Wetenschap
Google introduceert uitgebreide realtime spraakvertaling
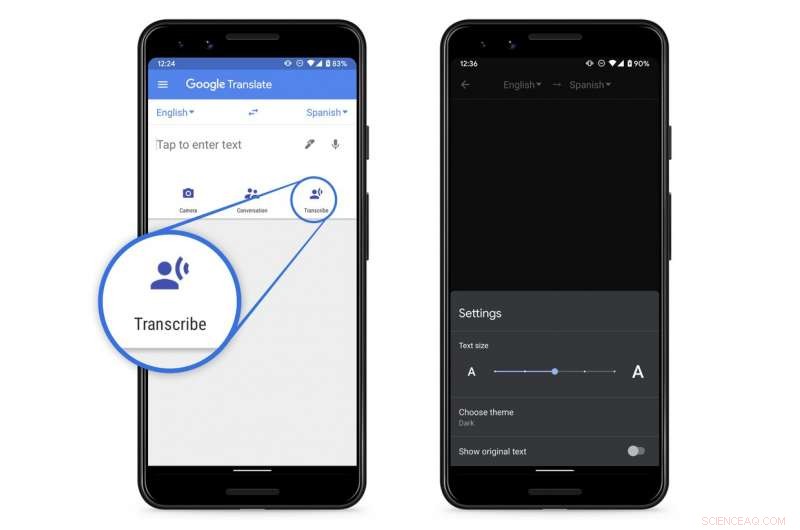
Krediet:Google
Google heeft een nieuwe realtime transcriptiefunctie aangekondigd voor zijn gratis Translate-app voor Android-telefoons. Een IOS-versie is gepland voor de toekomst, zegt het bedrijf.
Met deze functie kunnen gebruikers onmiddellijke tekstvertalingen krijgen van lopende toespraken, lezingen of monologen in een van de acht talen, inclusief Engels.
Momenteel, Met Translate kunnen alleen relatief korte spraakfragmenten worden omgezet.
De enige vereisten zijn dat er slechts één spreker tegelijk aan het woord is in een stille kamer (andere stemmen of geluiden zullen de nauwkeurigheid verminderen) en een internetverbinding, nodig voor interactie met de cloudgebaseerde Tensor Processing Units van Google.
De uitrol begint vandaag (18 maart) en zou tegen het einde van de week voor alle gebruikers beschikbaar moeten zijn in de Google Play Store.
In gespreksmodus, met de app kunnen gebruikers heen en weer praten met iemand die een andere taal spreekt.
Naast Engels, vertalingen zijn beschikbaar in het Frans, Duitse, Hindi, Portugees, Russisch, Spaans en Thais.
De app werkt ook met het afspelen van vooraf opgenomen audio. Maar Google zegt dat directe digitale vertaling van geüploade audiobestanden nog niet beschikbaar is.
De aankondiging van deze week herinnert ons eraan hoe ver we zijn gekomen sinds de begindagen van digitale spraakherkenning. Bell Laboratories debuteerde in 1952 met zijn futuristische "Audrey"-systeem dat de gesproken cijfers 0-9 herkende. Tien jaar later werd een gigantische stap gezet toen IBM de "Shoebox" toonde op de Wereldtentoonstelling van 1962 - hij kon maar liefst 16 woorden herkennen.
Vijf jaar lang, in de jaren zeventig, spraakherkenning kreeg een enorme boost van het Amerikaanse leger. Het ministerie van Defensie onderschreef enorme onderzoeksprojecten naar spraakherkenning, inclusief Carnegie-Mellon's "Harpy" Speech Understanding Research (SUR)-initiatief, die een herkenningsvocabulaire van meer dan 1 heeft opgebouwd 011 woorden. Dat programma introduceerde met name het concept van uitspraakpatronen en waarschijnlijkheid voor de eerste keer, waardoor het vermogen om verschillende spraakwijzen te herkennen aanzienlijk wordt verbeterd.
De jaren tachtig brachten steeds grotere vorderingen op het gebied van woorddetectie, met onderzoekers die kanstheorie toepassen op onbekende geluiden. Het programma van techgigant IBM breidde de erkenning uit tot 5, 000 woorden. Maar het decennium wordt misschien het best herinnerd voor de introductie van 's werelds eerste pratende pop, "Jullie, " dat begreep toespraak. Een advertentiecampagne verklaarde:"Eindelijk, de pop die je begrijpt."
Dragon bracht spraakherkenning naar de massa in de jaren negentig, met zijn eerste grotendeels nauwkeurige maar nog steeds buggy consumentenproduct geprijsd op "slechts" $ 9, 000. Tegen het einde van het decennium, het sterk verbeterde Dragon NaturallySpeaking-programma, die voor het eerst geen pauzes nodig hadden tussen elk gesproken woord, was beschikbaar voor consumenten voor ongeveer $ 700.
Tegenwoordig hebben we Siri en Alexa en andere gratis en goedkope mobiele apps waarmee we een routebeschrijving kunnen opvragen, eten bestellen, koop huishoudelijke artikelen en typ gesproken tekst in e-mails en tekstverwerkingsdocumenten, die allemaal spraakherkenning hebben uitgebreid tot punten die nog niet zo lang geleden ondenkbaar waren.
Met de nieuwste ontwikkelingen die beschikbaar zijn voor miljoenen gebruikers met draagbare apparaten, Harpij, Audrey, Julie zou waarschijnlijk sprakeloos zijn.
© 2020 Wetenschap X Netwerk
 Keramische membranen scheiden kleine organische moleculen met een molecuulmassa van 200 Dalton
Keramische membranen scheiden kleine organische moleculen met een molecuulmassa van 200 Dalton- Welke handschoenen moeten worden gebruikt voor het omgaan met aceton?
- Petrovite:wetenschappers ontdekken een nieuw mineraal in Kamtsjatka
- Chemici ontwikkelen nieuw materiaal voor het scheiden van kooldioxide uit industriële afvalgassen
- Optisch pincet met aerosol verbetert het begrip van deeltjes in de lucht
- Bescherming voor volle zee is cruciaal om kwetsbare kustgemeenschappen te beschermen - nieuw onderzoek
- Vliegtuigen helpen bij het bestrijden van bosbranden in Californië terwijl de rook optrekt
- Rapport beveelt een nieuw raamwerk aan voor het schatten van de sociale kosten van koolstof
- Hoe Tweet-A-Watt werkt
- Het dekken van de vuurterreur in het verloren paradijs van Californië
Hoofdlijnen
- Er is een genetische reden waarom Labrador Retrievers geobsedeerd zijn door voedsel
- Sardines nemen ons mee naar de bronnen van biodiversiteit in de Amazone-rivier
- Haaienbioloog werkt samen met ruimtevaartingenieur om het gedrag van oceanische wittips te ontdekken
- Gestresste stokstaartjes helpen minder snel groep
- Timing van migratie verandert voor zangvogels aan de Pacifische kust
- Boek beschrijft alle 451 families van bloeiende planten, varens, lycopoden en naaktzadigen
- Namen van DNA-strengen
- Zijn mensen het slimste dier?
- Samengestelde ogen een continu kenmerk van evolutie






 Wat als we geen maan hadden?
Wat als we geen maan hadden? - Hier is waarom uw telefoon stopt met werken in de kou
- Dataschandaal bedreigt Zuckerberg-visie voor Facebook
- Campbell,
- Bedrijfsleiders, wetgevers naar Amazon:kom alsjeblieft terug naar NY
- Wat is Absolute nul?
- Nieuwe manier om RNA te zien kan ziekteverwekkers helpen bestrijden
- Nieuwe waarnemingen bevestigen de al lang bestaande theorie dat sterren overvloedige producenten van zware elementen zijn
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
