Wetenschap
Kunnen computers complexe woorden en concepten begrijpen? Ja, volgens onderzoek
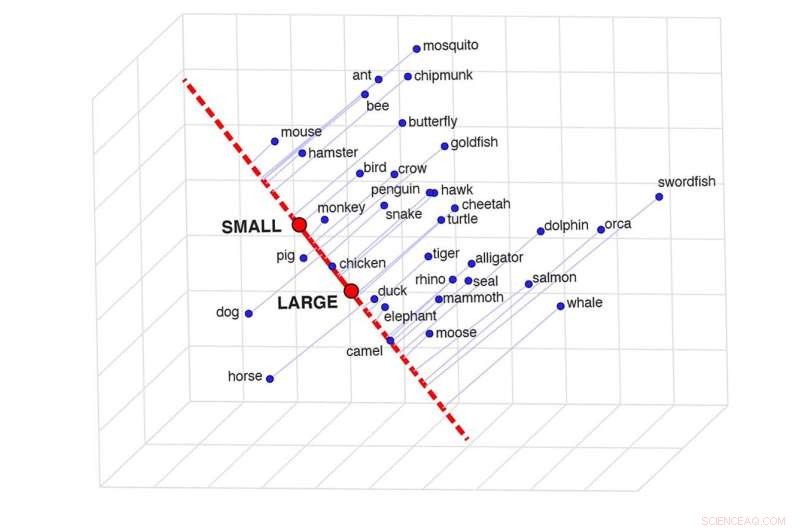
Een afbeelding van semantische projectie, die de overeenkomst tussen twee woorden in een specifieke context kan bepalen. Dit raster laat zien hoe vergelijkbaar bepaalde dieren zijn op basis van hun grootte. Krediet:Idan Blank/UCLA
In 'Through the Looking Glass' zegt Humpty Dumpty minachtend:'Als ik een woord gebruik, betekent het precies wat ik wil dat het betekent - niet meer of minder.' Alice antwoordt:"De vraag is of je woorden zoveel verschillende dingen kunt laten betekenen."
De studie van wat woorden werkelijk betekenen is eeuwenoud. De menselijke geest moet een web van gedetailleerde, flexibele informatie ontleden en geraffineerd gezond verstand gebruiken om de betekenis ervan waar te nemen.
Nu is er een nieuwer probleem ontstaan met betrekking tot de betekenis van woorden:wetenschappers onderzoeken of kunstmatige intelligentie de menselijke geest kan nabootsen om woorden te begrijpen zoals mensen dat doen. Een nieuwe studie door onderzoekers van UCLA, MIT en de National Institutes of Health gaat in op die vraag.
Het artikel, gepubliceerd in het tijdschrift Nature Human Behaviour , meldt dat kunstmatige-intelligentiesystemen inderdaad zeer gecompliceerde woordbetekenissen kunnen leren, en de wetenschappers ontdekten een eenvoudige truc om die complexe kennis te extraheren. Ze ontdekten dat het AI-systeem dat ze bestudeerden de betekenissen van woorden weergeeft op een manier die sterk correleert met het menselijk oordeel.
Het AI-systeem dat de auteurs hebben onderzocht, is de afgelopen tien jaar veelvuldig gebruikt om de betekenis van woorden te bestuderen. Het leert woordbetekenissen te achterhalen door astronomische hoeveelheden inhoud op internet te "lezen", die tientallen miljarden woorden omvat.
Wanneer woorden vaak samen voorkomen, bijvoorbeeld 'tafel' en 'stoel', leert het systeem dat hun betekenissen verwant zijn. En als woordparen zeer zelden samen voorkomen, zoals 'tafel' en 'planeet', leert het dat ze heel verschillende betekenissen hebben.
Die benadering lijkt een logisch uitgangspunt, maar bedenk hoe goed mensen de wereld zouden begrijpen als de enige manier om betekenis te begrijpen was te tellen hoe vaak woorden bij elkaar in de buurt voorkomen, zonder enige mogelijkheid om met andere mensen en onze omgeving te communiceren.
Idan Blank, een UCLA-assistent-professor psychologie en taalkunde, en mede-hoofdauteur van het onderzoek, zei dat de onderzoekers wilden leren wat het systeem weet over de woorden die het leert, en wat voor soort "gezond verstand" het heeft.
Voordat het onderzoek begon, zei Blank, leek het systeem één belangrijke beperking te hebben:"Wat het systeem betreft, hebben elke twee woorden slechts één numerieke waarde die aangeeft hoe vergelijkbaar ze zijn."
Daarentegen is menselijke kennis veel gedetailleerder en complexer.
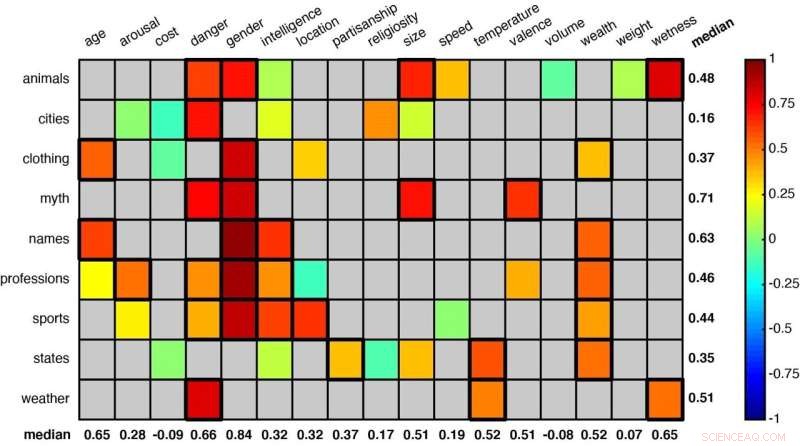
Een raster met enkele van de woordcategorieën die door de onderzoekers zijn geanalyseerd. Statistisch significante combinaties (zoals 'dieren' en 'gevaar' en 'dieren' en 'geslacht' in de eerste rij) worden aangegeven door vierkanten met een dikkere rand. Krediet:Idan Blank/UCLA
"Denk aan onze kennis van dolfijnen en alligators," zei Blank. "Als we de twee vergelijken op een schaal van grootte, van 'klein' tot 'groot', lijken ze relatief op elkaar. In termen van hun intelligentie zijn ze enigszins verschillend. In termen van het gevaar dat ze voor ons vormen, op een schaal van 'veilig' tot 'gevaarlijk', ze verschillen enorm. De betekenis van een woord hangt dus af van de context.
"We wilden ons afvragen of dit systeem deze subtiele verschillen echt kent - of het idee van gelijkenis flexibel is op dezelfde manier als voor mensen."
To find out, the authors developed a technique they call "semantic projection." One can draw a line between the model's representations of the words "big" and "small," for example, and see where the representations of different animals fall on that line.
Using that method, the scientists studied 52 word groups to see whether the system could learn to sort meanings—like judging animals by either their size or how dangerous they are to humans, or classifying U.S. states by weather or by overall wealth.
Among the other word groupings were terms related to clothing, professions, sports, mythological creatures and first names. Each category was assigned multiple contexts or dimensions—size, danger, intelligence, age and speed, for example.
The researchers found that, across those many objects and contexts, their method proved very similar to human intuition. (To make that comparison, the researchers also asked cohorts of 25 people each to make similar assessments about each of the 52 word groups.)
Remarkably, the system learned to perceive that the names "Betty" and "George" are similar in terms of being relatively "old," but that they represented different genders. And that "weightlifting" and "fencing" are similar in that both typically take place indoors, but different in terms of how much intelligence they require.
"It is such a beautifully simple method and completely intuitive," Blank said. "The line between 'big' and 'small' is like a mental scale, and we put animals on that scale."
Blank said he actually didn't expect the technique to work but was delighted when it did.
"It turns out that this machine learning system is much smarter than we thought; it contains very complex forms of knowledge, and this knowledge is organized in a very intuitive structure," he said. "Just by keeping track of which words co-occur with one another in language, you can learn a lot about the world."
The study's co-authors are MIT cognitive neuroscientist Evelina Fedorenko, MIT graduate student Gabriel Grand, and Francisco Pereira, who leads the machine learning team at the National Institutes of Health's National Institute of Mental Health.
 Argon is niet het middel voor metallische waterstof
Argon is niet het middel voor metallische waterstof- Gel die afbreekt, zichzelf weer in elkaar zet kan de levering van orale medicijnen verbeteren
- Nieuw celmembraanmodel kan de sleutel zijn tot het ontdekken van nieuwe eiwiteigenschappen
- Goedkope legering concurreert met duur platina om brandstofcellen te stimuleren
- Een speciale elementaire magie
- Hoe klimaatverandering heeft bijgedragen aan de voedselcrisis in Madagaskar
- dieren in het wild, luchtkwaliteit in gevaar nu Great Salt Lake bijna leeg is
- Voedselketens in het loofbos
- COVID-shutdown-effect op luchtkwaliteit gemengd
- Schade aan de overstromingsgebieden heeft gevolgen voor de woningbouw op lange termijn in risicogebieden
Hoofdlijnen
- Achter de puppy-hondenogen
- Een nieuwe rol voor insuline als vitale factor bij het in stand houden van stamcellen
- Studie belicht botanische vooroordelen
- Hagedis in je bagage? Gebruikten kunstmatige intelligentie om de handel in wilde dieren op te sporen
- Bewijs dat energiemetabolisme en regulatie van biofilmvorming in bacteriën met elkaar verweven zijn
- Grootte van witrotschimmels verklaard door de breedte van de betrokken genfamilies
- Hoe Tiny Robots je gezondheid kunnen verbeteren vanuit het lichaam
- Wetenschappers brengen nieuwe inzichten in de erfelijkheid van de ernst van de hiv-infectie
- Landbouw zorgt voor meer dan 90% van de tropische ontbossing
- Mensen die mannen en vrouwen als fundamenteel verschillend zien, accepteren eerder discriminatie op de werkplek

- Gevangenisstraffen bestraffen niet alleen degenen achter muren

- Nieuwe studie laat zien hoe mensen de neiging kunnen krijgen om snel conclusies te trekken

- Studenten die meer studeren en slapen, doen het niet alleen beter op school - ze zijn gelukkiger, te

- Fysiek en menselijk kapitaal in plaats van militaire uitgaven sleutel voor economische groei in Rusland:studie


 Hertz omzetten in nanometers
Hertz omzetten in nanometers - Hightech regenwoudkaart brengt klimaat- en instandhoudingsinspanningen scherp in beeld
- Hubble ziet een eenzame spiraal
- Waarom stoppen bij plastic zakken en rietjes? Het pleidooi voor een wereldwijd verdrag dat de meeste plastics voor eenmalig gebruik verbiedt
- Donorster blaast zombie-metgezel leven in
- Rijkdom miljardairs bereikt recordhoogte tijdens pandemie
- Ontbrekende gammastraalblobs werpen nieuw licht op donkere materie kosmisch magnetisme
- Nieuwe gel beschermt eieren - en misschien ooit koppen - tegen schade
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
