Wetenschap
Reinforcement learning-based simulaties tonen aan dat de menselijke wens om altijd meer te willen het leren kan versnellen
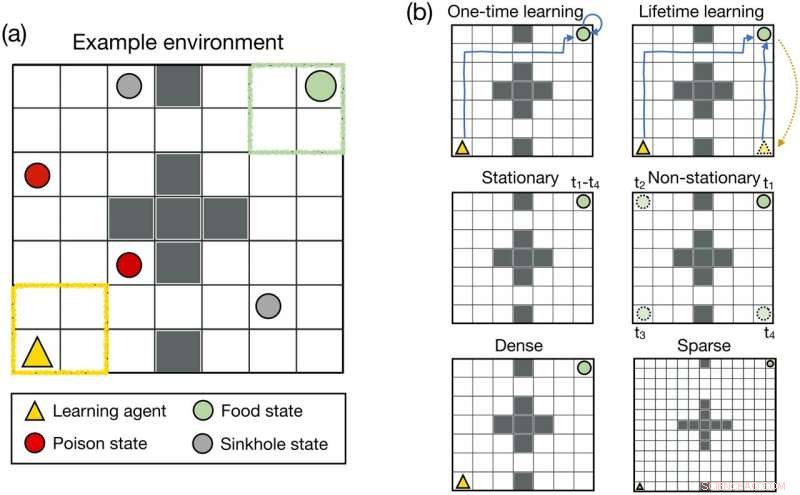
Milieu ontwerp. (a) De tweedimensionale gridworld-omgeving gebruikt in Experiment 1. (b) Om de eigenschappen van de optimale beloning te bestuderen, hebben we verschillende wijzigingen aangebracht in de gridworld-omgeving. Bovenste rij:In de eenmalige leeromgeving kon de agent ervoor kiezen om constant op de voedsellocatie te blijven nadat hij deze had bereikt. In de levenslange leeromgeving werd de agent naar een willekeurige locatie in de rasterwereld geteleporteerd zodra hij de voedselstatus bereikte. Middelste rij:In de stationaire omgeving bleef het voedsel gedurende de levensduur van het middel op dezelfde plaats. In de niet-stationaire omgeving veranderde het voedsel tijdens het leven van de agent van locatie. Onderste rij:we hebben een rasterwereld van 7 × 7 gebruikt om een dichte beloningsinstelling te simuleren. Om een spaarzame beloningsinstelling te simuleren, hebben we de grootte van de gridworld vergroot tot 13 × 13. Credit:PLOS Computational Biology (2022). DOI:10.1371/journal.pcbi.1010316
Een drietal onderzoekers, twee aan de Princeton University en de andere aan het Max Planck Institute for Biological Cybernetics, heeft een op leren gebaseerde simulatie ontwikkeld die aantoont dat de menselijke wens om altijd meer te willen, is geëvolueerd als een manier om het leren te versnellen. In hun paper gepost in de open-access PLOS Computational Biology , beschrijven Rachit Dubey, Thomas Griffiths en Peter Dayan de factoren die in hun simulaties zijn verwerkt.
Onderzoekers die menselijk gedrag bestuderen, zijn vaak verbaasd over de schijnbaar tegenstrijdige verlangens van mensen. Veel mensen hebben een onophoudelijk verlangen naar meer van bepaalde dingen, ook al weten ze dat het voldoen aan die verlangens misschien niet tot het gewenste resultaat leidt. Veel mensen willen bijvoorbeeld steeds meer geld, met het idee dat meer geld het leven makkelijker zou maken, wat hen gelukkiger zou moeten maken. Maar een groot aantal onderzoeken heeft aangetoond dat meer geld verdienen mensen zelden gelukkiger maakt (met uitzondering van degenen die beginnen met een zeer laag inkomensniveau). In deze nieuwe poging probeerden de onderzoekers beter te begrijpen waarom mensen op deze manier zouden zijn geëvolueerd. Daartoe bouwden ze een simulatie om de manier na te bootsen waarop mensen emotioneel reageren op stimuli, zoals het bereiken van doelen. En om beter te begrijpen waarom mensen zich zo voelen, hebben ze controlepunten toegevoegd die kunnen worden gebruikt als een geluksbarometer.
De simulatie was gebaseerd op versterkingsleren, waarbij mensen (of een machine) dingen blijven doen die een positieve beloning bieden en stoppen met dingen te doen die geen beloning of een negatieve beloning bieden. De onderzoekers voegden ook gesimuleerde emotionele reacties toe aan de bekende negatieve effecten van gewenning en vergelijking, waarbij mensen na verloop van tijd minder gelukkig worden als ze aan iets nieuws wennen en minder gelukkig worden als ze zien dat iemand anders meer heeft van iets dat ze willen.
Bij het uitvoeren van de simulatie ontdekten de onderzoekers dat het sneller doelen bereikte wanneer gewenning en vergelijking in het spel kwamen - een suggestie dat dergelijke emotionele reacties ook een rol zouden kunnen spelen bij sneller leren bij mensen. Ze ontdekten ook dat de simulatie minder "gelukkig" werd wanneer ze werden geconfronteerd met meer keuzes met betrekking tot mogelijk haalbare opties dan wanneer er maar een paar waren om uit te kiezen.
De onderzoekers suggereren dat de reden waarom mensen geneigd zijn om vast te zitten in een eindeloze cyclus van altijd meer willen, is omdat het mensen over het algemeen helpt om sneller te leren. + Verder verkennen
Geluk:waarom leren, niet belonen, de sleutel kan zijn
© 2022 Science X Network
 Nieuwe multidisciplinaire benadering voor het identificeren van complexe moleculaire adsorbaten
Nieuwe multidisciplinaire benadering voor het identificeren van complexe moleculaire adsorbaten- Kristalheldere oplosmiddelfiltratie
- Oesterschelpen inspireren nieuwe methode om supersterke, flexibele polymeren
- Tarwegluten kunnen worden gebruikt om duurzaam luiermateriaal te maken
- Op papier gebaseerd apparaat biedt een laag stroomverbruik, langetermijnmethode voor het analyseren van zweet
- Ecologen suggereren dat het tijd is om het moderne gazon te heroverwegen
- Ideeën voor Science Fair-projecten op vis
- De hotspot van de oceaanopwarming in Sydney en Naroom is meer dan drie keer het wereldwijde gemiddelde
- Onderzoek roept op tot betere sanitaire voorzieningen en milieubeheer van geneesmiddelen
- Economische techniek verwijdert geneesmiddelen, chemische verontreinigingen uit openbare watersystemen
Hoofdlijnen
- Chemische vingerafdrukken gebruiken om fraude met zeevruchten en illegale visserij te bestrijden
- Hoe werkt het spierstelsel met de bloedsomloop?
- Nieuwe mutaties in iPS-cellen zijn voornamelijk geconcentreerd in niet-transcriptionele regio's
- Familiebanden geven dieren redenen om te helpen of kwaad te doen naarmate ze ouder worden
- Hoe jaloezie werkt
- Hoe de Amoeben zich reproduceren?
- Vier potvissen sterven bij redding op strand in Indonesië
- Meer bewijs dat Neanderthalers niet dom waren:ze maakten hun eigen touwtje
- Farmacie Onderzoek Onderwerpen
- Zeven morele regels gevonden over de hele wereld

- De koloniale mythe van de naakte Bosjesman ontkrachten

- De beste Ivy League-scholen voor wiskunde en wetenschappen

- Primates of the Caribbean:oud DNA onthult geschiedenis van mysterieuze aap

- Advocatenkantoren moedigen mannen niet aan om ouderschapsverlof op te nemen

 Voedingsmiddelen die je lichaam zuur maken
Voedingsmiddelen die je lichaam zuur maken - Versterkte spontane emissiebron in een meepompende, enkele frequentie Raman-vezelversterker
- Belangrijke VN-gesprekken over klimaatwetenschap geopend te midden van overstromingen, branden
- Angst voor ontrouw drijft vooroordelen tegen biculturele immigranten
- Onderzoekers bereiken 51,5dB niet-wederkerige isolatie
- Hoe maak je een blauwdruk voor kinderen
- Wat gebruiken chloroplasten om glucose te maken?
- Hoe men een deeloplossing met vier delen mengt Water
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
