Wetenschap
Natuurkundigen ontdekken overeenkomsten tussen klassiek en kwantummachine learning
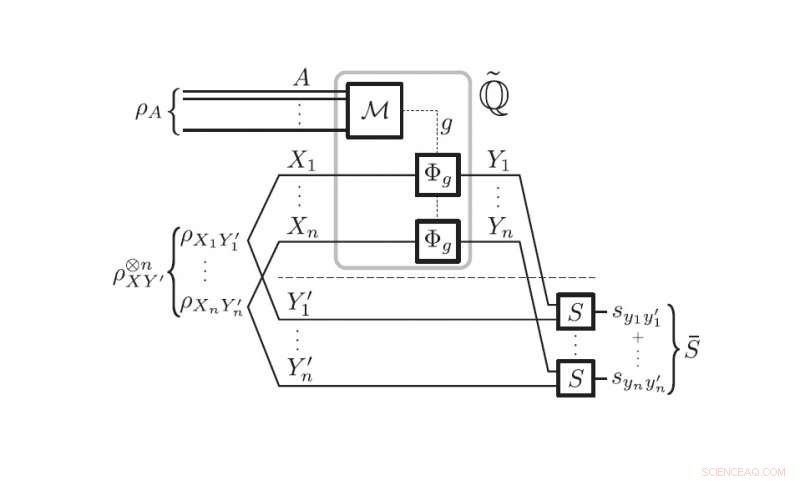
Diagram dat een generiek kwantumleerprotocol vertegenwoordigt. Krediet:Monras et al. ©2017 American Physical Society
(Phys.org) - Natuurkundigen hebben ontdekt dat de structuur van bepaalde soorten kwantumleeralgoritmen sterk lijkt op hun klassieke tegenhangers - een bevinding die wetenschappers zal helpen de kwantumversies verder te ontwikkelen. Klassieke algoritmen voor machine learning worden momenteel gebruikt voor het uitvoeren van complexe rekentaken, zoals patroonherkenning of classificatie in grote hoeveelheden data, en vormen een cruciaal onderdeel van veel moderne technologieën. Het doel van kwantumleeralgoritmen is om deze functies in scenario's te brengen waarin informatie zich in een volledig kwantumvorm bevindt.
De wetenschappers, Alex Monràs aan de Autonome Universiteit van Barcelona, Spanje; Gael Sentís aan de Universiteit van Baskenland, Spanje, en de Universiteit van Siegen, Duitsland; en Peter Wittek bij ICFO-The Institute of Photonic Science, Spanje, en de Universiteit van Borås, Zweden, hebben een paper over hun resultaten gepubliceerd in een recent nummer van Fysieke beoordelingsbrieven .
"Ons werk onthult de structuur van een algemene klasse van kwantumleeralgoritmen op een zeer fundamenteel niveau, "Sentís vertelde" Phys.org . "Het laat zien dat de potentieel zeer complexe operaties die betrokken zijn bij een optimale kwantumopstelling kunnen worden geschrapt ten gunste van een veel eenvoudiger operationeel schema, die analoog is aan degene die wordt gebruikt in klassieke algoritmen, en er gaat geen prestatie verloren in het proces. Deze bevinding helpt bij het vaststellen van de ultieme mogelijkheden van kwantumleeralgoritmen, en opent de deur naar het toepassen van belangrijke resultaten in statistisch leren op kwantumscenario's."
In hun studie hebben de natuurkundigen concentreerden zich op een specifiek type machine learning dat inductief begeleid leren wordt genoemd. Hier, het algoritme krijgt trainingsexemplaren waaruit het algemene regels haalt, en past deze regels vervolgens toe op verschillende test- (of probleem)instanties, wat de werkelijke problemen zijn waarvoor het algoritme is getraind. De wetenschappers toonden aan dat zowel klassieke als kwantuminductieve gesuperviseerde leeralgoritmen deze twee fasen (een trainingsfase en een testfase) moeten hebben die volledig verschillend en onafhankelijk zijn. Terwijl in de klassieke opzet dit resultaat triviaal volgt uit de aard van klassieke informatie, de natuurkundigen toonden aan dat het in het kwantumgeval een gevolg is van de kwantum-niet-klonen-stelling - een stelling die verbiedt het maken van een perfecte kopie van een kwantumtoestand.
Door deze gelijkenis te onthullen, de nieuwe resultaten generaliseren enkele belangrijke ideeën in de klassieke statistische leertheorie naar kwantumscenario's. Eigenlijk, deze generalisatie reduceert complexe protocollen tot eenvoudigere zonder prestatieverlies, waardoor het gemakkelijker wordt om ze te ontwikkelen en uit te voeren. Bijvoorbeeld, een potentieel voordeel is de mogelijkheid om toegang te krijgen tot de status van het leeralgoritme tussen de trainings- en testfasen. Voortbouwend op deze resultaten, de onderzoekers verwachten dat toekomstig werk zou kunnen leiden tot een volledige kwantumtheorie van risicogrenzen in kwantumstatistisch leren.
"Inductief gesuperviseerde kwantumleeralgoritmen zullen worden gebruikt om informatie die is opgeslagen in kwantumsystemen op een geautomatiseerde en aanpasbare manier te classificeren, eenmaal getraind met voorbeeldsystemen, Sentís zei. "Ze zullen potentieel nuttig zijn in allerlei situaties waarin informatie van nature in een kwantumvorm wordt gevonden, en zal waarschijnlijk deel uitmaken van toekomstige protocollen voor de verwerking van kwantuminformatie. Onze resultaten zullen helpen bij het ontwerpen en benchmarken van deze algoritmen tegen de best haalbare prestaties die door de kwantummechanica zijn toegestaan."
© 2017 Fys.org
 Experimenten met geo-engineering om het Great Barrier Reef te beschermen, benadrukken de noodzaak voor de Australische wet om de achterstand in te halen. Onderzoek
Experimenten met geo-engineering om het Great Barrier Reef te beschermen, benadrukken de noodzaak voor de Australische wet om de achterstand in te halen. Onderzoek- NASA ontdekt dat tweede tropisch systeem zich ontwikkelt in de Arabische Zee
- De rotsen lezen:geoloog vindt aanwijzingen voor oude klimaatpatronen in chert
- Loodvergiftiging bij de bron voorkomen
- De bittere les van de Californische branden
Hoofdlijnen
- The Stages of the Human Decomposition Process
- Onze darmmicroben hebben circadiane ritmes,
- Wat zijn de functies van koolhydraten in planten en dieren?
- Hoe werkt het skelet met het ademhalingssysteem?
- Een nieuwe kijk op toerisme en zijn bijdrage aan natuurbehoud in Nieuw-Zeeland
- "What Does Heterozygous Mean?
- Depolarisatie en repolarisatie van het celmembraan
- De voordelen van anaërobe ademhaling
- Is de tweekamerige geest geëvolueerd om het moderne menselijke bewustzijn te creëren?
- Ultrakleine atoombewegingen vastgelegd met ultrakorte röntgenpulsen
- Kwantumtrucs om de geheimen van topologische materialen te onthullen

- Wetenschappers brengen een revolutie teweeg in cyberbeveiliging door middel van kwantumonderzoek

- Nieuwe metalens verschuift de focus zonder te kantelen of te bewegen

- Spanningen en stromen in ultrakoude supervloeistoffen


 Hoe de methaanemissies van de olie- en gasindustrie in Noord-Amerika te verminderen?
Hoe de methaanemissies van de olie- en gasindustrie in Noord-Amerika te verminderen?- De impact van klimaatbeleid en natuurrampen op bedrijven in China
- Hoe X- en Y-intercepts van kwadratische vergelijkingen te vinden
- NASA-NOAA-satelliet die Barry volgt door Louisiana, Arkansas
- Jong, dun en hyperactief - zo zien uitbijterstelsels eruit
- Nieuwe kaarten van zoutgehalte onthullen de impact van klimaatvariabiliteit op oceanen
- Grote levensgebeurtenissen die op sociale media worden gedeeld, doen sluimerende verbindingen herleven, studie toont
- Europa's oudste boom groeit nog steeds
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
