Wetenschap
Onderzoekers ontwikkelen algoritmen om te begrijpen hoe mensen de woordenschat van lichaamsdelen vormen
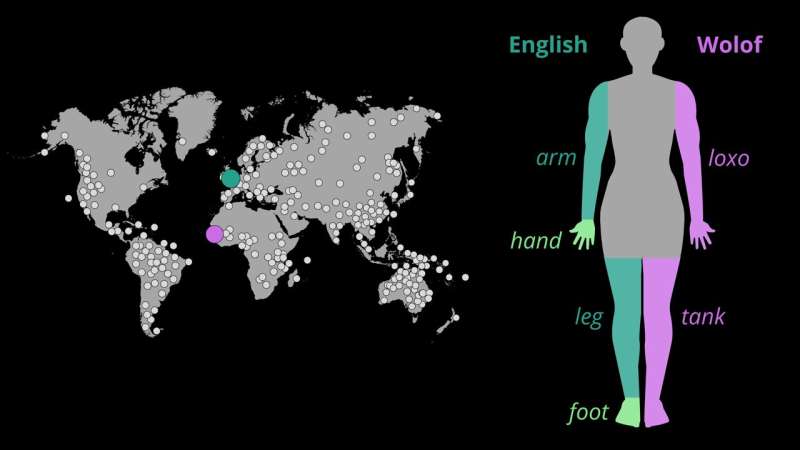
Menselijke lichamen hebben vergelijkbare ontwerpen. Talen verschillen echter in de manier waarop ze het lichaam in delen verdelen en deze een naam geven. Engelssprekenden hebben bijvoorbeeld twee woorden voor voet en been, terwijl andere talen de begrippen voet en been in één woord uitdrukken.
Het onderzoek naar de variatie in de woordenschat van lichaamsdelen in verschillende talen trekt al jaren de aandacht van onderzoekers in de taalkunde, antropologie en psychologie. Vergelijkbaar met de principes die zijn ontwikkeld voor het semantische domein van kleur, zijn universele tendensen geïdentificeerd en gecontrasteerd met cultuurspecifieke variaties.
De opkomst van nieuwe methoden op het gebied van netwerkanalyse heeft het mogelijk gemaakt om grootschalige vergelijkingen van woordenschat in specifieke semantische domeinen uit te voeren om universele en culturele structuren te bestuderen.
Professor Johann-Mattis List, hoofd van de leerstoel Meertalige Computerlinguïstiek aan de Universiteit van Passau, is een van de onderzoekers die algoritmen hebben ontwikkeld om licht te werpen op de vraag hoe mensen hun vocabulaire in verschillende talen vormen.
Hij sloot zich aan bij onderzoekers van de afdeling Taalkundige en Culturele Evolutie van het Max Planck Instituut voor Evolutionaire Antropologie in Leipzig, in hun onderzoek waarbij de woordenschat van lichaamsdelen in 1028 talen werd vergeleken.
Het onderzoek, getiteld 'Universele en culturele factoren vormen de woordenschat van lichaamsdelen', is nu gepubliceerd in Scientific Reports .
Talen verschillen in de manier waarop ze lichaamsdelen benoemen
"Hoewel onze lichamen een vergelijkbaar ontwerp volgen, verschillen talen in de manier waarop ze het lichaam in delen verdelen en een naam geven", zegt Annika Tjuka, een voormalige promovendus bij professor List en nu postdoctoraal onderzoeker bij MPI-EVA, die het onderzoek initieerde en uitvoerde.
‘In het Engels hebben we één woord voor arm en een ander voor hand, maar Wolof, een taal die in Senegal in West-Afrika wordt gesproken, gebruikt één woord, loxo, om naar beide lichaamsdelen te verwijzen. Sprekers van beide talen hebben een menselijk lichaam. waarom verschillen ze in welke onderdelen een unieke naam krijgen?"
De resultaten bevestigen het principe dat als er een apart woord bestaat voor voet, er ook één voor hand zal zijn. Maar de resultaten laten ook zien dat een lichaamsdeel dat aan een ander grenst, waarschijnlijk dezelfde naam heeft. Eén reden voor dit patroon is dat talen als Wolof zich richten op en benadrukken de functionele kenmerken die twee delen met elkaar verbinden.
Sprekers herkennen dat we een bal gooien met onze hand en arm, of dat we lopen met ons been en onze voet. Talen als Engels daarentegen richten zich op visuele aanwijzingen zoals de pols of de enkel om delen van elkaar te scheiden.
De woordenschat van lichaamsdelen varieert van taal tot taal. Binnen deze diversiteit komen echter algemene tendensen naar voren. "Om de factoren te begrijpen die taalkundige diversiteit vormgeven, hebben we meer gegevens nodig. We moeten de talen documenteren die in taalkundig diverse gebieden worden gesproken. En we moeten gegevens verzamelen over de sociologische context waarin de talen worden gesproken", zegt Dr. Tjuka.
Grote verzameling woordenlijsten in alle talen van de wereld
Voor de huidige studie gebruikte het team van taalkundigen een bestaande database, Lexibank, die is ontwikkeld door onderzoekers van de MPI-EVA in Leipzig en de leerstoel Meertalige Computationele Taalkunde in Passau. Het is een grote verzameling woordenlijsten in alle talen van de wereld.
Met een computationele aanpak hebben de onderzoekers uit Passau en Leipzig de woorden voor 36 lichaamsdelen in al deze talen geëxtraheerd en de relaties tussen de woorden geanalyseerd in een netwerkanalyse.
"Het kostte ons enkele jaren om de gegevens in de Lexibank-collectie te verzamelen", zegt professor List, die vroeger als senior onderzoeker bij de MPI-EVA in Leipzig werkte. "Nu kunnen we de gegevens op verschillende manieren gaan analyseren."
Professor List leidt de onderzoeksgroep "ProduSemy" aan de Universiteit van Passau. Samen met zijn onderzoeksteam gebruikt hij de database ook om te begrijpen hoe woordfamilies in verschillende talen worden gevormd.