëvalueerd, omdat het zo goedkoop is. Het zijn de DFT-berekeningen die tijd kosten."
Beste van alles, door hun aanpak te gebruiken, konden de onderzoekers een aantal onconventionele SCO-kandidaten vinden die niet zouden zijn bedacht op basis van wat in het verleden is bestudeerd. "Er zijn regels die mensen hebben - heuristieken in hun hoofd - voor hoe ze een spin-crossover-complex zouden bouwen, " zegt Kulik. "We hebben laten zien dat je onverwachte combinaties van metalen en liganden kunt vinden die normaal niet worden bestudeerd, maar veelbelovend kunnen zijn als spin-crossover-kandidaten."
De nieuwe tools delen
Om de wereldwijde zoektocht naar nieuwe materialen te ondersteunen, hebben de onderzoekers het genetische algoritme en ANN verwerkt in "molSimplify, " de groep is online, open-source softwaretoolkit die iedereen kan downloaden en gebruiken om overgangsmetaalcomplexen te bouwen en te simuleren. Om potentiële gebruikers te helpen, de site biedt tutorials die demonstreren hoe de belangrijkste functies van de open-source softwarecodes te gebruiken. De ontwikkeling van molSimplify begon in 2014 met financiering van het MIT Energy Initiative, en alle studenten in Kuliks groep hebben er sindsdien aan bijgedragen.
De onderzoekers blijven hun neurale netwerk verbeteren voor het onderzoeken van potentiële SCO's en om bijgewerkte versies van molSimplify te plaatsen. In de tussentijd, anderen in Kulik's lab ontwikkelen tools die veelbelovende verbindingen voor andere toepassingen kunnen identificeren. Bijvoorbeeld, een belangrijk aandachtsgebied is het ontwerp van de katalysator. Afgestudeerde scheikundestudent Aditya Nandy richt zich op het vinden van een betere katalysator voor het omzetten van methaangas in een gemakkelijker te hanteren vloeibare brandstof zoals methanol - een bijzonder uitdagend probleem. "Nu hebben we een molecuul van buitenaf dat binnenkomt, en ons complex - de katalysator - moet op dat molecuul inwerken om een chemische transformatie uit te voeren die in een hele reeks stappen plaatsvindt, "zegt Nandy. "Machineleren zal super handig zijn bij het uitzoeken van de belangrijke ontwerpparameters voor een overgangsmetaalcomplex dat elke stap in dat proces energetisch gunstig zal maken."
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Machine learning-analyse van röntgengegevens selecteert belangrijke katalytische eigenschappen
Machine learning-analyse van röntgengegevens selecteert belangrijke katalytische eigenschappen- Onderzoekers laten kunstmatige haren groeien met slimme natuurkundige truc
- Wat zijn kristallen?
- Vloeistoffen filteren met vloeistoffen bespaart elektriciteit
- Huidkankermysterie onthuld in yin- en yang-eiwit
- De geheimen van de oceanen ontrafelen
- De rol van een consument in een ecosysteem
- Braziliaanse gemeenschappen bestrijden samen overstromingen – met herinneringen en een app
- Klein lek gevonden van nucleaire Sovjet-onderzeeër die in 1989 zonk
- NASA meet tropische cycloon Noras overstromingsregens in Queensland
Hoofdlijnen
- Het verschil tussen genomisch DNA en plasmide DNA
- Wat zijn Prions?
- Zelfgemaakt skeletmodel
- nieuwe wegen, betere biobrandstoffen
- Alle informatie die nodig is om proteïnen te maken is gecodeerd in DNA door wat?
- Niet alle kroontjeskruid is gelijk voor eierleggende monarchen, studie onthult
- Waarvoor gebruikt het lichaam nucleïnezuren?
- Waarom het een goed idee is om met je dronken oom over politiek te praten
- De drie manieren waarop een RNA-molecuul structureel verschilt van een DNA-molecule
- Zelfvoorzienende lus van chemische reacties kan een revolutie teweegbrengen in de productie van geneesmiddelen
- Structuurvorm die zenuwcellen gebruiken om kou en menthol waar te nemen, kan een nieuw doelwit zijn voor chronische pijn en migraine
- Superoxide produceert hydroxylradicalen die opgeloste organische stoffen in water afbreken
- Power dressing:Elektriciteitsgenererend, rekbaar, zelfherstellende materialen voor wearables

- Transparant hout kan warmte opslaan en afgeven


 Waarom is het zo moeilijk om de afhankelijkheid van benzine te verminderen?
Waarom is het zo moeilijk om de afhankelijkheid van benzine te verminderen? - Doorbraak in waterzuivering maakt gebruik van zonlicht en hydrogels
- X-ploring van de Adelaarsnevel en de Zuilen der Schepping
- Cambridge Analytica-schandaal - legitieme onderzoekers die Facebook-gegevens gebruiken, kunnen bijkomende schade zijn
- Toekomstige ontdekkingsreizigers voorbereiden op een terugkeer naar de maan
- Moleculaire dynamische simulatie werpt nieuw licht op de vorming van methaanhydraat
- Om te knikken of niet om te gespen
- Wat is de titratiecurve?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
