Wetenschap
Hoe verwijderen we vooroordelen in AI-systemen? Begin door ze selectief geheugenverlies te leren
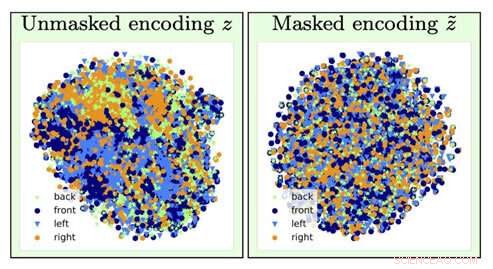
Voor het identificeren van het type stoelafbeelding, informatie over de oriëntatie van de stoel (een hinderlijke factor) gaat verloren door de vergeetoperatie (van de linker visualisatie naar rechts gaan). Krediet:Universiteit van Zuid-Californië
Stelt u zich eens voor dat u de volgende keer dat u een lening aanvraagt, een computeralgoritme bepaalt dat u een hoger tarief moet betalen, voornamelijk op basis van uw ras, geslacht of postcode.
Nutsvoorzieningen, stel je voor dat het mogelijk zou zijn om een AI-deep learning-model te trainen om die onderliggende gegevens te analyseren door geheugenverlies te veroorzaken:het vergeet bepaalde gegevens en richt zich alleen op andere.
Als je denkt dat dit klinkt als de computerwetenschappersversie van "The Eternal Sunshine of the Spotless Mind, " zou je mooi zijn. En dankzij AI-onderzoekers van het Information Sciences Institute (ISI) van het USC, dit begrip, vijandig vergeten genoemd, is nu een echt mechanisme.
Het belang van het aanpakken en wegnemen van vooroordelen in AI wordt steeds belangrijker naarmate AI steeds vaker voorkomt in ons dagelijks leven, merkte Ayush Jaiswal op, hoofdauteur van het papier en Ph.D. kandidaat aan de USC Viterbi School of Engineering.
"AI en, specifieker, machine learning-modellen erven vooroordelen die aanwezig zijn in de gegevens waarop ze zijn getraind en zijn geneigd om die vooroordelen zelfs te versterken, " legde hij uit. "AI wordt gebruikt om verschillende real-life beslissingen te nemen die ons allemaal aangaan, [zoals] het bepalen van kredietlimieten, het goedkeuren van leningen, sollicitaties scoren, enz. Als, bijvoorbeeld, modellen voor het nemen van deze beslissingen worden blind getraind op historische gegevens zonder te controleren op vooroordelen, ze zouden leren om individuen die tot historisch achtergestelde bevolkingsgroepen behoren, oneerlijk te behandelen, zoals vrouwen en mensen van kleur."
Het onderzoek werd geleid door Wael AbdAlmageed, onderzoeksteamleider bij ISI en een universitair hoofddocent onderzoek bij USC Viterbi's Ming Hsieh Department of Electrical and Computer Engineering, en wetenschappelijk universitair hoofddocent Greg Ver Steeg, evenals Premkumar Natarajan, onderzoekshoogleraar informatica en uitvoerend directeur van ISI (met verlof). Onder hun leiding, Jaiswal en co-auteur Daniel Moyer, doctoraat, ontwikkelde de vijandige vergeetbenadering, die deep learning-modellen leert om specifieke, ongewenste gegevensfactoren zodat de resultaten die ze produceren onbevooroordeeld en nauwkeuriger zijn.
Het onderzoeksrapport, getiteld "Invariante representaties door middel van vijandig vergeten, " werd gepresenteerd op de Association for the Advancement for Artificial Intelligence-conferentie in New York City op 10 februari, 2020.
Overlast en neurale netwerken
Deep learning is een kerncomponent van AI en kan computers leren hoe ze correlaties kunnen vinden en voorspellingen kunnen doen met gegevens, helpen bij het identificeren van mensen of objecten, bijvoorbeeld. Modellen zoeken in wezen naar associaties tussen verschillende kenmerken binnen gegevens en het doel dat het zou moeten voorspellen. Als een model de opdracht kreeg om een specifieke persoon uit een groep te vinden, het zou gelaatstrekken analyseren om iedereen uit elkaar te houden en vervolgens de beoogde persoon te identificeren. Eenvoudig, Rechtsaf?
Helaas, dingen lopen niet altijd zo soepel, omdat het model dingen kan leren die contra-intuïtief lijken. Het kan uw identiteit associëren met een bepaalde achtergrond of verlichtingsopstelling en u niet kunnen identificeren als de verlichting of achtergrond is gewijzigd; het zou je handschrift kunnen associëren met een bepaald woord, en in de war raken als hetzelfde woord in het handschrift van iemand anders is geschreven. Deze toepasselijke overlastfactoren hebben niets te maken met de taak die u probeert uit te voeren, en ze verkeerd associëren met het voorspellingsdoel kan zelfs gevaarlijk worden.
Modellen kunnen ook vooroordelen in gegevens leren die gecorreleerd zijn met het voorspellingsdoel maar ongewenst zijn. Bijvoorbeeld, in taken die worden uitgevoerd door modellen met historisch verzamelde sociaaleconomische gegevens, zoals het bepalen van kredietscores, kredietlijnen, en geschiktheid voor leningen, het model kan valse voorspellingen doen en biases tonen door verbanden te leggen tussen de biases en het voorspellingsdoel. Het kan tot de conclusie komen dat, aangezien het de gegevens van een vrouw analyseert, ze moet een lage kredietscore hebben; omdat het de gegevens van een gekleurde persoon analyseert, ze mogen niet in aanmerking komen voor een lening. Er is geen gebrek aan verhalen over banken die onder vuur komen te liggen vanwege de bevooroordeelde beslissingen van hun algoritmen over hoeveel ze mensen in rekening brengen die leningen hebben afgesloten op basis van hun ras, geslacht, en onderwijs, zelfs als ze exact hetzelfde kredietprofiel hebben als iemand in een meer sociaal bevoorrecht bevolkingssegment.
Zoals Jaiswal uitlegde, het vijandige vergeetmechanisme "repareert" neurale netwerken, Dit zijn krachtige deep learning-modellen die doelen uit data leren voorspellen. De kredietlimiet die u kreeg op die nieuwe creditcard waarvoor u zich aanmeldde? Een neuraal netwerk heeft waarschijnlijk uw financiële gegevens geanalyseerd om met dat aantal te komen.
Het onderzoeksteam ontwikkelde het vijandige vergeetmechanisme zodat het eerst het neurale netwerk kon trainen om alle onderliggende aspecten van de gegevens die het analyseert weer te geven en vervolgens specifieke vooroordelen te vergeten. In het voorbeeld van de creditcardlimiet, dat zou betekenen dat het mechanisme het algoritme van de bank zou kunnen leren om de limiet te voorspellen terwijl het vergeet, of onveranderlijk zijn, de specifieke gegevens met betrekking tot geslacht of ras. "[Het mechanisme] kan worden gebruikt om neurale netwerken te trainen om invariant te zijn voor bekende vooroordelen in trainingsdatasets, "Zei Jaiswal. "Dit, beurtelings, zou resulteren in getrainde modellen die niet bevooroordeeld zouden zijn bij het nemen van beslissingen."
Deep learning-algoritmen zijn geweldig in het leren van dingen, maar het is moeilijker om ervoor te zorgen dat de algoritmen bepaalde dingen niet leren. Het ontwikkelen van algoritmen is een zeer datagedreven proces, en gegevens hebben de neiging om vooroordelen te bevatten.
Maar kunnen we niet gewoon alle gegevens over ras, geslacht, en onderwijs om de vooroordelen weg te nemen?
Niet helemaal. Er zijn veel andere gegevensfactoren die verband houden met deze gevoelige factoren die belangrijk zijn voor algoritmen om te analyseren. De sleutel, zoals de ISI AI-onderzoekers ontdekten, voegt beperkingen toe aan het trainingsproces van het model om het model te dwingen voorspellingen te doen terwijl het in wezen invariant is voor specifieke gegevensfactoren, selectief vergeten.
Vooroordelen bestrijden
Invariantie verwijst naar het vermogen om een specifiek object te identificeren, zelfs als het uiterlijk (d.w.z. gegevens) op de een of andere manier is gewijzigd, en Jaiswal en zijn collega's begonnen na te denken over hoe dit concept kan worden toegepast om algoritmen te verbeteren. "Mijn co-auteur, Dan [Moyer], en ik kwam eigenlijk met dit idee enigszins natuurlijk op basis van onze eerdere ervaringen op het gebied van invariante representatie leren, " merkte hij op. Maar het concept uitwerken was geen eenvoudige taak. "De meest uitdagende onderdelen waren [de] rigoureuze vergelijking met eerdere werken in dit domein op een breed scala aan datasets (waarvoor een zeer groot aantal experimenten moest worden uitgevoerd) en [ het ontwikkelen van] een theoretische analyse van het vergeetproces, " hij zei.
Het mechanisme voor het vergeten van tegenstanders kan ook worden gebruikt om het genereren van inhoud op verschillende gebieden te verbeteren. "Het ontluikende veld van eerlijke machine learning kijkt naar manieren om vooringenomenheid in algoritmische besluitvorming op basis van consumentengegevens te verminderen, "Zei Ver Steeg. "Een meer speculatief gebied betreft onderzoek naar het gebruik van AI om inhoud te genereren, waaronder pogingen tot boeken, muziek, kunst, spellen, en zelfs recepten. Om contentgeneratie te laten slagen, we hebben nieuwe manieren nodig om neurale netwerkrepresentaties te controleren en te manipuleren en het vergeetmechanisme zou een manier kunnen zijn om dat te doen."
Dus hoe komen vooroordelen überhaupt in het model naar voren?
De meeste modellen gebruiken historische gegevens, die, helaas, kunnen grotendeels bevooroordeeld zijn ten opzichte van traditioneel gemarginaliseerde gemeenschappen zoals vrouwen, minderheden, zelfs bepaalde postcodes. Het is kostbaar en omslachtig om gegevens te verzamelen, dus wetenschappers hebben de neiging om hun toevlucht te nemen tot gegevens die al bestaan en op basis daarvan modellen te trainen, zo komen vooroordelen in beeld.
Het goede nieuws is dat deze vooroordelen worden erkend, en hoewel het probleem nog lang niet is opgelost, Er worden stappen gezet om deze problemen te begrijpen en aan te pakken. "
Bepalen welke factoren als irrelevant of bevooroordeeld moeten worden beschouwd, worden gedaan door domeinexperts en op basis van statistische analyse. "Tot dusver, invariantie is meestal gebruikt om factoren te verwijderen die algemeen als ongewenst/irrelevant worden beschouwd binnen de onderzoeksgemeenschap op basis van statistisch bewijs, ' verklaarde Jaiswal.
Echter, aangezien onderzoekers bepalen wat niet relevant of bevooroordeeld is, er kan een mogelijkheid zijn dat die bepalingen zelf in vooroordelen veranderen. Dit is een factor waar onderzoekers ook mee bezig zijn. "Uitzoeken welke factoren je moet vergeten is een kritiek probleem dat gemakkelijk kan leiden tot onbedoelde gevolgen, " merkte Ver Steeg op. "Een recent stuk van Nature over eerlijk leren wijst erop dat we de mechanismen achter discriminatie moeten begrijpen als we algoritmische oplossingen correct willen specificeren."
De verwerking van menselijke informatie is uiterst ingewikkeld, en het vijandige vergeetmechanisme helpt ons een stap dichter bij de ontwikkeling van AI te komen die kan denken zoals wij. Zoals Ver Steeg opmerkte, mensen hebben de neiging om verschillende vormen van informatie over de wereld om hen heen te scheiden door instinctieve algoritmen om hetzelfde te doen, is de uitdaging die voor ons ligt.
"Als iemand voor je auto stapt, je slaat op de pauzes en de slogan op hun shirt komt niet eens in je op, " zei Ver Steeg. "Maar als je die persoon in een sociale context tegenkomt, die informatie kan relevant zijn en u helpen een gesprek aan te knopen. voor AI, verschillende soorten informatie worden allemaal door elkaar gehusseld. Als we neurale netwerken kunnen leren om concepten te scheiden die nuttig zijn voor verschillende taken, we hopen dat het AI leidt tot een menselijker begrip van de wereld."
De verwerking van menselijke informatie is uiterst ingewikkeld, en het vijandige vergeetmechanisme helpt ons een stap dichter bij de ontwikkeling van AI te komen die kan denken zoals wij. Zoals Ver Steeg opmerkte, mensen hebben de neiging om verschillende vormen van informatie over de wereld om hen heen instinctief te scheiden - het is de uitdaging om algoritmen hetzelfde te laten doen.
"Als iemand voor je auto stapt, je slaat op de pauzes en de slogan op hun shirt komt niet eens in je op, " zei Ver Steeg. "Maar als je die persoon in een sociale context tegenkomt, die informatie kan relevant zijn en u helpen een gesprek aan te knopen. voor AI, verschillende soorten informatie worden allemaal door elkaar gehusseld. Als we neurale netwerken kunnen leren om concepten te scheiden die nuttig zijn voor verschillende taken, we hopen dat het AI leidt tot een menselijker begrip van de wereld."
 Ontbossing, erosie verergert kwikpieken in de buurt van Peruaanse goudwinning
Ontbossing, erosie verergert kwikpieken in de buurt van Peruaanse goudwinning- VN-chef waarschuwt voor point of no return op klimaatverandering
- NASA mobiliseert om te helpen bij de brandbestrijding in Californië
- Klimaatverandering vraagt om een frisse benadering van waterproblemen
- Ongelijkheid in luchtkwaliteit aanpakken
Hoofdlijnen
- nieuwe ontdekking, meer bijen markeren Michigans eerst, volledige bijentelling
- EU-handelsverbod verlaagt wereldhandel in wilde vogels met 90 procent
- De straal van de aarde vinden
- Nieuwe soorten mariene spin verschijnen bij eb om wetenschappers aan Bob Marley te herinneren
- Drie nieuwe soorten zoantharen beschreven vanaf koraalriffen in de Indo-Pacific
- Parasieten en gastheren kunnen anders reageren op een warmere wereld
- Een 3D-model plantencel maken zonder voedsel
- Wat is een eencellige eukaryoot?
- Nieuwe slangensoort verstopt zich in het volle zicht
- Cathay Pacific beboet door Britse waakhond voor massale datalek

- SLAP:gelijktijdige lokalisatie en planning voor autonome robots
- Conditiebewaking en data-analyse in de cloud

- Ontwikkeling van zeer gevoelige diode, zet microgolven om in elektriciteit
- Facebook zegt dat het miljoenen onversleutelde Instagram-wachtwoorden heeft opgeslagen (update)


 Facebook gevangen in een verkiezingsbeveiliging Catch-22
Facebook gevangen in een verkiezingsbeveiliging Catch-22- Wat zijn de acht fasen van de maan in bestelling?
- Röntgenexperimenten dragen bij aan studies van een medicijn dat nu is goedgekeurd om tuberculose te bestrijden
- Onder het zee-ijs, aanschouw de oude Arctische kwallen
- Man beschuldigd van hacken netwerk ziekenhuis veroordeeld
- Aardbewoners en astronauten kletsen wat, via hamradio
- Stortplaatsen versus Incinerators
- Projecthotspot
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
