Wetenschap
Hoe betrokkenheid je kwetsbaar maakt voor manipulatie en verkeerde informatie op sociale media
Krediet:het gesprek
Facebook heeft stilletjes geëxperimenteerd met het verminderen van de hoeveelheid politieke inhoud die het in de nieuwsfeeds van gebruikers plaatst. De verhuizing is een stilzwijgende erkenning dat de manier waarop de algoritmen van het bedrijf werken een probleem kan zijn.
De kern van de zaak is het onderscheid tussen het uitlokken van een reactie en het bieden van inhoud die mensen willen. Algoritmen voor sociale media - de regels die hun computers volgen bij het bepalen van de inhoud die u ziet - zijn sterk afhankelijk van het gedrag van mensen om deze beslissingen te nemen. Ze letten in het bijzonder op inhoud waarop mensen reageren of zich 'aantrekken' door ze leuk te vinden, erop te reageren en te delen.
Als computerwetenschapper die de manieren bestudeert waarop grote aantallen mensen met technologie omgaan, begrijp ik de logica van het gebruik van de wijsheid van de menigte in deze algoritmen. Ik zie ook flinke valkuilen in hoe de social media bedrijven dat in de praktijk doen.
Van leeuwen op de savanne tot likes op Facebook
Het concept van de wijsheid van menigten gaat ervan uit dat het gebruik van signalen uit andermans acties, meningen en voorkeuren als leidraad zal leiden tot gefundeerde beslissingen. Zo zijn collectieve voorspellingen doorgaans nauwkeuriger dan individuele. Collectieve intelligentie wordt gebruikt om financiële markten, sport, verkiezingen en zelfs uitbraken van ziekten te voorspellen.
Gedurende miljoenen jaren van evolutie zijn deze principes in het menselijk brein gecodeerd in de vorm van cognitieve vooroordelen die gepaard gaan met namen als vertrouwdheid, loutere blootstelling en bandwagon-effect. Als iedereen begint te rennen, moet jij ook gaan rennen; misschien heeft iemand een leeuw zien komen en rennen die je leven kan redden. Je weet misschien niet waarom, maar het is verstandiger om later vragen te stellen.
Je brein pikt aanwijzingen uit de omgeving op, inclusief je leeftijdsgenoten, en gebruikt eenvoudige regels om die signalen snel in beslissingen te vertalen:ga met de winnaar, volg de meerderheid, kopieer je buurman. Deze regels werken opmerkelijk goed in typische situaties omdat ze gebaseerd zijn op goede aannames. Ze gaan er bijvoorbeeld van uit dat mensen vaak rationeel handelen, het is onwaarschijnlijk dat velen ongelijk hebben, het verleden de toekomst voorspelt, enzovoort.
Technologie stelt mensen in staat toegang te krijgen tot signalen van veel grotere aantallen andere mensen, van wie de meesten ze niet kennen. Toepassingen voor kunstmatige intelligentie maken intensief gebruik van deze populariteits- of "betrokkenheids"-signalen, van het selecteren van zoekresultaten van zoekmachines tot het aanbevelen van muziek en video's, en van het voorstellen van vrienden tot het rangschikken van berichten in nieuwsfeeds.
Niet alles wat viraal is verdient het om te zijn
Uit ons onderzoek blijkt dat vrijwel alle webtechnologieplatforms, zoals sociale media en nieuwsaanbevelingssystemen, een sterke voorkeur hebben voor populariteit. Wanneer applicaties worden aangedreven door signalen zoals betrokkenheid in plaats van expliciete zoekopdrachten van zoekmachines, kan populariteitsbias leiden tot schadelijke onbedoelde gevolgen.
Sociale media zoals Facebook, Instagram, Twitter, YouTube en TikTok zijn sterk afhankelijk van AI-algoritmen om inhoud te rangschikken en aan te bevelen. Deze algoritmen nemen als invoer wat u 'leuk' vindt, becommentarieert en deelt, met andere woorden, inhoud waarmee u zich bezighoudt. Het doel van de algoritmen is om de betrokkenheid te maximaliseren door erachter te komen wat mensen leuk vinden en dit bovenaan hun feeds te plaatsen.
Op het eerste gezicht lijkt dit redelijk. Als mensen van geloofwaardig nieuws, meningen van experts en leuke video's houden, zouden deze algoritmen dergelijke inhoud van hoge kwaliteit moeten identificeren. Maar de wijsheid van de menigte maakt hier een belangrijke veronderstelling:dat het aanbevelen van wat populair is, zal helpen bij het 'opborrelen' van inhoud van hoge kwaliteit.
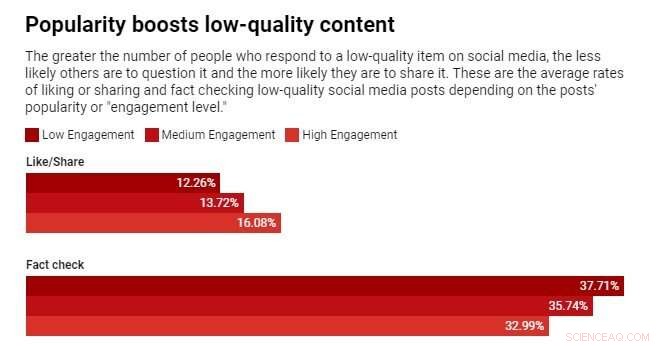
We hebben deze veronderstelling getest door een algoritme te bestuderen dat items rangschikt met een mix van kwaliteit en populariteit. We ontdekten dat populariteitsbias over het algemeen de algehele kwaliteit van inhoud verlaagt. De reden is dat betrokkenheid geen betrouwbare indicator voor kwaliteit is als er maar weinig mensen zijn blootgesteld aan een item. In deze gevallen genereert betrokkenheid een signaal met ruis, en het algoritme zal deze aanvankelijke ruis waarschijnlijk versterken. Zodra de populariteit van een item van lage kwaliteit groot genoeg is, zal het steeds groter worden.
Algoritmen zijn niet het enige dat wordt beïnvloed door betrokkenheidsbias, het kan ook van invloed zijn op mensen. Er zijn aanwijzingen dat informatie wordt overgedragen via "complexe besmetting", wat betekent dat hoe vaker iemand online wordt blootgesteld aan een idee, hoe groter de kans is dat hij het overneemt en opnieuw deelt. Wanneer sociale media mensen vertellen dat een item viraal gaat, treden hun cognitieve vooroordelen op en vertalen zich in de onweerstaanbare drang om er aandacht aan te besteden en het te delen.
Niet zo verstandige mensen
We hebben onlangs een experiment uitgevoerd met een app voor nieuwsgeletterdheid genaamd Fakey. Het is een door ons lab ontwikkeld spel dat een nieuwsfeed simuleert zoals die van Facebook en Twitter. Spelers zien een mix van actuele artikelen uit nepnieuws, junkwetenschap, hyperpartijdige en samenzweerderige bronnen, evenals reguliere bronnen. Ze krijgen punten voor het delen of leuk vinden van nieuws uit betrouwbare bronnen en voor het markeren van artikelen met een lage geloofwaardigheid voor feitencontrole.
We ontdekten dat spelers artikelen eerder leuk vinden of delen en minder geneigd zijn om artikelen uit bronnen met een lage geloofwaardigheid te markeren als spelers kunnen zien dat veel andere gebruikers betrokken zijn geweest bij die artikelen. Blootstelling aan de engagementstatistieken creëert dus een kwetsbaarheid.
De wijsheid van de menigte faalt omdat ze is gebaseerd op de valse veronderstelling dat de menigte is samengesteld uit diverse, onafhankelijke bronnen. Er kunnen verschillende redenen zijn dat dit niet het geval is.
Ten eerste, vanwege de neiging van mensen om met vergelijkbare mensen om te gaan, zijn hun online buurten niet erg divers. Het gemak waarmee een gebruiker van sociale media de vrienden met wie hij het niet eens is, kan ontvrienden, duwt mensen in homogene gemeenschappen, vaak aangeduid als echokamers.
Ten tweede, omdat de vrienden van veel mensen vrienden van elkaar zijn, beïnvloeden ze elkaar. Een beroemd experiment toonde aan dat weten welke muziek je vrienden leuk vinden, invloed heeft op je eigen uitgesproken voorkeuren. Je sociale verlangen om te conformeren verstoort je onafhankelijke oordeel.
Ten derde kunnen populariteitssignalen worden gespeeld. In de loop der jaren hebben zoekmachines geavanceerde technieken ontwikkeld om zogenaamde "linkfarms" en andere schema's om zoekalgoritmen te manipuleren, tegen te gaan. Sociale-mediaplatforms daarentegen beginnen net te leren over hun eigen kwetsbaarheden.
Mensen die de informatiemarkt willen manipuleren, hebben nepaccounts gemaakt, zoals trollen en sociale bots, en nepnetwerken georganiseerd. Ze hebben het netwerk overspoeld om de schijn te wekken dat een samenzweringstheorie of een politieke kandidaat populair is, waarbij ze zowel platformalgoritmen als de cognitieve vooroordelen van mensen in de maling nemen. Ze hebben zelfs de structuur van sociale netwerken veranderd om illusies te creëren over de mening van de meerderheid.
Betrokkenheid terugbellen
Wat moeten we doen? Technologieplatforms zijn momenteel in het defensief. Ze worden agressiever tijdens verkiezingen in het verwijderen van nepaccounts en schadelijke desinformatie. Maar deze inspanningen kunnen lijken op een spel van mep.
Een andere, preventieve benadering zou zijn om frictie toe te voegen. Met andere woorden, om het proces van informatieverspreiding te vertragen. Hoogfrequent gedrag, zoals automatisch leuk vinden en delen, kan worden geremd door CAPTCHA-tests of vergoedingen. Dit zou niet alleen de mogelijkheden voor manipulatie verminderen, maar met minder informatie zouden mensen meer aandacht kunnen besteden aan wat ze zien. Het zou minder ruimte laten voor betrokkenheidsbias om de beslissingen van mensen te beïnvloeden.
Het zou ook helpen als sociale-mediabedrijven hun algoritmen zouden aanpassen om minder afhankelijk te zijn van betrokkenheid bij het bepalen van de inhoud die ze u aanbieden.
 Zoutzuur verhoogt de activiteit van de katalysator
Zoutzuur verhoogt de activiteit van de katalysator- Nieuwe techniek werpt licht op de mysteries van complexe chemische reactienetwerken
- Nieuwe DNA-database bij Rutgers-Camden om forensische wetenschap te versterken
- Onderzoekers produceren een biocel die even effectief is als een platina-brandstofcel
- Ingenieurs ontwikkelen kameleonmetalen die van oppervlak veranderen als reactie op hitte
Hoofdlijnen
- In stedelijke stromen, farmaceutische vervuiling stimuleert microbiële resistentie
- Video:studenten insectenbiologie leren kunst van op insecten gebaseerde kleurstoffen
- Top tien feiten over de menselijke blaas
- Nieuwe slimme sensor om boeren te helpen kreupelheid bij schapen te herkennen
- Wat is de brugfase van glycolyse?
- Wat is een fossiel?
- De functie van macromoleculen
- Waarom door deuropeningen lopen ons doet vergeten
- Het genoom van de zeekomkommer wijst op genen voor weefselregeneratie
- Internet of Things moet geluid gebruiken op een manier waarop computers en telefoons dat nooit hebben gedaan

- Vakanties zorgen voor een toename van phishing-zwendel gericht op kleine bedrijven

- Verkoop van met schulden beladen Air India gaat niet van de grond

- EU-hof beslist dat sites moeten waarschuwen voor Facebook-like-knop

- Apple-problemen opgelost voor FaceTime-afluisterbug


 Maatschappelijke waarden en percepties vormen de productie en het gebruik van energie net zo veel als nieuwe technologie
Maatschappelijke waarden en percepties vormen de productie en het gebruik van energie net zo veel als nieuwe technologie- Overstromingen door orkaan beïnvloeden Lumbee River Basin
- Hoe de ventilatiesnelheid voor een besloten ruimte te berekenen
- Heb je testangst? Hier is hoe ermee om te gaan
- Regen-op-sneeuw overstromingsrisico neemt toe in veel berggebieden in het westen van de VS, Canada
- Onderzoekers introduceren nieuwe theorie om emissieaansprakelijkheid te berekenen
- VS kijken naar alternatieve sancties voor China's ZTE:Ross
- De volgende grote ontdekking in de astronomie? Wetenschappers hebben het waarschijnlijk jaren geleden gevonden - maar ze weten het nog niet
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
