Wetenschap
Naarmate de natuurlijke taalverwerkingstechnieken verbeteren, suggesties worden steeds sneller en relevanter
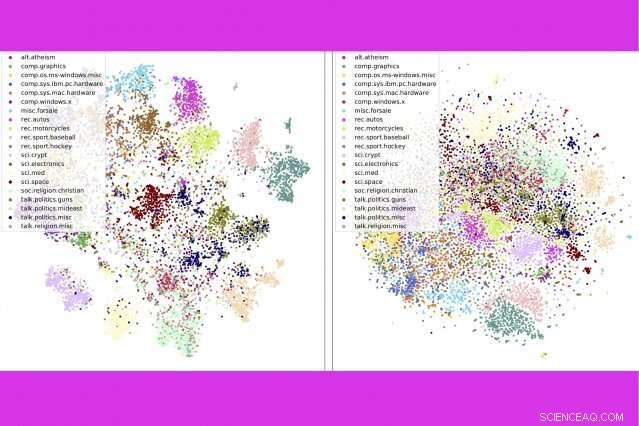
In een nieuwe studie, onderzoekers van MIT en IBM combineren drie populaire tekstanalysetools:onderwerpmodellering, woord inbeddingen, en optimaal transport — om duizenden documenten per seconde te vergelijken. Hier, ze laten zien dat hun methode (links) nieuwsgroepberichten per categorie strakker clustert dan een concurrerende methode. Krediet:Massachusetts Institute of Technology
Met miljarden boeken, nieuwsverhalen, en documenten online, er is nooit een beter moment geweest om te lezen - als je tijd hebt om alle opties door te spitten. "Er is een hoop tekst op internet, " zegt Justin Salomo, een assistent-professor aan het MIT. "Alles om door al dat materiaal heen te snijden, is buitengewoon nuttig."
Met het MIT-IBM Watson AI Lab en zijn Geometric Data Processing Group bij MIT, Solomon presenteerde onlangs een nieuwe techniek voor het doorsnijden van enorme hoeveelheden tekst op de Conference on Neural Information Processing Systems (NeurIPS). Hun methode combineert drie populaire tekstanalysetools:onderwerpmodellering, woord inbeddingen, en optimaal transport – om beter, snellere resultaten dan concurrerende methoden op een populaire benchmark voor het classificeren van documenten.
Als een algoritme weet wat je vroeger leuk vond, het kan de miljoenen mogelijkheden aftasten voor iets soortgelijks. Naarmate de natuurlijke taalverwerkingstechnieken verbeteren, die "die je misschien ook leuk vindt"-suggesties worden sneller en relevanter.
In de methode gepresenteerd op NeurIPS, een algoritme vat een verzameling samen van, zeggen, boeken, in onderwerpen op basis van veelgebruikte woorden in de collectie. Het verdeelt vervolgens elk boek in zijn vijf tot 15 belangrijkste onderwerpen, met een schatting van hoeveel elk onderwerp bijdraagt aan het boek in het algemeen.
Om boeken te vergelijken, gebruiken de onderzoekers twee andere tools:woordinbeddingen, een techniek die woorden omzet in lijsten met getallen om hun gelijkenis in populair gebruik weer te geven, en optimaal vervoer, een raamwerk voor het berekenen van de meest efficiënte manier om objecten - of gegevenspunten - tussen meerdere bestemmingen te verplaatsen.
Woordinbeddingen maken het mogelijk om optimaal transport dubbel te benutten:eerst onderwerpen binnen de collectie als geheel vergelijken, en dan, binnen elk paar boeken, om te meten hoe nauw gemeenschappelijke thema's elkaar overlappen.
De techniek werkt vooral goed bij het scannen van grote collecties boeken en lange documenten. In de studie, de onderzoekers geven het voorbeeld van Frank Stocktons "The Great War Syndicate, een 19e-eeuwse Amerikaanse roman die anticipeerde op de opkomst van kernwapens. Als u op zoek bent naar een soortgelijk boek, een onderwerpmodel zou helpen om de dominante thema's te identificeren die met andere boeken worden gedeeld - in dit geval nautisch, elementair, en krijgshaftig.
Maar een onderwerpmodel alleen zou Thomas Huxley's lezing uit 1863 niet identificeren, "De vroegere toestand van de organische natuur, " als een goede match. De schrijver was een voorvechter van Charles Darwin's evolutietheorie, en zijn lezing, doorspekt met vermeldingen van fossielen en sedimentatie, weerspiegelde opkomende ideeën over geologie. Wanneer de thema's in Huxley's lezing worden afgestemd op de roman van Stockton via optimaal transport, enkele horizontale motieven komen naar voren:de geografie van Huxley, flora fauna, en kennisthema's sluiten nauw aan bij de nautische, elementair, en krijgsthema's, respectievelijk.
Boeken modelleren door hun representatieve onderwerpen, in plaats van afzonderlijke woorden, maakt vergelijkingen op hoog niveau mogelijk. "Als je iemand vraagt om twee boeken te vergelijken, ze breken ze allemaal op in gemakkelijk te begrijpen concepten, en vergelijk dan de concepten, ", zegt de hoofdauteur van de studie, Mikhail Yurochkin, een onderzoeker bij IBM.
Het resultaat is sneller, nauwkeurigere vergelijkingen, blijkt uit de studie. De onderzoekers vergeleken 1, 720 paar boeken in de Gutenberg Project-dataset in één seconde - meer dan 800 keer sneller dan de op één na beste methode.
De techniek is ook beter in het nauwkeurig sorteren van documenten dan concurrerende methoden, bijvoorbeeld boeken in de Gutenberg-dataset groeperen op auteur, productrecensies op Amazon per afdeling, en BBC sportverhalen per sport. In een reeks visualisaties, de auteurs laten zien dat hun methode documenten netjes per type clustert.
Naast het snel en nauwkeurig categoriseren van documenten, de methode biedt een kijkje in het besluitvormingsproces van het model. Via de lijst met onderwerpen die verschijnen, gebruikers kunnen zien waarom het model een document aanbeveelt.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.

Hoofdlijnen
- Een nieuwe manier om metabolic engineering te doen
- Hoe wetenschappers ons hebben gered van de ineenstorting van de sint-jakobsschelp
- Wat is de Marshmallow-test en kunnen dieren deze doorstaan?
- Het belang van diffusie in organismen
- Hoe maak je een DNA-model met ijslollystokjes
- Race om Indonesische krokodil te redden die is getroffen door een bandenketting
- Wat zijn drie dingen die bepalen of een molecuul in een celmembraan kan diffunderen?
- Wat is het verschil tussen NADH en NADPH?
- Ecologische niche: definitie, soorten, belang en voorbeelden
- Noise cancelling device halveert geluidsoverlast door open ramen

- De technologie van Hyundai zal de stilte in de auto naar een hoger niveau tillen

- Expert bespreekt de verkeersimpact van Uber, Lyft

- Volkswagen gaat 3 Duitse fabrieken wijden aan push voor elektrische auto's

- Een nieuwe op machine learning gebaseerde intentiedetectiemethode met behulp van first-person-view camera voor Exo Glove Poly II

 Panzerkampfwagens I en II
Panzerkampfwagens I en II - Kleine klassen verkleinen prestatiekloven in de wetenschap
- Grote overstromingen in Manilla terwijl tyfoon Filipijnen teistert
- Naarmate veganistisch activisme groeit, politici willen de agrarische sector beschermen, restauranthouders
- Waarom is het heet aan de evenaar Maar koud aan de polen?
- Onderzoek levert nieuwe aanwijzingen op voor de oorsprong van Tamu Massif
- Video:Pine Island Glacier spawnt biggen
- Helpen om medicijnafgevende deeltjes door een spuit te persen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
