Wetenschap
Het genereren van AI-afbeeldingen vordert met astronomische snelheden. Kunnen we nog zien of een foto nep is?
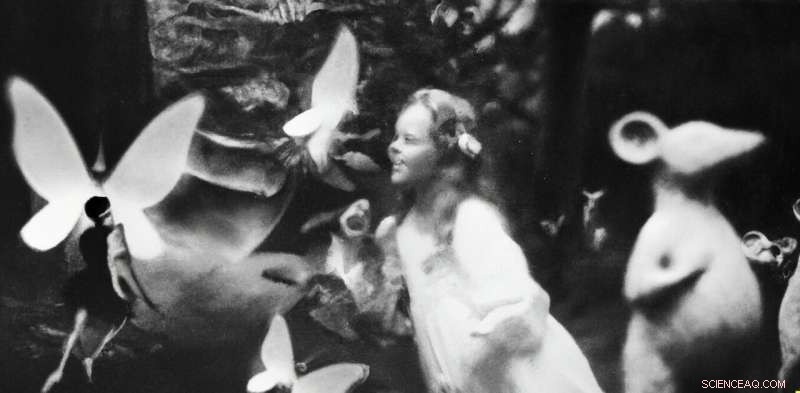
Krediet:Brendan Murphy, auteur verstrekt
Nepfotografie is niets nieuws. In de jaren 1910 werd de Britse auteur Arthur Conan Doyle op beroemde wijze misleid door twee schoolgaande zussen die foto's hadden gemaakt van elegante feeën die in hun tuin rondscharrelden.
De eerste van de vijf 'Cottingley Fairies'-foto's, gemaakt door Elsie Wright in 1917. Credit:Wikipedia
Tegenwoordig is het moeilijk te geloven dat deze foto's iemand voor de gek hadden kunnen houden, maar het was pas in de jaren tachtig dat een expert genaamd Geoffrey Crawley het lef had om zijn kennis van filmfotografie rechtstreeks toe te passen en het voor de hand liggende af te leiden.
De foto's waren nep, zoals later toegegeven door een van de zussen zelf.

In 1982 concludeerde Geoffrey Crawley dat de feeënfoto's nep waren. Zo ook deze. Krediet:Brendan Murphy, auteur verstrekt
Op jacht naar artefacten en gezond verstand
Digitale fotografie heeft een schat aan technieken geopend voor zowel fakers als detectives.
Bij forensisch onderzoek van verdachte afbeeldingen wordt tegenwoordig gezocht naar eigenschappen die inherent zijn aan digitale fotografie, zoals het onderzoeken van metadata die in de foto's zijn ingebed, het gebruik van software zoals Adobe Photoshop om vervormingen in afbeeldingen te corrigeren en het zoeken naar veelbetekenende tekenen van manipulatie, zoals regio's die worden gedupliceerd naar obscure originele kenmerken.
Soms zijn digitale bewerkingen te subtiel om te detecteren, maar komen ze in beeld wanneer we de manier aanpassen waarop lichte en donkere pixels worden verdeeld. In 2010 bracht NASA bijvoorbeeld een foto uit van de manen Dione en Titan van Saturnus. Het was op geen enkele manier nep, maar was schoongemaakt om verdwaalde artefacten te verwijderen - wat de aandacht trok van complottheoretici.
Nieuwsgierig zette ik de afbeelding in Photoshop. De onderstaande illustratie geeft ongeveer weer hoe dit eruit zag.
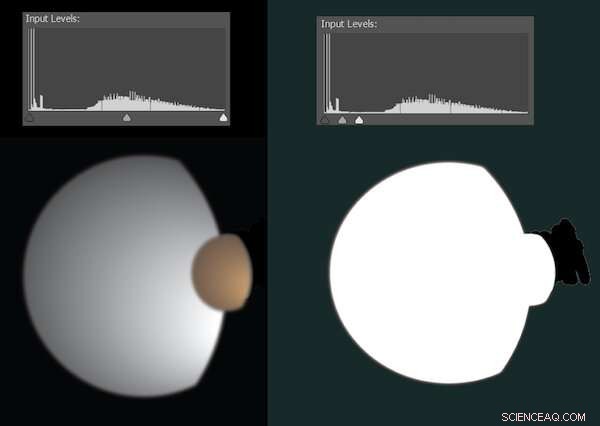
Een simulatie die laat zien hoe bewerkingen kunnen worden gedetecteerd wanneer de niveaus van licht en donker worden aangepast. Krediet:Brendan Murphy, auteur verstrekt
De meeste digitale foto's zijn in gecomprimeerde formaten zoals JPEG, afgeslankt door het verwijderen van veel van de informatie die door de camera is vastgelegd. Gestandaardiseerde algoritmen zorgen ervoor dat de verwijderde informatie een minimale zichtbare impact heeft, maar laat wel sporen achter.
De compressie van elk deel van een afbeelding hangt af van wat er in de afbeelding gebeurt en van de huidige camera-instellingen; wanneer een nep-afbeelding meerdere bronnen combineert, is het vaak mogelijk om dit te detecteren door een zorgvuldige analyse van de compressie-artefacten.
Sommige forensische methoden hebben weinig te maken met het formaat van een afbeelding, maar zijn in wezen visueel speurwerk. Is iedereen op de foto op dezelfde manier belicht? Zijn schaduwen en reflecties logisch? Staan oren en handen op de juiste plaatsen licht en schaduw? Wat wordt weerspiegeld in de ogen van mensen? Zouden alle lijnen en hoeken van de kamer kloppen als we de scène in 3D zouden modelleren?
Arthur Conan Doyle is misschien voor de gek gehouden door sprookjesfoto's, maar ik denk dat zijn creatie Sherlock Holmes zich thuis zou voelen in de wereld van forensische fotoanalyse.
Een nieuw tijdperk van kunstmatige intelligentie
De huidige explosie van afbeeldingen die wordt gecreëerd door tekst-naar-beeld kunstmatige intelligentie (AI)-tools is in veel opzichten ingrijpender dan de verschuiving van film naar digitale fotografie.
We kunnen nu elke gewenste afbeelding oproepen, gewoon door te typen. Deze afbeeldingen zijn geen frankenfoto's die zijn gemaakt door reeds bestaande klontjes pixels aan elkaar te knutselen. Het zijn geheel nieuwe afbeeldingen met de gespecificeerde inhoud, kwaliteit en stijl.
Tot voor kort waren de complexe neurale netwerken die werden gebruikt om deze beelden te genereren, beperkt beschikbaar voor het publiek. Dit veranderde op 23 augustus 2022, met de release voor het publiek van de open-source Stable Diffusion. Nu kan iedereen met een Nvidia grafische kaart op gaming-niveau in hun computer AI-beeldinhoud maken zonder dat er een onderzoekslaboratorium of zakelijke poortwachter bij hun activiteiten hoeft te zijn.
Dit heeft velen ertoe aangezet zich af te vragen:"kunnen we ooit nog geloven wat we online zien?" Dat hangt ervan af.
Tekst-naar-beeld AI haalt zijn intelligentie uit training:de analyse van een groot aantal afbeelding/bijschrift-paren. De sterke en zwakke punten van elk systeem zijn gedeeltelijk afgeleid van de beelden waarop het is getraind. Hier is een voorbeeld:zo ziet Stable Diffusion George Clooney zijn strijkwerk doen.

Dit is George Clooney die aan het strijken is... of niet? Krediet:Brendan Murphy, auteur verstrekt
Dit is verre van realistisch. Het enige wat Stable Diffusion hoeft te doen, is de informatie die het heeft geleerd, en hoewel het duidelijk is dat het George Clooney heeft gezien en die reeks letters kan koppelen aan de functies van de acteur, is het geen Clooney-expert.
Het zou echter veel meer foto's van mannen van middelbare leeftijd in het algemeen hebben gezien en verwerkt, dus laten we eens kijken wat er gebeurt als we in hetzelfde scenario om een generieke man van middelbare leeftijd vragen.

Generieke man van middelbare leeftijd doet zijn strijken. Krediet:Brendan Murphy, auteur verstrekt
Dit is een duidelijke verbetering, maar nog niet helemaal realistisch. Zoals altijd het geval is geweest, is de lastige geometrie van handen en oren een goede plek om naar tekenen van vervalsing te zoeken, hoewel we in dit medium eerder naar de ruimtelijke geometrie kijken dan naar de verhalen van onmogelijke verlichting.
Mogelijk zijn er nog andere aanwijzingen. Als we de kamer zorgvuldig zouden reconstrueren, zouden de hoeken dan vierkant zijn? Zouden de planken zinvol zijn? Een forensisch expert die gewend is digitale foto's te onderzoeken, zou daar waarschijnlijk een beroep op kunnen doen.
We kunnen onze ogen niet meer geloven
Als we de kennis van een tekst-naar-beeldsysteem uitbreiden, kan het nog beter. U kunt uw eigen beschreven foto's toevoegen als aanvulling op de bestaande training. Dit proces staat bekend als tekstuele inversie.
Onlangs heeft Google Dream Booth uitgebracht, een alternatieve, meer geavanceerde methode voor het injecteren van specifieke mensen, objecten of zelfs kunststijlen in tekst-naar-beeld AI-systemen.
Dit proces vereist zware hardware, maar de resultaten zijn verbluffend. Er is begonnen met het delen van geweldig werk op Reddit. Bekijk de foto's in de post hieronder die afbeeldingen tonen die in DreamBooth zijn geplaatst en realistische nepafbeeldingen van Stable Diffusion.
We kunnen onze ogen niet meer geloven, maar misschien kunnen we die van forensische experts voorlopig nog vertrouwen. Het is heel goed mogelijk dat toekomstige systemen opzettelijk kunnen worden getraind om ook hen voor de gek te houden.
We gaan snel een tijdperk in waarin perfecte foto's en zelfs video gemeengoed zullen zijn. De tijd zal leren hoe belangrijk dit zal zijn, maar in de tussentijd is het de moeite waard om de les van de Cottingley Fairy-foto's te onthouden - soms willen mensen gewoon geloven, zelfs in duidelijke vervalsingen.
 Hernieuwbare oplosmiddelen afgeleid van lignine verlagen het afval bij de productie van biobrandstoffen
Hernieuwbare oplosmiddelen afgeleid van lignine verlagen het afval bij de productie van biobrandstoffen- Opslag van thermische energie:materiaal absorbeert warmte als het smelt en geeft het weer af als het stolt
- Natuurkundigen houden toezicht op de vorming van hogere mangaansilicidefilms
- Was aan, wegsmelten
- Een nieuw proces voor volledig gebruik van zachthoutschors
- Nieuwe studie maakt regionale voorspelling van uranium in grondwater mogelijk
- Bavaria jongleert met steun voor diesel en schone stadslucht
- Planten die nicotine bevatten
- Plastic rommel veroorzaakt ramp op onbewoond eiland in de Stille Oceaan
- NASA voltooit onderzoeksvluchten om poolijs in kaart te brengen
Hoofdlijnen
- Internationale concurrentiebenchmarks metagenomics-software
- Urban Coopers-haviken overtreffen hun landelijke buren
- Ecosysteemherstel is een integraal onderdeel van het herstel van de mensheid van COVID-19
- Koloniekenmerken van E.Coli
- Waar vindt ademhaling plaats?
- Wat is de relatie tussen stikstofbasen en de genetische code?
- Nieuwe studie onthult mechanisme voor hoe ziekteverspreidende prionen van de ene soort naar de andere kunnen springen
- Rapport:meer dan 1.000 wilde paarden naar de slachtbank gestuurd
- Wanneer stopt het leven op aarde?






 Onderzoek naar de implicaties van sociale robots in religieuze contexten
Onderzoek naar de implicaties van sociale robots in religieuze contexten- Door nieuwe technologie kunnen belangrijke metalen efficiënter worden gemaakt
- Hoe Dyson Spheres werken
- Wat veroorzaakt de dag /nacht-cyclus op aarde?
- Vissenseks zo luid dat dolfijnen doof kunnen worden
- Eerste leeftijdskaart van het hart van de Melkweg
- Een hobbel op een perceel van het Chandra-röntgenobservatorium onthult een overmaat aan röntgenstralen, hint naar donkere materie
- Startup richt zich op slaperig rijden met het volgende generatie veiligheidssysteem voor bestuurders
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
