Wetenschap
Google Duo-audioboost laat je niet aan de telefoon hangen
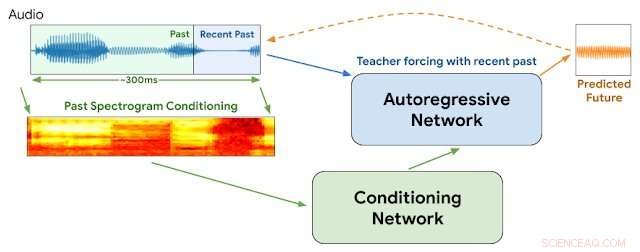
WaveNetEQ-architectuur. Tijdens gevolgtrekking, we "warmen" het autoregressieve netwerk op door de leraar te forceren met de meest recente audio. Daarna, het model wordt geleverd met een eigen output als input voor de volgende stap. Een MEL-spectrogram van een langer audiogedeelte wordt gebruikt als invoer voor het conditioneringsnetwerk. Krediet:Google
"Het is goed om je stem te horen, je weet dat het zo lang geleden is
Als ik je telefoontjes niet krijg, dan gaat alles mis...
Je stem over de lijn geeft me een vreemd gevoel"
— Blondje, "Opknoping aan de telefoon"
1978, Debbie Harry stuwde haar new wave-band Blondie naar de top van de hitlijsten met een klaaglijk verhaal over het verlangen om de stem van haar vriend van ver te horen en erop aan te dringen dat hij haar niet 'aan de telefoon liet hangen'.
Maar de vragen rijzen:wat als het 2020 was en ze sprak via VOIP met intermitterende pakketverliezen, audio jitter, netwerkvertragingen en niet-opeenvolgende pakkettransmissies?
We zullen het nooit weten.
Maar Google heeft deze week details aangekondigd van een nieuwe technologie voor zijn populaire Duo-spraak- en video-app die zal helpen zorgen voor soepelere spraakoverdrachten en tijdelijke hiaten die soms internetgebaseerde verbindingen belemmeren, te verminderen. We zouden graag denken dat Debbie het goed zou vinden.
We hebben allemaal te maken gehad met jitter op internet. Het treedt op wanneer een of meer pakketten instructies die een stroom audio-instructies omvatten, worden vertraagd of in de verkeerde volgorde tussen beller en luisteraar worden geschud. Methoden die gebruikmaken van buffers voor spraakpakketten en kunstmatige intelligentie kunnen over het algemeen jitter van 20 milliseconden of minder verminderen. Maar de onderbrekingen worden meer merkbaar wanneer de ontbrekende pakketten oplopen tot 60 milliseconden en meer.
Google zegt dat vrijwel alle oproepen verlies van datapakketten ervaren:een vijfde van alle oproepen verliest 3 procent van hun audio en een tiende verliest 8 procent.
Deze week, Google-onderzoekers van de DeepMind-divisie meldden dat ze een programma met de naam WaveNetEQ zijn gaan gebruiken om deze problemen aan te pakken. Het algoritme blinkt uit in het opvullen van tijdelijke geluidshiaten met gesynthetiseerde maar natuurlijk klinkende spraakelementen. Vertrouwend op een omvangrijke bibliotheek met spraakgegevens, WaveNetEQ vult geluidshiaten op tot 120 milliseconden. Dergelijke geluidsbitswaps worden packet loss concealments (PLC) genoemd.
"WaveNetEQ is een generatief model gebaseerd op DeepMind's WaveRNN-technologie, " Google's AI Blog meldde 1 april "die is getraind met behulp van een groot corpus aan spraakgegevens om op realistische wijze korte spraaksegmenten voort te zetten, waardoor het de ruwe golfvorm van ontbrekende spraak volledig kan synthetiseren."
Het programma analyseerde geluiden van 100 sprekers in 48 talen, inzoomen op "de kenmerken van menselijke spraak in het algemeen, in plaats van de eigenschappen van een specifieke taal, ’ verklaarde het rapport.
In aanvulling, geluidsanalyse is getest in omgevingen met een grote verscheidenheid aan achtergrondgeluiden om nauwkeurige herkenning door luidsprekers op drukke stadstrottoirs te garanderen, treinstations of cafetaria's.
Alle WaveNetEQ-verwerking moet op de telefoon van de ontvanger worden uitgevoerd, zodat de versleutelingsservices niet worden aangetast. Maar de extra vraag naar verwerkingssnelheid is minimaal, Google stelt. WaveNetEQ is "snel genoeg om op een telefoon te draaien, terwijl het nog steeds state-of-the-art audiokwaliteit en een natuurlijker klinkende PLC biedt dan andere systemen die momenteel in gebruik zijn."
Geluidsvoorbeelden die audiojitter en verbetering met WabeNetEQ illustreren, worden gepost op het Google Blog-rapport.
© 2020 Wetenschap X Netwerk
 Een veiligere manier om bacteriën in te zetten als omgevingssensoren
Een veiligere manier om bacteriën in te zetten als omgevingssensoren- Nanostructuren van elektrokatalysatoren sleutel tot verbeterde brandstofcellen, elektrolyzers
- Zuurstof geven aan de kwestie van luchtkwaliteit
- Wegenkaart schetst hindernissen bij de ontwikkeling van kathodes van de volgende generatie voor het aandrijven van elektrische voertuigen
- Wetenschappers ontcijferen het belangrijkste principe achter de reactie van metallo-enzymen
- Satellietbeelden onthullen dat de aarde meer bossen heeft dan eerder werd gedacht
- Wat voor soort wolken zijn regenwolken?
- NASA vangt degeneratie van Aletta op in een resterend lagedrukgebied
- NASA kijkt naar Kalmaegis-waterdampconcentratie bij tropische depressie
- De Mississippi-rivier heeft veel bijnamen. Nu heeft het een nieuwe:Amerika's meest bedreigde rivier.
Hoofdlijnen
- Een eenvoudig diercelmodel maken
- Zijn mannen gewelddadiger dan vrouwen?
- Zelfs als je nog niet weet dat je ziek bent, je gezicht zal je verraden
- Mongoolse microfossielen wijzen op de opkomst van dieren op aarde
- Hoe voeden bacteriën?
- Welke pakketten materialen van het endoplasmatisch reticulum en verzendt ze naar andere delen van de cel?
- eDNA-tool detecteert invasieve mosselen voordat ze hinderlijk worden
- Bij-nabootsende kaalvleugelmot zoemt na 130 jaar weer tot leven
- Hoe meet je geluk?
- Spotify schrapt R. Kelly-muziek uit afspeellijsten, citeert nieuw beleid

- Verbeterde videokwaliteit ondanks slechte netwerkomstandigheden

- Onderzoekers suggereren dat medische AI-systemen kwetsbaar kunnen zijn voor vijandige aanvallen

- Tech show biedt grote en flitsende, dichtbij en (zeer) persoonlijk

- Kwarts recyclen uit mijnafval


 Nieuwe methodologie helpt bij het bestuderen van veelbelovende gerichte steigers voor medicijnafgifte
Nieuwe methodologie helpt bij het bestuderen van veelbelovende gerichte steigers voor medicijnafgifte- Door staking getroffen British Airways vliegt in turbulentie
- Een techniek om de fysieke interactie in luchtrobots te verbeteren
- Het installeren van zonnepanelen op landbouwgronden maximaliseert hun efficiëntie, nieuwe studie toont
- Wat is het verschil tussen eindige wiskunde en pre-calculus?
- Total onthult belangrijke offshore gasvondst in Zuid-Afrika
- Wiskundig mysterie van oud Babylonisch kleitablet opgelost
- Ingenieurs verhogen de output van het zonne-ontziltingssysteem met 50%
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | French | Spanish |

-
Wetenschap © https://nl.scienceaq.com
